
This is my fourth and final post about the iDigBio Augmenting OCR Hackathon. Prior posts covered the hackathon itself, my presentation on preliminary results, and my results improving the OCR on entomology specimens. The other participants are slowly adding their results to the hackathon wiki, which I recommend checking back with (their efforts were much more impressive than mine).
 |
| Clearly handwritten: T=8, N=78% from terse and noisy OCR files |
Let's say you have scanned a large number of cards and want to convert them from pixels into data. The cards--which may be bibliography cards, crime reports, or (in this case) labels for lichen specimens--have these important attributes:
- They contain structured data (e.g. title of book, author, call number, etc. for bibliographies) you want to extract, and
- They were part of a living database built over decades, so some cards are printed, some typewritten, some handwritten, and some with a mix of handwriting and type.
The structured aspect of the data makes it quite easy to build a web form that asks humans to transcribe what they see on the card images. It also allows for sophisticated techniques for parsing and cleaning OCR (which was the point of the hackathon). The actual keying-in of the images is time consuming and expensive, however, so you don't want to waste human effort on cards which could be processed via OCR.
Since OCR doesn't work on handwriting, how do you know which images to route to the humans and which to process algorithmically? It's simple: any images that contain handwriting should go to the humans. Detecting the handwriting on the images is unfortunately not so simple.
I adopted a quick-and-dirty approach for the hackathon: if OCR of handwriting produces gibberish, why send all the images through a simple pass of OCR and look in the resulting text files for representative gibberish? In my preliminary work, I pulled 1% of our sample dataset (all cards ending with "11") and classified them three ways:
- Visual inspection of the text files produced by an ABBY OCR engine,
- Visual inspection of the text files produced by the Tesseract OCR engine, and
- Looking at the actual images themselves.
To my surprise, I was only able to correctly classify cards from OCR output 80% of the time -- a disappointing finding, since any program I produced to identify handwriting from OCR output could only be less accurate. More interesting was the difference between the kinds of files that ABBY and Tesseract produced. Tesseract produced a lot more gibberish in general--including on card images that were entirely printed. ABBY, on the other hand, scrubbed a lot of gibberish out of its results, including that which might be produced when it encountered handwriting.
This suggested an approach: look at both the "terse" results from ABBY and the "noisy" results from Tesseract to see if I could improve my classification rate.
 |
| Easily classified as type-only, despite (non-characteristic) gibberish: T=0,N=0 from terse and noisy OCR files. |
But what does it mean to "look" at a file? I wrote a program to loop through each line of an OCR file and check for the kind of gibberish characteristic of OCR and handwriting. Inspecting the files reveals some common gibberish patterns, which we can sum up as regular expressions:
GARBAGE_REGEXEN = { 'Four Dots' => /..../, 'Five Non-Alphanumerics' =>/WWWWW/, 'Isolated Euro Sign' =>/S€D/, 'Double "Low-Nine" Quotes' =>/„/, 'Anomalous Pound Sign' =>/£D/, 'Caret' =>/^/, 'Guillemets' =>/[«»]/, 'Double Slashes and Pipes' =>/(\/)|(/\)|([/\]|||[/\])/, 'Bizarre Capitalization' =>/([A-Z][A-Z][a-z][a-z])|([a-z][a-z][A-Z][A-Z])|([A-LN-Z][a-z][A-Z])/, 'Mixed Alphanumerics' =>/(w[^sw.-]w).*(w[^sw]w)/ }
However, some of these expressions match non-handwriting features like geographic coordinates or bar codes. Handling these requires a white list of regular expressions for gibberish we know not to be handwriting:
WHITELIST_REGEXEN = { 'Four Caps' =>/[A-Z]{4,}/, 'Date' =>/Date/, 'Likely year' =>/1[98]dd|2[01]dd/, 'N.S.F.' =>/N.S.F.|Fund/, 'Lat Lon' =>/Lat|Lon/, 'Old style Coordinates' =>/dd°s?dd['’]s?[NW]/, 'Old style Minutes' =>/dd['’]s?[NW]/, 'Decimal Coordinates' =>/dd°s?[NW]/, 'Distances' =>/d?d(.d+)?s?[mkf]/, 'Caret within heading' =>/[NEWS]^s/, 'Likely Barcode' =>/[l1|]{5,}/, 'Blank Line' =>/^s+$/, 'Guillemets as bad E' =>/d«t|pav«aont/ }
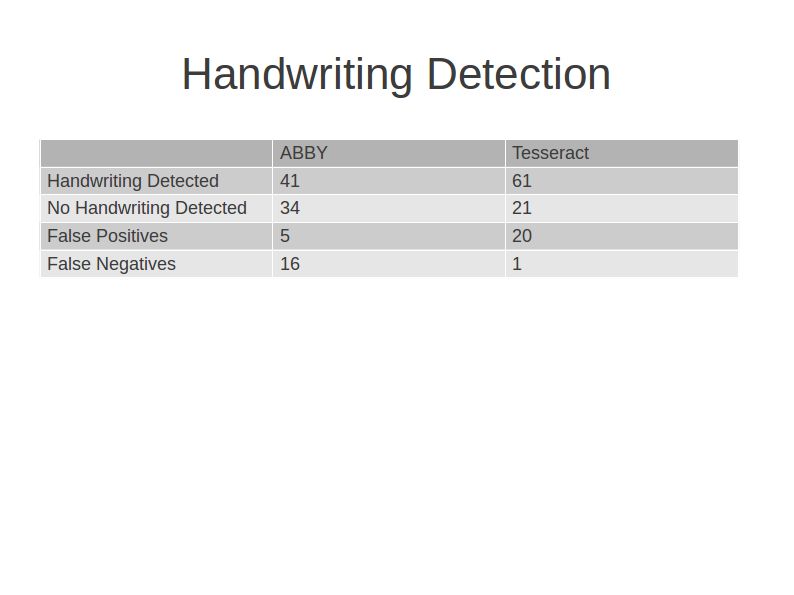
With these on hand, we can calculate a score for each file based on the number of occurrences of gibberish we find per line. That score can then be compared against a threshold to determine whether a file contains handwriting. Due to the noisiness of the Tesseract files, I found it most useful to calculate their score N as a percentage of non-blank lines, while the score for the terse files T worked best as a simple count of gibberish matches.
| Threshold | Correct | False Positives |
False Negatives |
|---|---|---|---|
| T > 1 and N > 20% | 82% | 10 of 45 | 8 of 60 |
| T > 0 and N > 20% | 84% | 13 of 45 | 4 of 60 |
| T > 1 | 79% | 10 of 45 | 12 of 60 |
| N > 20% | 75% | 8 of 45 | 18 of 60 |
| N > 10% | 81% | 14 of 45 | 6 of 60 |
One interesting thing about this approach is that adjusting the thresholds lets us tune the classifications for resources and desired quality. If our humans doing data entry are particularly expensive or impatient, raising the thresholds should ensure that they are only very rarely sent typed text. On the other hand, lowering the thresholds would increase the human workload while improving quality of the resulting text.
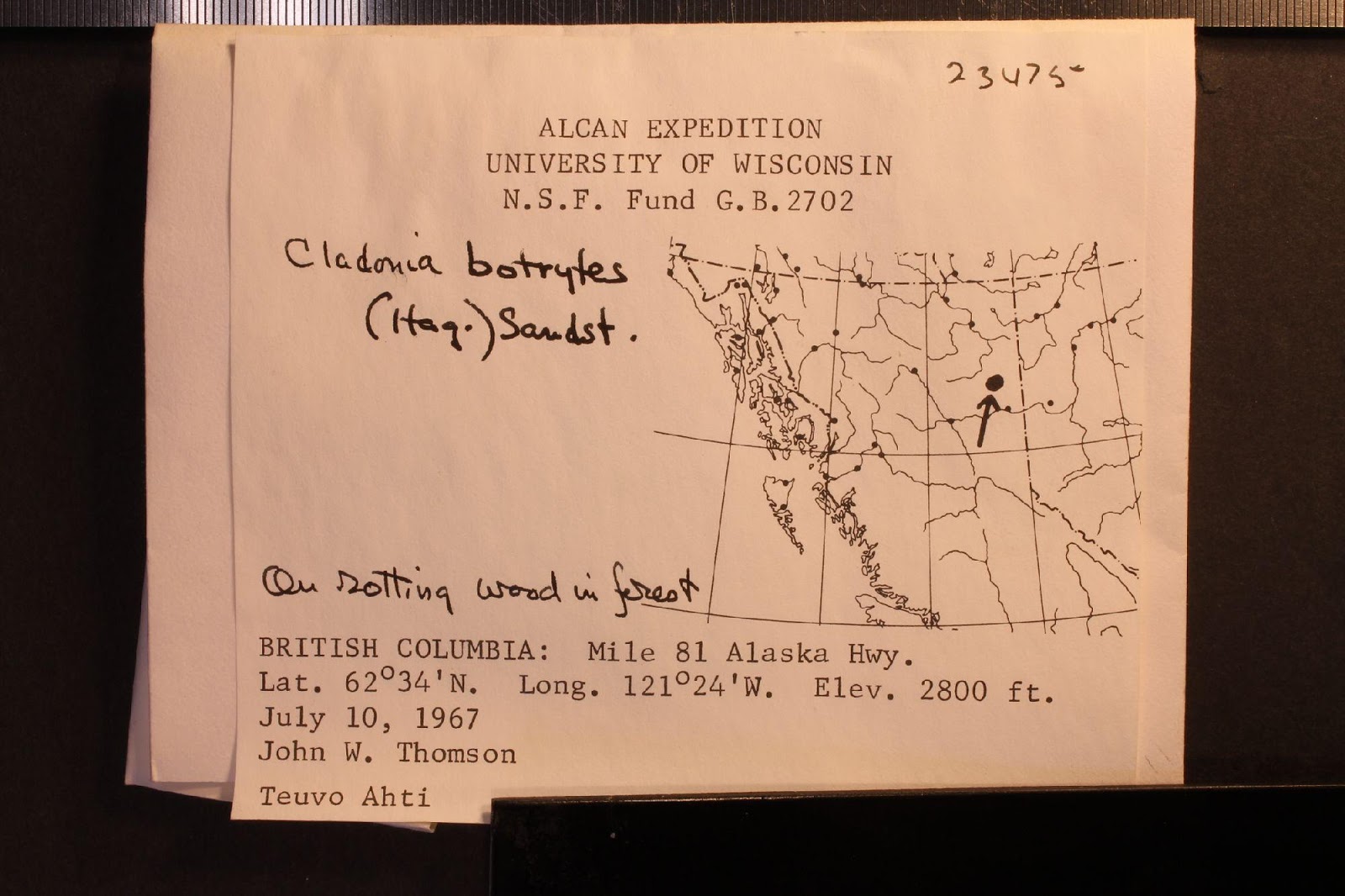 |
| One of the false negatives: T=0, N=10% from parsing terse and noisy text files. |
I'm really pleased with this result. The combined classifications are slightly better than I was able to accomplish by looking at the OCR myself. The experience of a volunteer presented with 56 images containing handwriting and 13 which don't may necessitate a "send to OCR" button in the user interface, but must be less frustrating than the unclassified ratio of 45 in 105 from the sample set. With a different distribution of handwriting-to-type in the dataset, the process might be very useful for extracting rare typed material from a mostly-handwritten set, or vice versa.
All of the datasets, code, and scored CSV files are in iDigBio AOCR Hackathon's HandwritingDetection reposity on GitHub..
This comment has been removed by a blog administrator.
Hi, im having old and valuable scanned as PFD & jpg which are hand written documents by different teams, so the hand written is of not the same pattern, so im looking for software which can do the job of extracting hand written text into data and store it in local database. Further to your research do you prefer to go with linux softwares or android and how much % failure this will have being its going to process documents which are not legible as well. Seeking your valuable suggestion.