
Sonya Coleman is Digital Engagement + Social Media Coordinator at the Library of Virginia.
First, tell us about your documents.
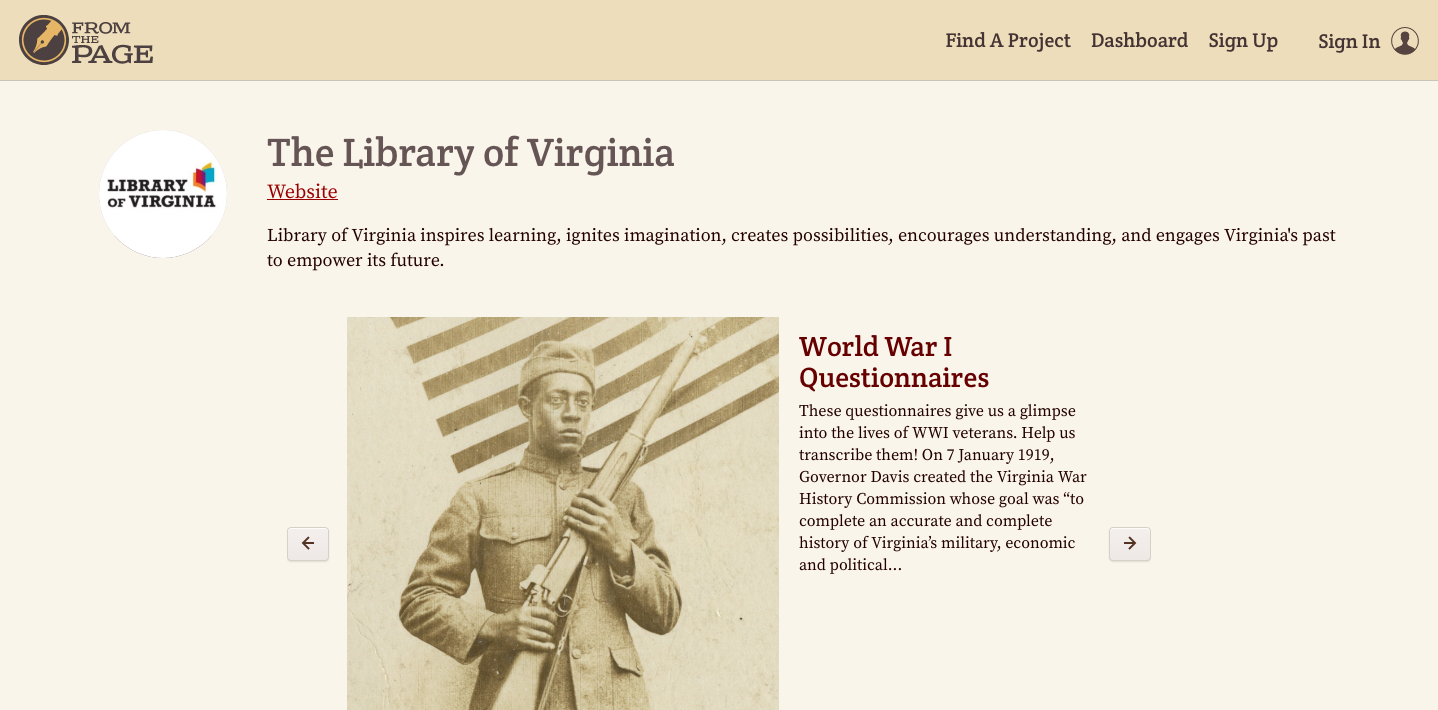
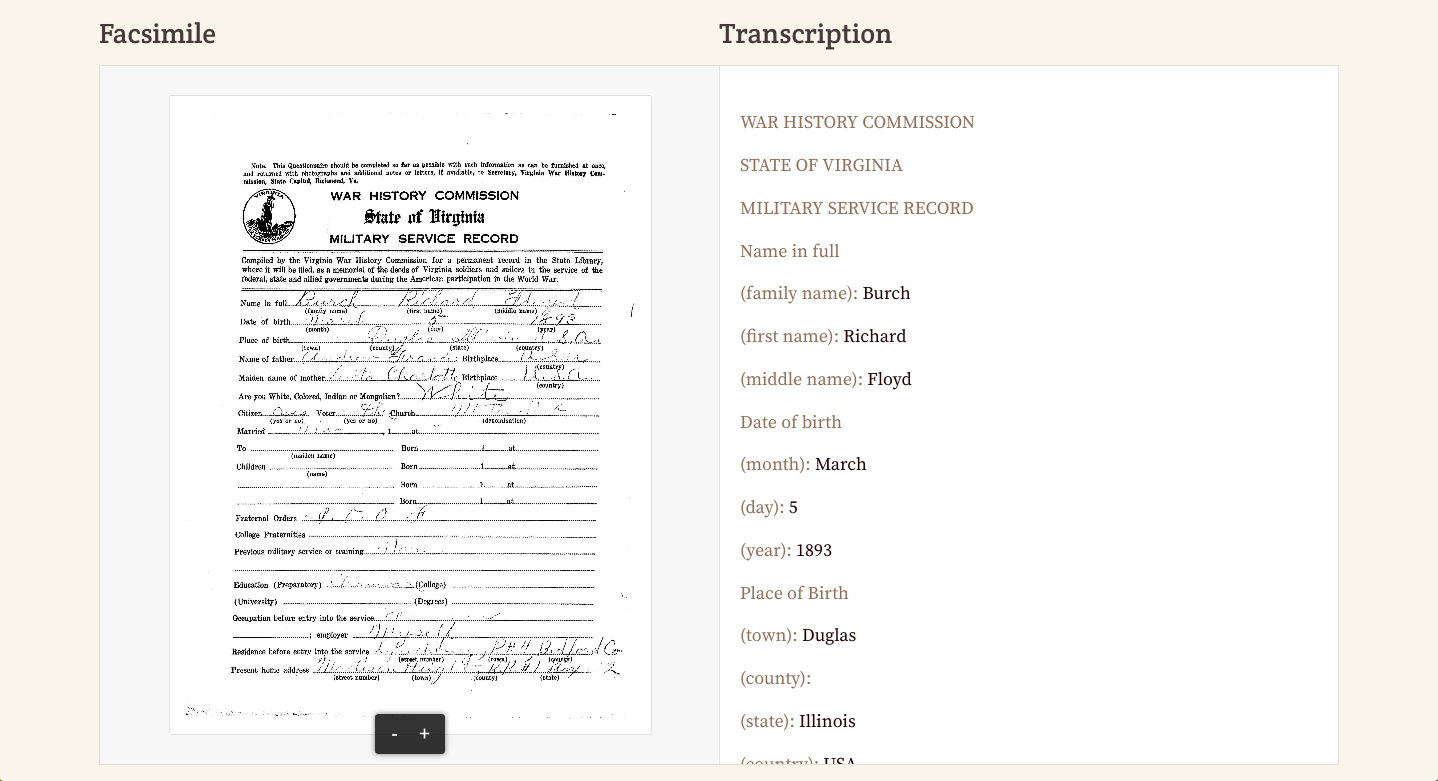
The Library of Virginia houses over 124 million archival items, including state and local records, personal papers, microfilm, maps, photographs, and more. Many of these documents contain structured data, such as the World War I Questionnaires. These are four-page forms completed by returning soldiers or their surviving kin following the Great War. The 14,900 questionnaires were gathered from 1919-1921 by the Virginia War History Commission. It covers the veteran’s personal information and war record in detail, with some open-ended questions about how the war affected their physical, mental, and spiritual states. Photographs were also requested, though not always included with the questionnaire. The questionnaires had already been digitized and indexed for a database, but we wanted to fully transcribe them to honor the 100-year anniversary of WWI. Full information about the collection can be found here.
What are your goals for the project?
The Library’s crowdsourced transcription site Making History: Transcribe has been running for four and a half years with nearly 70,000 pages transcribed. We’ve had great success transcribing manuscript materials, but have run into real difficulty when we come across forms. We don’t want to ask our volunteers to retype the form text each time, but capturing only the answers is equally troublesome since it doesn’t fully capture the meaning or text. The structured transcription developments on From the Page offered a chance to transcribe forms without losing the field text or asking our users to duplicate it for each page. Our goal is to capture all the data from the WWI Questionnaires, as well as other field-based documents, in order to increase access and searchability. Crowdsourcing has been immensely popular with our users, and we want to build on this type of interaction with ongoing projects and a variety of ways to contribute.
How are you recruiting or finding volunteers/collaborators?
We have a pretty steady stream of new and returning volunteers from the Making History: Transcribe project. HandsOn Greater Richmond provides volunteer opportunities throughout the metro area, and has been instrumental in connecting with volunteers. We host two transcribe-a-thons per month through their Volunteer Leader Program, bringing in twenty volunteers at a time to our computer classroom. We start each event by providing context for our crowdsourcing projects and demoing the sites, Transcribe and FromThePage. These events provide both training for those who wish to transcribe independently and community for those who volunteer with us for months or even years. Volunteer hours are awarded for school, organizational, and community service needs. Many of our volunteers are entirely remote and may never visit the Library of Virginia in Richmond, but they use our online resources, understand the added value of full-text, and are deeply engaged with the stories these documents tell. Social media helps spread the word about our crowdsourcing events and projects. We also conduct outreach to genealogical societies, high schools, lifelong learners and other groups interested in our crowdsourcing projects.
Can you share your experience using FromThePage?
 Our experience using From the Page has been very positive. We chose an absolute beast of a form to attempt as our first structured data transcription set: 118 lines, some with 3 or 4 fields per line, with a total of over 200 fields. Ben and Sara worked with our team at the Library to upload all the images, make the form properly, and even incorporate new features we needed.
Our experience using From the Page has been very positive. We chose an absolute beast of a form to attempt as our first structured data transcription set: 118 lines, some with 3 or 4 fields per line, with a total of over 200 fields. Ben and Sara worked with our team at the Library to upload all the images, make the form properly, and even incorporate new features we needed.
Our users have responded really well to the project. Many younger users, who may have less experience reading old handwriting, gravitate toward the more modern WWI Questionnaires. They easily understand the user interface of FromThePage. The only notable frustration occurs when the original veteran or family member did not fill out the questionnaire in a way that corresponds to the fields, but that’s human behavior!
You contributed code to FromThePage to make this project happen. Can you tell us a bit how that worked?
We spent a bit of time evaluating FromThePage’s field-based transcriptions and had a meeting to talk about what things we liked, and what things we thought could be improved to better meet our needs. Thanks to FromThePage being open source software, our Web Developer, Austin, was able to propose fixing some of the niggles we had.
Although he had a few years of programming experience and used other MVC frameworks, Austin realized he was going to have to spend some time learning Ruby on Rails before being able to start working on new features. Ruby on Rails Tutorial by Michael Hartl was a great way to get up and running. Soon after, Austin was able to start writing code for our most-needed features.
The documents we were transcribing were at least four pages, with 219 fields. At the time, FromThePage displayed all transcription fields for a document, no matter what page you were on. This create a problem where if you were on page two of a document, you’d have to scroll down to get to the transcription fields that were relevant to page two. Because the people transcribing documents are volunteers, it’s important for this experience to be as frictionless as possible. They’re devoting their time to us, and we don’t want to waste it or worse, frustrate them into giving up.
The solution we wrote involved adding a new section for each of the fields in the back-end system called Page Number that allows the creator to input the document page they want that particular field to be displayed on. Then on the transcribing page, if a user is on page 2 of the document they’ll only see fields that have a ‘2’ in the Page Number section in the back-end. No more having to scroll past transcription fields that aren’t relevant to the current document page!
 At this point we weren’t sure whether we were going to use our own local fork of FromThePage on one of our pages, or try to merge this new Page Number feature into FromThePage.com. We submitted a pull request on Github to see if it would merge without any errors, and after a few attempts it finally passed all the automated tests. Austin then had a meeting with Ben and Sara to talk about the new feature, and why we needed it. Soon after the new feature was up on FromThePage.com!
At this point we weren’t sure whether we were going to use our own local fork of FromThePage on one of our pages, or try to merge this new Page Number feature into FromThePage.com. We submitted a pull request on Github to see if it would merge without any errors, and after a few attempts it finally passed all the automated tests. Austin then had a meeting with Ben and Sara to talk about the new feature, and why we needed it. Soon after the new feature was up on FromThePage.com!
We continued adding new features and submitting pull requests, and Ben and Sara were very helpful in evaluating our code and giving feedback. So far we’ve added the Page Number column to transcription fields and filtering of transcription fields by current document page, styling for field labels on the transcribe page to help with readability, added a new “label” type of transcription field that has no actual input box associated it, added a new “instruction” type of transcription field that shows to transcribers to help give them extra instructions, fixed a bug with capitalization of transcription field labels, and started initial work on adding unique IDs for exports that Ben has since taken over development of.
Although some of our features were specific to our use-case, we hope most of them can also be useful to other organizations working with field-based transcription projects. It was great that Ben and Sara were able to take the time to understand why we were creating the features we were, and that they were so accommodating in merging our code in with FromThePage.com!
Anything else you'd like to tell us?
We look forward to continuing to work with users and new technology, such as FromThePage, to improve our collections and generate new interactions. Thank you for working with us on all the quirks of these WWI questionnaires!
Sonya Coleman, Digital Engagement + Social Media
Austin Carr, Web Developer