
This is a transcript of the talk I gave at Digital Frontiers 2012.
Abstract: One of the ironies of the Internet age is that traditional standards for accessibility have changed radically. Intelligent members of the public refer to undigitized manuscripts held in a research library as "locked away", even though anyone may study the well-cataloged, well-preserved material in the library's reading room. By the standard of 1992, institutionally-held manuscripts are far more accessible to researchers than uncatalogued materials in private collections -- especially when the term "private collections" includes over-stuffed suburban filing cabinets or unopened boxes inherited from the family archivist. In 2012, the democratization of digitization technology may favor informal collections over institutional ones, privileging online access over quality, completeness, preservation and professionalism.
Will the "cult of the amateur" destroy scholarly and archival standards? Will crowdsourcing unlock a vast, previously invisible archive of material scattered among the public for analysis by scholars? How can we influence the headlong rush to digitize through education and software design? This presentation will discuss the possibilities and challenges of mass digitization for amateurs, traditional scholars, libraries and archives, with a focus on handwritten documents.

My presentation is on bilateral digitzation: digitization done by institutions and by individuals outside of institutions and the wall that's sort of in between institutions and individuals.

In 1823, a young man named Jeremiah White Graves moved to Pittsylvania County, Virginia and started working as a clerk in a country store. Also that year he started recording a diary and journal of his experiences. He maintained this diary for the next fifty-five years, so it covers his experience -- his rise to become a relatively prominent landowner, tobacco farmer, and slaveholder. It covers the Civil War, it covers Reconstruction and the aftermath. (This is an entry covering Lee's surrender.)

In addition to the diary, he kept account books that give you details of plantation life that range from -- that you wouldn't otherwise see in the diaries. So for example, this is his daughter Fanny,

And this is a list of every single article of clothing that she took with her when she went off to a boarding school for a semester.

Perhaps more interesting, this is a memorandum of cash payments that he made to certain of his enslaved laborers for work on their customary holidays -- another sort of interesting factor. I got interested in this because I'm interested in the property that he lived in. The house that he built is now in my family, and I was doing some research on this. Since these account books include details of construction of the house, I spent a lot of time looking for these books. I've been looking for them for about the last ten years. I got in contact with some of the descendants of Jeremiah White Graves and found out through them that one of their ancestors had donated the diaries to the Alderman Library at the University of Virginia. I looked into getting them digitized and tried to get some collaboration [going] with some of the descendants, and one of them in particular, Alan Williams, was extremely helpful to me. But this was his reaction:

Okay. So we have diaries that are put in a library -- I believe one of the top research libraries in the country -- and they are behind a wall. They are locked away from him.

So let's talk about walls. From his perspective, the fact that these diaries--these family manuscripts of his--are in the Alderman Library means:
- They're professionally conserved -- great!
- They're publicly accessible, so anyone can walk in and look at them in the Reading Room.
- They're cataloged, which would not be the case if they'd still been sitting in his family.
- On the down side, they're a thousand miles away: they're in Virginia, he's in Florida, I'm in Texas. We all want to look at these, but it's awfully hard for people to get there if we don't have research budgets.
- We have to deal with reading room restrictions if we actually get there.
- Once we work on getting things digitized we have these permission-to-publish that we need to deal with, which have some moral challenges for someone from whose family these diaries came from.
- And we have the scanning fees: the cost of getting them scanned by the excellent digitization department at the Alderman Library is a thousand dollars. Which is not unreasonable, but it's still pretty costly.

So here's a wall--a real, physical wall--between this institution and the public. How do we get through walls? Everyone here is familiar with digitization and collaboration. This is how we share things nowadays. It's how we've been sharing things for the last fifteen years, in fact. But, at least fifteen years ago, when we got started doing digitization, we had shallow digitization.

The prevalent practice in institutions was "scan-and-dump": make some scans, put them in a repository online.
One of the problems with that is that you have very limited metadata. The metadata is usually institutionally-oriented. No transcripts, in particular -- nobody has time for this. And quite often, they're in software platforms that are not crawlable by search engines.

Now meanwhile, amateurs are digitizing things, and they're doing something that's actually even worse! They are producing full transcripts, but they're not attaching them to any facsimiles. They're not including any provenance information or information about where their sources came from. Their editorial decisions about expanding abbreviations or any other sorts of modernizations or things like that -- they're invisible; none of those are documented.
Worst of all, however, is that the way that these things are propagated through the Internet is through cut-and-paste: so quite often from a website to a newsgroup to emails, you can't even find the original person who typed up whatever the source material was.

So how do we get to deep digitization and solve both of these problems?
The challenges to institutions, in my opinion, come down to funding and manpower. As we just mentioned, generally archives don't have a staff of people ready to produce documentary editions and put them online.
Outside institutions, the big challenge is standards; it is expertise. You've got manpower, you've got willingness, but you've got a lot of trouble making things work using the sorts of methodologies that have come out of the scholarly world and have been developed over the last hundred years.
So how do we fix these challenges?

One possible solution for institutions is crowdsourcing. We've talked about this this morning; we don't need to go into detail about what crowdsourcing is, but I'd like to talk a little bit about who participates in crowdsourcing projects and what kinds of things they can do and what this says about [crowdsourcing projects]. I've got three examples here. OldWeather.org is a project from GalaxyZoo, the Zooniverse/Citizen Science Alliance. The Zenas Matthews Diary was something that I collaborated with the Southwestern University Smith Library Special Collections on. And the Harry Ransom Center's Manuscript Fragments Project.
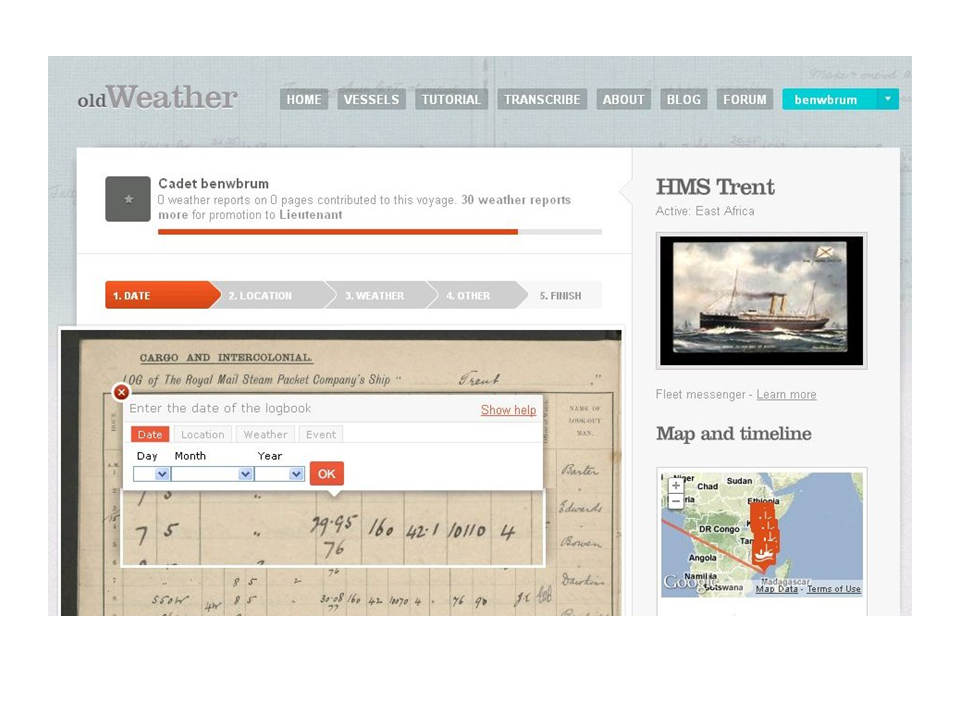
Okay, in Old Weather there are Royal Navy logbooks that record temperature measurements every four hours: the midshipman of the watch would come out on deck and record barometric pressure, wind speed, wind direction and temperature. This is of incredible importance for climate scientists because you cannot point a weather satellite at the south Pacific in 1916. The problem is that it's all handwritten and you need humans to transcribe this.
They launched this project three years ago, I believe, and they're done. They've transcribed all the Royal Navy logs from the period essentially around World War I -- all in triplicate. So blind triple keying every record. And the results are pretty impressive.

Each individual volunteer's transcripts tend to be about 97% accurate. For every thousand logbook entries, three entries are going to be wrong because of volunteer error. But this compares pretty favorably with the ten that are actually honestly illegible, or indeed the three that are the result of the midshipman of the watch confusing north and south.

So in terms of participation, OldWeather has gotten transcribed more than 1.6 million weather observations--again, all triple-keyed--through the efforts of sixteen thousand volunteers who've been transcribing pages from a million pages of logs.
So what this means is that you have a mean contribution of one hundred transcriptions per user. But that statistic is worthless!
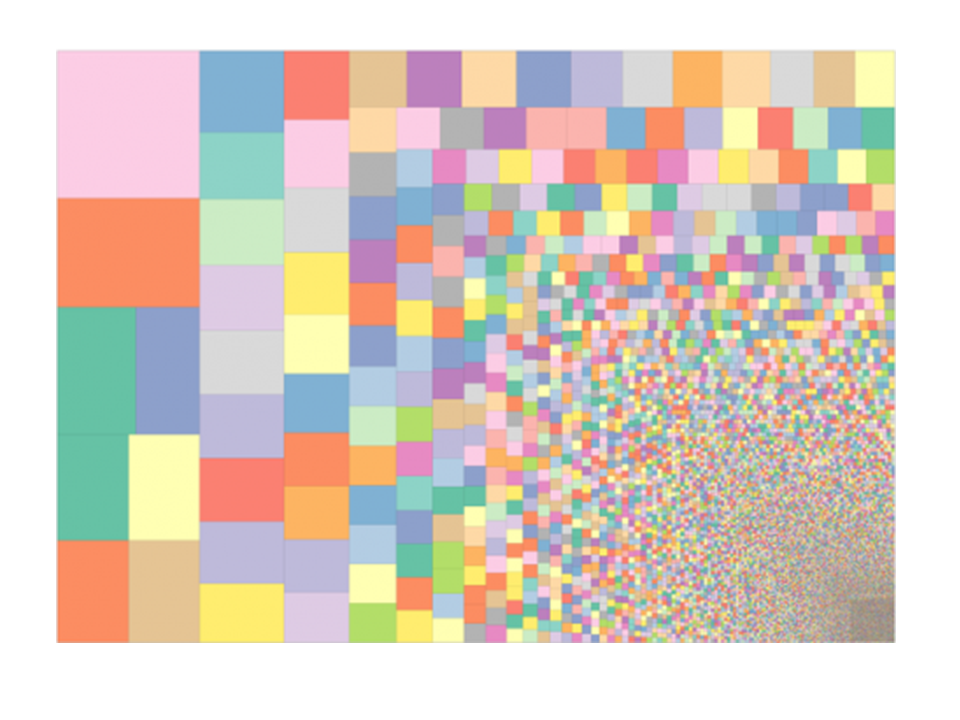
Because you don't have individual volunteers transcribing one hundred things apiece. You don't have an even distribution. This is a color map of contributions per user. Each user has a square. The size of the square represents the quantity of records that they transcribed. And what you can see here is that of those 1.6 million records, fully a tenth (in the left-hand column) were transcribed by only ten users.

So we see this in other projects. This is a power-law distribution in which most of the contributions are made by a hand-full of "well-informed enthusiasts". I've talked elsewhere about how this is true in small projects as well. What I'd like to talk about here is some of the implications.

One of the implications is that very small projects can work: This is the Zenas Matthews Diaries that were transcribed on FromThePage by one single volunteer -- one well-informed enthusiast in fourteen days.

Before we had announced the project publicly he found it, transcribed the entire 43-page diary from the Mexican-American War of a Texas volunteer, went back and made two hundred and fifty revisions to those pages, and added two dozen footnotes.

This also has implications for the kinds of tasks you can ask volunteers to do. This is the Harry Ransom Center Manuscript Fragments Project in which the Ransom Center has a number of fragments of medieval manuscripts that were later used in binding for later works, and they're asking people to identify them so that perhaps they can reassemble them.
So here's a posting on Flickr. They're saying, "Please identify this in the comments thread."
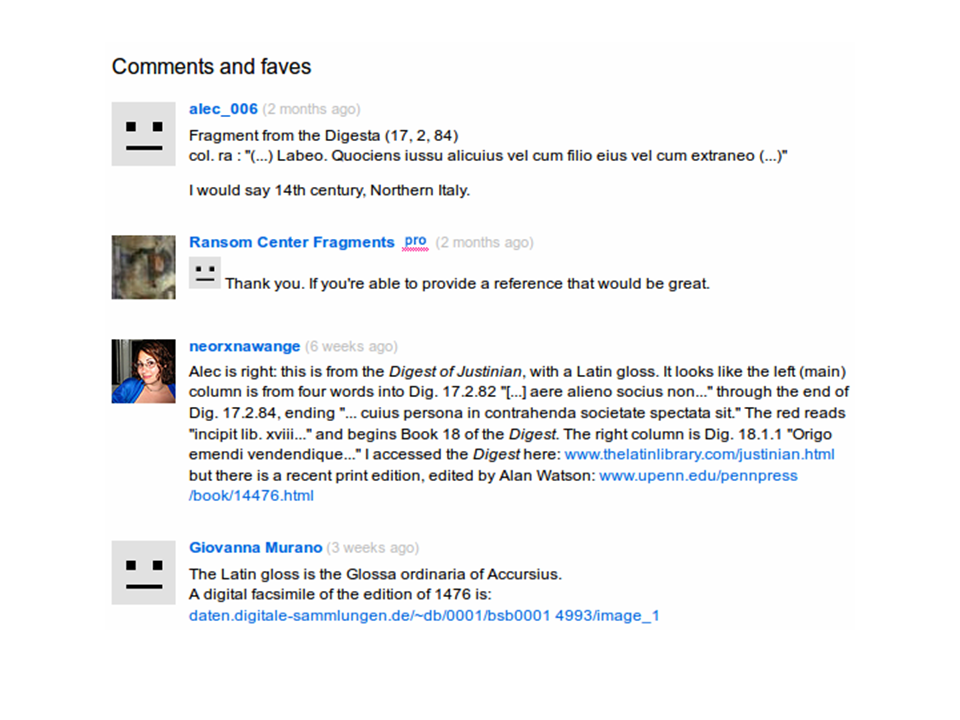
And look: we've got people volunteering transcriptions of exactly what this is: identifying, "Hey, this is the Digest of Justinian, oh, and this is where you can go find this."
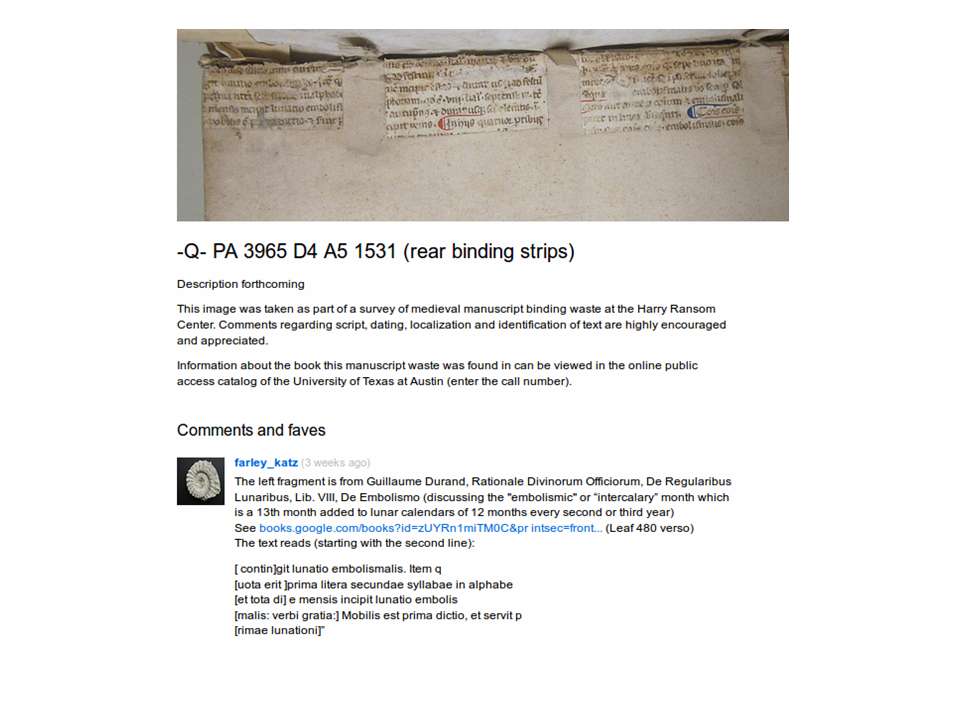
This is true even for smaller, more difficult fragments. Here we have one user going through and identifying just the left hand fragment of this chunk of manuscript that was used for binding.

So crowdsourcing and deep digitization has a virtuous cycle in my opinion. You go through and you try to engage volunteers to come do this kind of work. That generates deep digitization which means that these resources are findable. And because they're findable, you can find more volunteers.

I've had this happen recently with a personal project, transcribing my great-great grandmother's diary. The current top volunteer on this is a man named Nat Wooding. He's a retired data analyst from Halifax County, Virginia. He's transcribed a hundred pages and indexed them in six months. He has no relationship whatsoever to the diarist.
But his great uncle was the postman who's mentioned in the diaries, and once we had a few pages worth of transcripts done, he went online and did a vanity search for "Nat Wooding", found the postman--also named Nat Wooding--discovered that that was his great uncle and has become a volunteer.

Here's the example: this is just a scan/facsimile. Google can't read this.

Google can read this, and find Nat Wooding.

Now I'd like to turn to non-institutional digitization. I said "bilateral" -- this means, what happens when the public initiates digitization efforts. What are the challenges--I mentioned standards--how can we fix those. And why is this important?

Well, there is this--what I call the Invisible Archive, of privately held materials throughout the country and indeed the world. And most of it is not held by private collectors that are wealthy, like private art collectors. They are someone's great aunt who has things stashed away in filing cabinets in her basement. Or worse, they are the heirs of that great aunt, who aren't interested and have them stuck in boxes in their attic. We have primary sources here of non-notable subjects, that are very hard to study because you can't get at them.
But this is a problem that has been solved, outside of manuscripts. It's been solved with photographs. It's been solved by Flickr. Nowadays, if you want to find photographs of African-American girls from the 1960s on tricycles, you can find them on Flickr. Twenty years ago, this was something that was irretrievable. So Flickr is a good example, and I'd like to use it to describe how we might be able to apply it to other fields.

So, in terms of solving the standards problem, amateur digitization has a bad, bad reputation, as you can see here.

And much of that bad reputation is deserved, and isn't specific to digitization. This has been a problem with print editions in the past, it is a problem online now. Frankly, scholars don't trust the materials because they're not up to standard.

How do we solve this? Collaboration: we'd like to see more participation from people who are scholars, who are trained archivists, who are trained librarians to participate in some of these projects.

One of the ones I'm working with [is] digitizing these registers from the Reformation up to the present. We're building this generalizable, open-source, crowdsourced transcription tool and indexing tool for structured data. We'd love to find archivists to tell us what to do, what not to do, and to collaborate with us on this.

Another solution is community. You don't go on Flickr just to share your photos; you go on Flickr to learn to become a better photographer. And I think that creating platforms and creating communities that can come up with these standards and enforce them among themselves can really help.

The same thing is true with software platforms, if they actually prompt users and say: "when you're uploading this image, tell us about the provenance." "Maybe you might want to scan the frontispieces." "Maybe you'd like to tell us the history of ownership."

Those are the things that I think might get us there. I've just hit my time limit, I think, so thanks a lot!
Ben Brumfield is a family historian and independent software engineer. For the last seven years he has been developing FromThePage, an open source manuscript transcription tool in use by libraries, museums, and family historians. He is currently working with FreeUKGen to create an open source system for indexing images and transcribing structured, hand-written material. Contact Ben at benwbrum@gmail.com.
Though metadata and deep digitization can be attained by using already-available mediums like Flickr, it would still be best if the quality of the digitized material be in peak condition. A way is to suggest a uniform program to use for post-processing so that the quality will stay consistent. The only problem would be choosing which program could best satisfy the need of different users.
Ruby Badcoe