
Last month, Ben and Sara Brumfield hosted a webinar to discuss metadata creation in FromThePage. The presentation, linked below in a video and embedded as slides, presents a walkthrough of metadata creation. This was one of FromThePage's most-attended webinars, and it was exciting to have so many people join. You can sign up for future webinars here.
Watch the recording of the presentation below:
Read through Ben and Sara's presentation:

You may have heard of FromThePage for crowdsourced transcription projects, but over the last couple of years we’ve expanded to support a lot of different types of materials and tasks.
A caveat up front -- we realize transcripts are a type of metadata, but we’re going to be talking about metadata and transcripts as if they are two totally different things. We know they aren’t.
Sara and I run a platform for crowdsourcing manuscript transcription and OCR correction called FromThePage. There’s a number of different crowdsourcing tasks out there, we really focus on crowdsourcing around archival documents and special collections, specifically textual records. But we think that the lessons we’ve learned applied to other kinds of crowdsourcing tasks like georectifying maps and photo identification.

In brief, our platform allows people to see an image of a page and to transcribe the text from that page. We try to keep things as simple as possible for the users, because frankly, transcribing text is hard enough.
We try to keep the interface as simple as possible. Originally we developed the software to support texts like this, which could be transcribed as plain text–or with mark-up–to support readers or people performing full-text search. In 2018, thanks to funding from the Council of State Archivists, we were able to support transcription of structured data like these… This produces a record about a single image, which may be part of a larger item.
Last year we also added support for ledgers and spreadsheets… These new tasks are driven by our collaborators at: State Archives, University libraries, memory institutions, and Public Libraries.
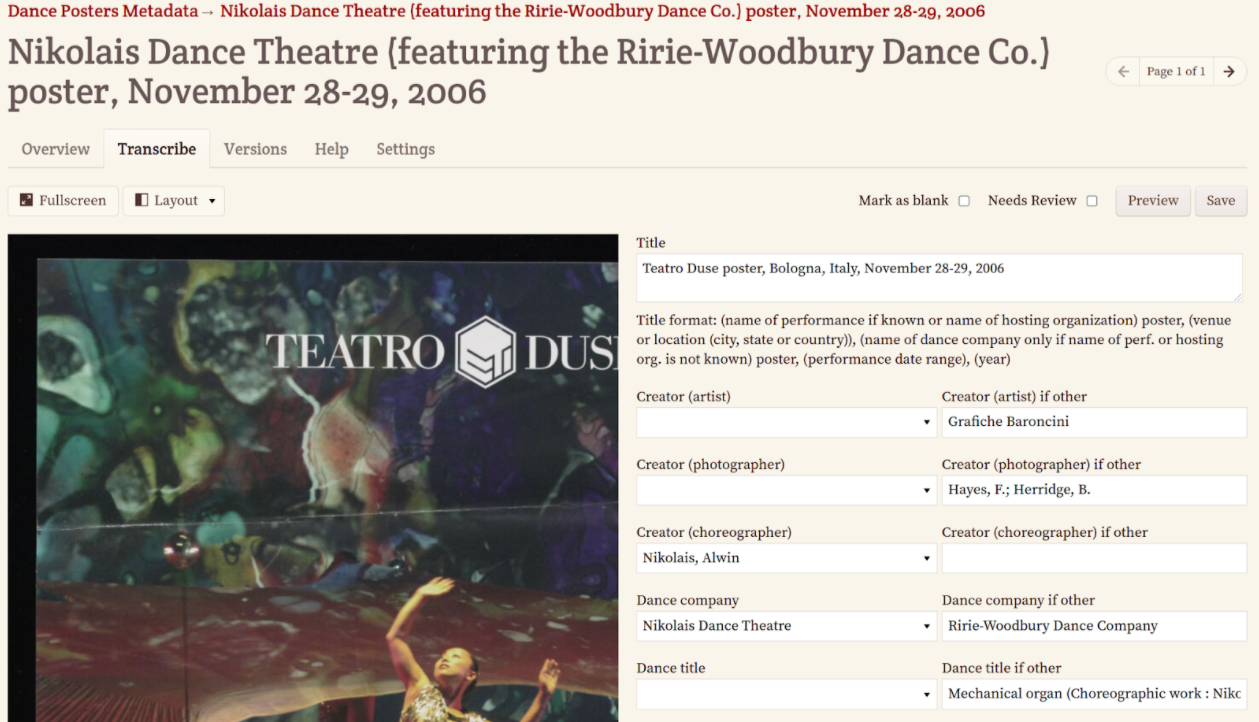
When you build software with empathy, you listen to the people who use your software but also watch how they are already using your software. So when we saw Ohio University run a staff project creating metadata for their dance poster collection, we recognized it was not exactly the style of project we were used to seeing and that we should pay attention.
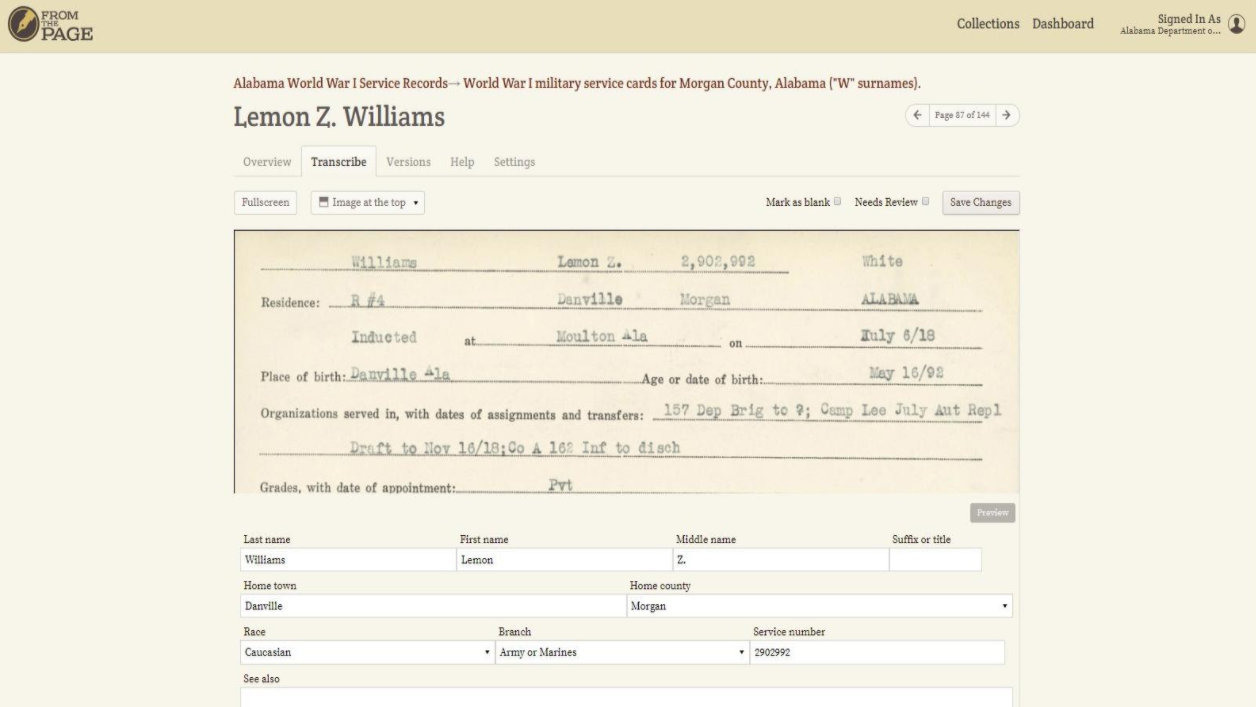
Looking back, we realized that our first field based project, the Alabama Department of Archives & History’s World War I Service Cards project, which indexed fields for folks from Alabama serving in WWI, might also be considered a metadata project. They created item level metadata for each card in the collection, and then reindexed the collection using that metadata.
What the dance posters and the index cards had in common, though, was that they were single images per form. One poster or one card to answer all the fields or questions. That meant that our field based transcription was good enough for item level metadata.
But what if you want to collect fields or answer questions about a 3 page letter? Or a 300 page book? Our model didn’t work. And since Meredith at ADAH knew she had an upcoming project -- the Civil War and Reconstruction Governors of Alabama -- where she wanted to do just that, it was at the top of her list when Alabama pulled together a syndicate of state archives to fund some new features in FromThePage.

In 2021 CoSA members -- specifically Alabama Archives, Florida State Archives, Indiana State Archives, Maryland State Archives, Missouri State Archives, North Carolina State Archives, Texas Library & Archives Foundation, Library of Virginia + GRIVA and many of their “friends” organizations which we love because it means these projects are not just pushed from the institutions, but “pulled” by the volunteers seeking meaningful ways to contribute -- funded, tested, and provided a ton of feedback for 4 new features in FromThePage:
- Spreadsheet Transcription
- Reviewer Role
- Metadata Creation
- Quality Control
This is the third of those features.
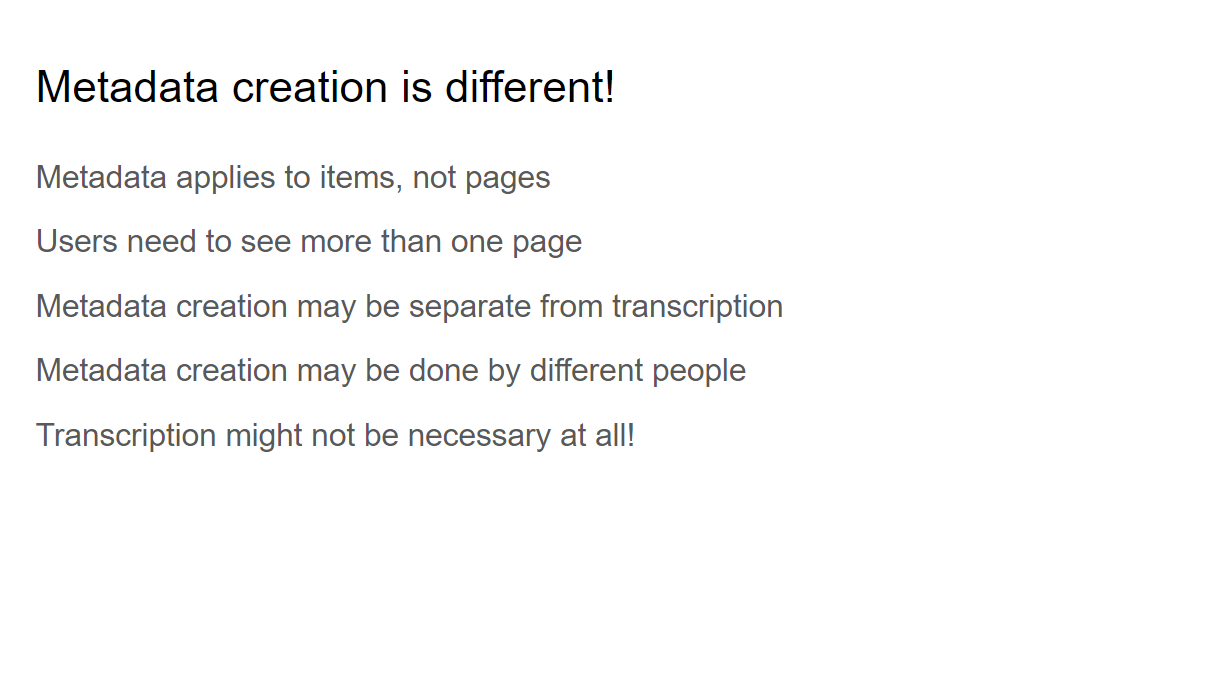
To create a solution for metadata, we had to think about how metadata creation is different from transcription:
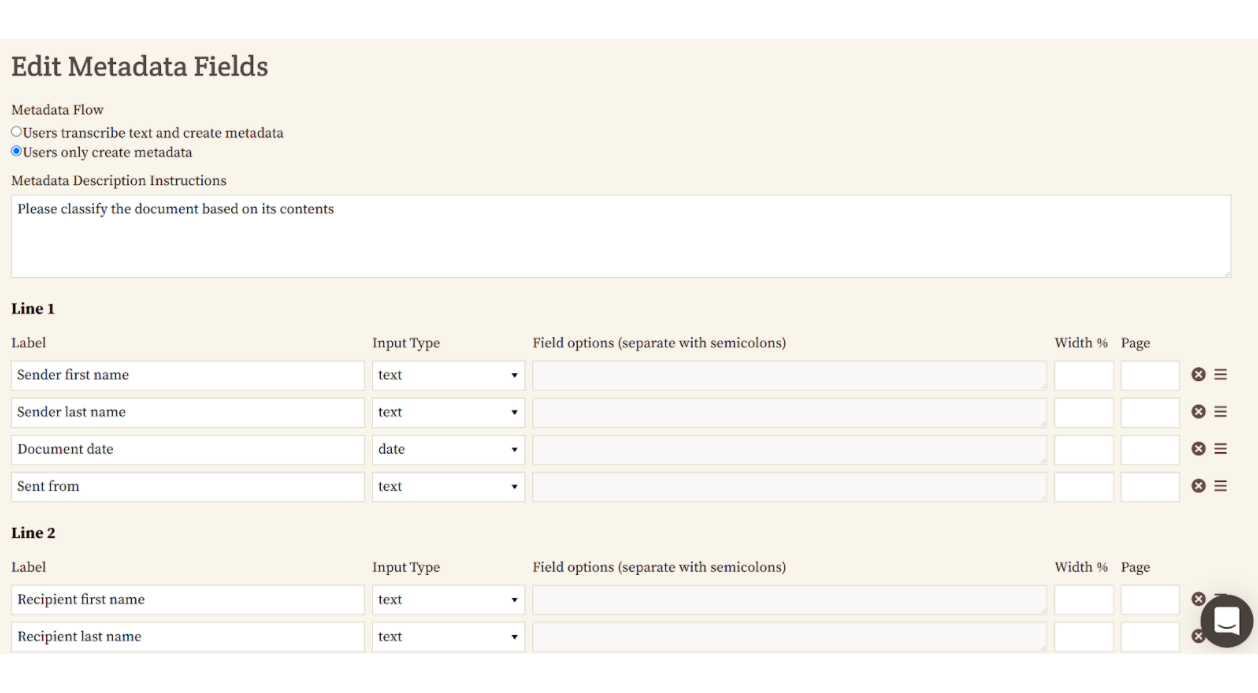
And here’s the configuration screen showing how we set up that same form.

So there’s a lot of ways to mix and match this feature with other features in FromThePage to get different kinds of projects. These all create metadata.

Let’s take a moment to talk about the other half of the configuration -- what you bring into the system for these projects. FromThePage projects require images, but those images can be zip files full of images; we can pull them out of PDFs; you can import items from contentDM or any system that supports IIIF and we’ll reference those images. You can optionally pull in text to support your metadata creation -- and text correction -- from OCR files, text files, the text layer on a PDF, or by creating the transcription on FromThePage first. If you’re doing a metadata revision or a metadata translation project, you’ll want to pull in your existing metadata. That can be done via a spreadsheet or from contentDM or a IIIF manifest.
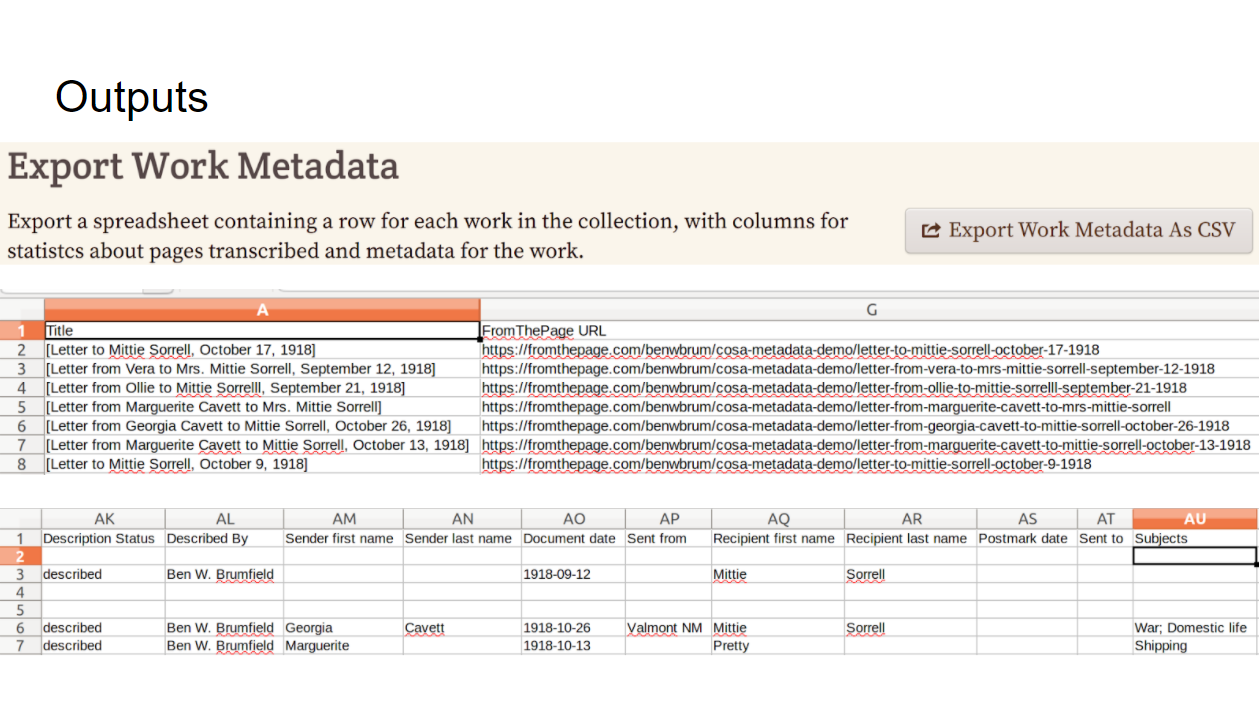
Currently, what we support is being able to pull out any spreadsheet with a row per item and columns that tell you what the item came from and what metadata was contributed by your collaborators.

I’d say these are our “hoped for” outcomes with this project.

Technology makes so many things possible, but it also takes courage and creativity to try new things and steer your organization into the future.
We’re excited about the possibilities here. Like this quote Bethany found says, users of metadata are diverse and we hope this is a small step to help you meet them where they are. We’re looking forward to what you do with this.
What will we all find out?
What can we do to make this better -- for volunteers, for staff, for you?