
Last May 19, Sara Brumfield hosted a webinar to discuss ChatGPT for libraries and archives. The presentation, linked below in a video and embedded as slides, presents a breakdown of what ChatGPT is and how it affects libraries and archives. This was FromThePage's most-attended webinar, and it was exciting to have so many people join. You can sign up for future webinars here.
Watch the recording of the presentation below:
Read through Sara's adapted presentation:


I'm a techno-optimist, but also a realist.
I have a BA in CS, but I also have a degree in humanities.
I’ve been a digital humanities consultant for 7 years
My partner and I do a lot of projects around digital editions, IIIF, and we run FromThePage.
FromThePage is our crowdsourcing platform; we have about 100 institutions that run projects on it for transcription, metadata description, indexing, and photo identification. Because it’s a crowdsourcing platform, we think hard about the human and the technology. We write technology, we’re software engineers but we’re building a platform that humans, that people, often retirees, who are very passionate about history, about genealogy, about local history are partnering with institutions to turn digital images into searchable, accessible text.
So I try to bring that empathy that we apply to our software engineering to thinking about how ChatGPT and AI more broadly will affect all of us.
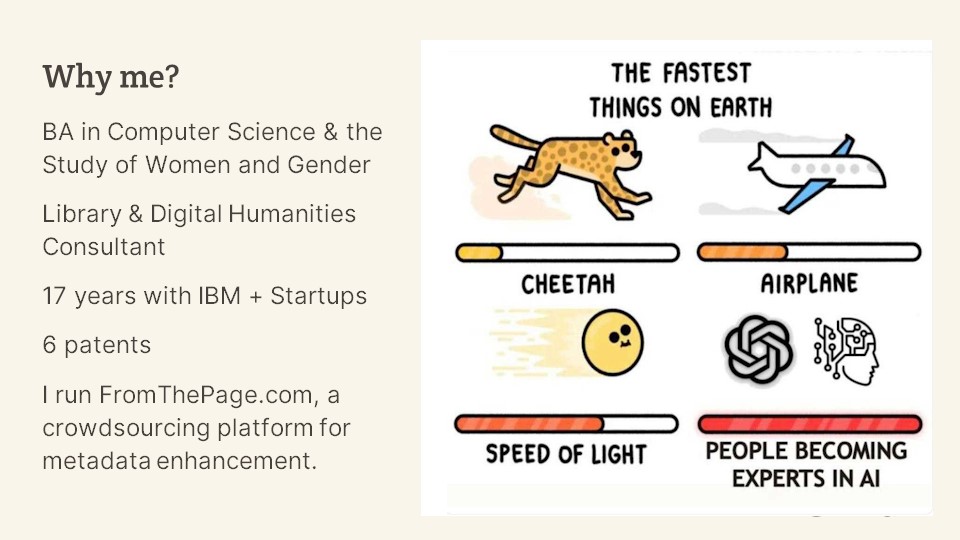
I love this cartoon on the right. I’m not an expert in AI. I took one class on it in college many years ago, but I do have a good technical grounding and since this has hit the zeitgeist I’ve been doing a lot of reading and a lot of thinking.
You don’t have to assume everything I say is 100% correct; I’d encourage you to do your own research and learn on your own. Part of the challenge is this field is changing so quickly that you can get out of date very quickly; and I’ll tell you when what I’m bringing to you is likely to change, and change quickly.

It is a big deal.
There’s a lot of whiz-bangery out there showing how amazingly smart ChatGPT is – it is & it isn’t.
There’s a lot of negative press talking about how sentient it is, or how it will seek power – It isn’t.
Or how it will put many of us who write words or programs out of jobs. It won’t, mostly, but it will make our jobs very different and more efficient.
A classic technology marketing technique is to use FEAR, UNCERTAINTY, and DOUBT to sell you ideas or products.
I’m hoping this presentation will give you a good basis for wading through all the information, for gut-checking what you read.
The thing to realize is that this field is moving *fast*. Things changed while I was writing this.
This presentation is going to generate more questions than it answers.
And it’s OK if you disagree with me, because what we need is civil discourse around the implications of this new technology.
But I think you should ask yourself whether there is a scenario in the future that DOESN’T involve AI. I don’t think there is, so we all have a responsibility to learn and think about how it works and what it means.

- Large Language Model
- trained on billions of words
- expensive to build
- Autocomplete on Steroids
- Generative AI
The basic model is you ask it a question, using human language. We call these questions “prompts” and ChatGPT returns with text. So that’s the core of the interaction. There’s 2 pieces here:
Chat – the interface where you put in a prompt and you get an answer; it’s a dialog, you can go back and forth and ChatGPT will remember a certain amount of the conversation that came before. “Can you tell me more” or “How are digital librarians different?” It’s a lot more efficient than doing a search and clicking on a series of web pages to answer a question.
The 2nd half is “GPT” – the current model behind the free ChatGPT is GPT-3.5, GPT-4 is available to folks who are subscribed to it. Those are the large language models that are behind this technology.
Exercise: Go sign up for ChatGPT and type something in. That will put you in the minority of folks who have actually tried ChatGPT.

It’s like a cocky teenager – It thinks it knows everything, but in reality, it only knows what it has already encountered in the world. In other words, what it’s been trained on. It can reason based on what it “knows” but it can’t generate knowledge.
Exercise for you: Play 20 questions with ChatGPT. I did this, with “bottle of champagne” as the “thing to guess”, and while ChatGPT understood the structure of the game – well – it didn’t have the context of knowing I like sparkling wine, or being able to ask about my house and knowing it’s contents, or knowing that my interests would make me likely to think of that.
Combining Knowledge bases & a LLM is where things are going to get really powerful. It’s not so much that it needs *more* knowledge, but that it needs something – a person, or a computer – to tell it “this is the knowledge you need to pay attention to for this problem you’re trying to solve.”

So let’s talk about where the knowledge ChatGPT has come from.
Even with these limitations, It’s really really good. It works. It’s really, really good at facts, because there are a lot of facts on the internet.

This is from a research paper published by OpenAI, the developer of ChatGPT.
So this the results of 2 of these models taking a number of standard tests in the US, and it did really well. I think the 6th one here is really interesting – it’s the uniform bar exam, what lawyers pass to be able to practice law in many states, and GPT-4 scored in the 90% percentile on this test.
I have a highschooler whose been taking AP classes; her environment science class that she took the test in 2 weeks ago – this model scores in the 90th percentile. One of the first things she did when we started playing with this was take one of the essay questions from last year’s AP English test, about the “significance of the green light in The Great Gatsby” and ChatGPT put out a very competent essay.
The other interesting thing about this is how much better GPT-4 was compared to to GPT-3.5. The models are improving.
The other major tech players are all working on their own offerings, such as Dolly, Hugging Face, and Google Bard.

- voice to text transcription – one we’re really interested in here is WhisperAI; our friends at the University of North Texas Libraries used WhisperAI to automatically transcribe XX TODO hours of recordings of sermons from 19XX. It worked really well.
- Image generation & description – you’ve probably seen some of the AI generated images, because they are fascinating and often beautiful, but we think there’s a ton of possibilities in describing images to make them accessible and findable.
- image to text transcription -- This happens when you snap a picture with your phone and if offers to let you copy the text from it, but our friends at Transkribus build models based on transcriptions of a particular hand (some of it from FromThePage) that can be used to then automatically transcribe other material in similar hands.
- music generation

I think it’s easier to understand the limitations of this type of technology by listening – it’s terrible. I’m from Texas, and I happen to like country music, which is not very sophisticated music, and when I tried to listen to this first example here I had to turn it off, it was so bad. There’s a lot of structure in music, and it refers “backwards” in time to repeat choruses and motifs, and the models really can’t do that well.

It's important to understand -- at least at a high level -- how these large language models work. When you understand, they're less scary, less inscrutable. I mentioned earlier they are "autocomplete on steroids"; let's dig into that just a bit.

This is a text visualization called a word tree. We love these because they are a great thing to do with text transcribed in FromThePage.
Word trees are a way of visualizing statistical weighting of "the next word" in a series.
So ChatGPT is similarly based on statistics, it guesses the "next word" in the sequence. Imagine a model based on the bible. The prompt "In the" could lead to "In the beginning" or "In the reign" or "In the time".
But of course it's more complicated.

After guessing once, the model takes all of the prompt, plus all of the response so far and asks for the next word. So in our bible example, It would not make sense to say "In the morning of Egypt". Instead, by giving it the whole context, it says, "Follow the tree of what we've given so far".
In the example here, from the book of Genesis, we see the most common sequence of words is “In the land of Canaan”, but that doesn’t guarantee that’s the answer ChatGPT will give. It’s like rolling a weighted die – the die is weighted to make “land” more likely to come up, but there’s always a chance one of the different “next words” will show up.
But of course it's more complicated.

It's not word-for-word, it pulls the "important" terms out of that input and weighs "next words" that are close to those terms "heavier".
So imagine that our corpus of words was not just the book of Genesis or even the Bible, but the whole internet. If I asked it, "Write the beginning of a story based on the book of Genesis from the King James Bible," I’d expect "Genesis" and "King James Bible" to be important, but it also decided “beginning” and “story” were important – and we ended up with almost a word for word STORY of creation from the BEGINNING of the Book of Genesis in the King James Bible.
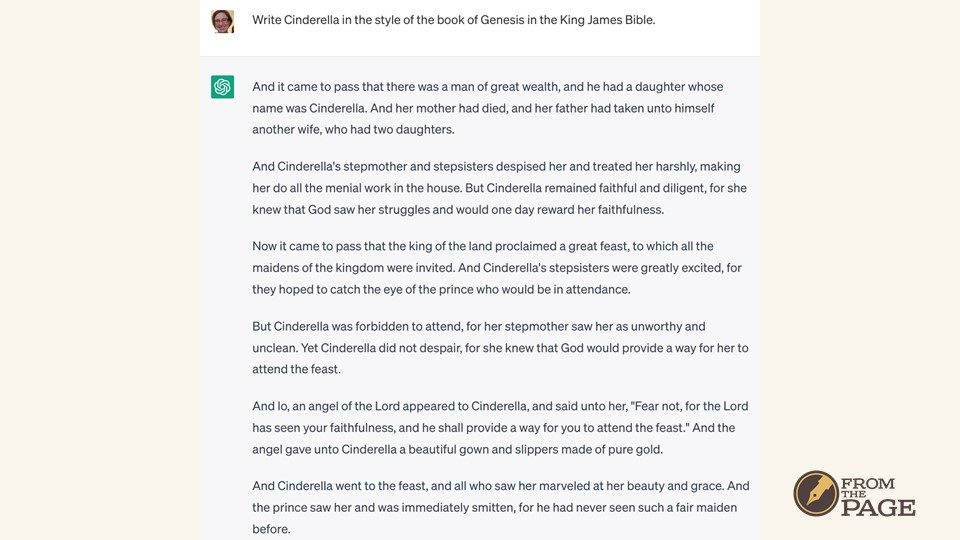
This lets you start doing some really interesting things by combining important terms, like this retelling of Cinderella based on the book of Genesis.
This is where it starts looking like magic, right? We can’t visualize how it got these results using our simplistic word tree metaphor. But it’s using the same underlying mechanism – just start visualizing your tree in 10 billion dimensions with statistical weighing of nearby and import words.
But of course it’s more complicated.

This is the disclaimers at the bottom of OpenAI's website.
There’s steps after building these trees that start “nudging” the tree:
For a given – already existing – human written text, how good is the model at predicting the next word? Nudge it to make it better.
For an answer, have humans rate the best answers. I love the 3rd one here – the trainers tended to prefer longer answers. Bloviating gives you authority!?
Nudge it to make it less racist & toxic – because we know the internet can be racist, sexist, toxic.
The interesting thing about these nudges – you can take any large language model, and start nudging it based on what *you* think is important. Medical diagnoses? Good writing? Known 19th century history? The combination of specialized knowledge sets AND “nudging” the model is where this technology is going be super powerful.

These large language models are called "Generative" because they "generate" responses to a prompt.
If we go back to the autocomplete metaphor and think about how gmail has started finishing your sentences for you -- or correcting your sentences for you -- I find that when I let it make those changes my writing is less pithy, it loses my style, it doesn't have my "voice", it gets longer and more boring.
When my family started playing around with this technology, my partner Ben tried many different prompts to get a story about an astronaut and dinosaur – and every single time the astronaut was named Tom and they became friends. Very stereotypical.

ChatGPT can write "in the style of Shakespeare", but it could never be "Shakespeare" (image of all the words Shakespeare invented). The amazing language Shakespeare put together is now available for the model to use, but “dead as a doornail” or “wild goose chase” are not phrases ChatGPT could generate.
So I don't like the phrase "generative"; "derivative" would be better.

Just because it’s derivative doesn’t mean it isn’t useful.
You have to understand it’s limitations, but now let’s talk about how we interact with ChatGPT.

What is a prompt?
A prompt is just a set of words, a question, a paragraph of text, a question plus 4 different bullet points. It’s words that you ask of these models.
When I started writing this presentation, the Image Service at Stable Diffusion is free, but you pay for a subscription to their prompt database. It’s free now.
For a while, prompt writing was seen as a very valuable skill; and I think it still is. Learning to write prompts is going to be an interesting skill. It’s not something I’m particularly good at – I’m an engineer, and a realist, and I don’t use nearly enough description when I’m trying to write prompts. I actually keep a “cheatsheet” of prompt examples.
My exercise for you – for after we’re done – is to go search & browse the Stable Diffusion prompt database, because you can see the types of prompts people who are enthusiastic and creative and spending a lot of time working on this are working on; what they’re putting in and what they’re getting out. Very technical descriptions – the 2nd one here has terms like “ISO 200” and “XFIQ4” – no clue what that is, but if I was a photographer, I might know.
I think people who write descriptive metadata or help people formulate research questions -- sound like anyone you know? -- might be very good at writing prompts. I think you should take your training and think about how it applies to this world.
I also think Vocabulary is a really important skill for prompt writing -- when you think about ChatGPT being "autocorrect on steroids", the words you use are very important. And I think we all know that the best way to build your vocabulary is to just read, a lot. So I don’t think our fundamental humanistic skills and intelligence is going away; I think words get more important. We’ll think different about how to use those words, because the system will give us new models to use, we’ll ask ourselves “how do I ask a question of a computer that thinks this way”.
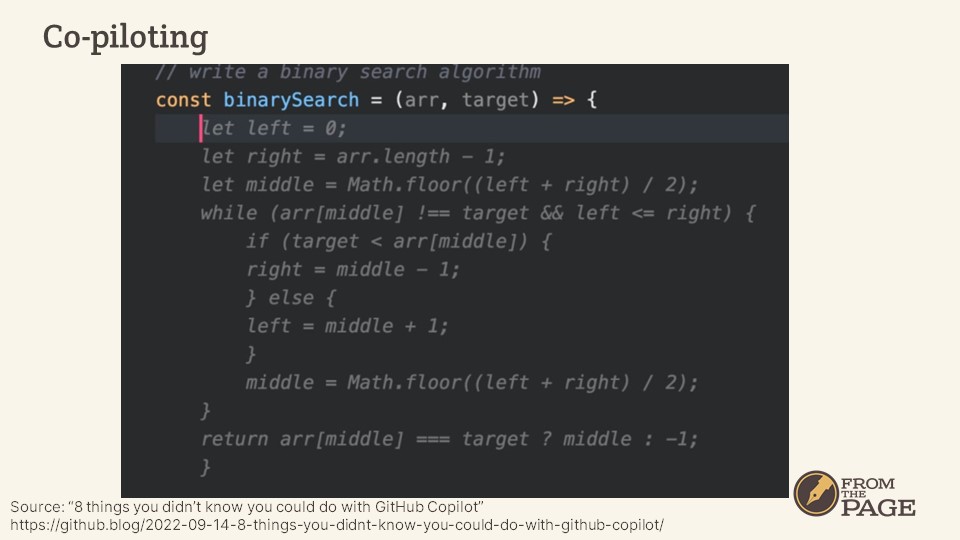
One of the first commercial applications of this technology is in "Github Copilot" -- an assistant as you code. Github is a repository of tons of code projects – we check things into it every day; They built a LLM based on all of this code in Github, and then in this example here you can see the comment at the very top “Write a Binary Search Algorithm” – that’s the prompt – then you can see all the stuff in light grey; that’s the auto complete; it’s the suggestion. And you can decide to use it or not. You still have to review it and think about it, but I think this model of co-piloting is really, really powerful.

We’re also seeing co-piloting popping up in writing platforms. This is a screenshot from Notion, a knowledge management tool. MS pulling this into the Office suite, Google pulling this into Google docs. I think the idea of summarizing a long document, or pulling action items out of meeting notes, or saying “quiz me” is a useful use of a LLM.
Think of these as augmenting tools, rather than automating tools.
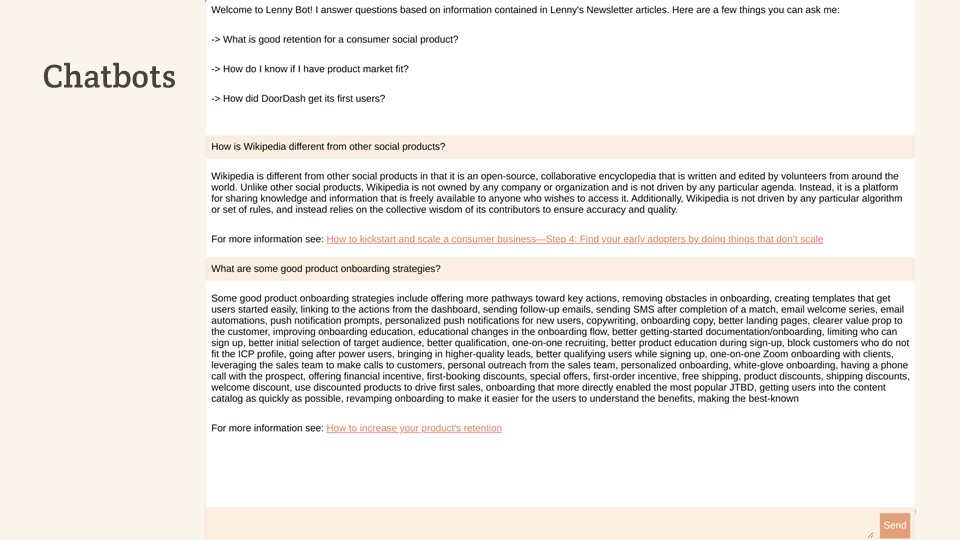
Remember how I said ChatGPT could reason, but it didn’t know a lot?
Chatbots:
- Based on a particular knowledge base
- Pull out relevant “bits”
- Use those as input to a ChatGPT prompt
- And that nudges the model in the direction you want.
Where it’s going to get really interesting is when we start training models on *different* knowledge bases.
This summer I’m working with an intern to build a chatbot based on a transcribed collection in FromThePage. We’ll do a webinar about it.

I'm not that worried.
You either have to start with a lot of original thought and creativity or you have to finish with a lot of original thought and creativity.
I think this is going to devolve into a garbage-in, garbage-out situation, so those of us who can do quality-in (either in prompts or feeding it context -- notes, quotes, ideas, titles) will get quality-out.
And it's just going to make those of us who can bring original thought & creativity into play more creative, because it takes care of a lot of the grunt work for us.
But I’m an adult, who’s trying to accomplish a specific task I already have a good idea how to do. If I was teaching, I would be thinking hard about how to restructure assignments so students would have to think & create rather than regurgitate facts.


We were visiting my sister in Switzerland over Christmas, so I asked ChatGPT "what are good things to do in Bern in winter?" And one of the answers was "Go see the bears." I'm kind of excited -- there are bears in Bern? So I do some traditional, google-based research and learn that there have been bears in Bern since the 1500s, that you can take a tour of the historical bear pits and the newer, more humane, bear preserve and....
that bears hibernate in winter and it's closed.

My emotional response was similar to if a person had lied to me.
ChatGPT doesn't try to be right. It tries to be plausible. You’ll hear this called AI hallucinations, but I think lying is more accurate. However, the not generally available GPT-4 model is said to be about 20% “less likely to hallucinate,” so this is getting better.

There are a lot of calls for attribution -- or auditing -- of answers from these large language models, but I don't think it's as easy as people assume it is. If you go back to the word tree metaphor for statistical weighing of what word comes next, to effectively audit an answer from ChatGPT, you'd have a list of documents that led to each word choice in an answer.
I think there's a possibility that you could try to reverse engineer attribution -- and it also helps with the lying -- by taking the answer and using it an input to a traditional search (over the same corpus). The results are sort-of your attribution?
We are seeing some tools like this one, called Phind, which displays attribution. However... I think it's lying. My guess is that Phynd is an agent that first does a search for your query, takes the results from that search, feeds it into ChatGPT, and asks ChatGPT to generate an answer based on that input. The attribution is the search results, but not "everything else" the LMM uses to answer your question.

In the US there are 2 cases suing the AI companies for copyright infringement on image generation. The arguments hinge on "fair use", and whether results generated by these AIs are "transformative" or "derivative".
In 2005, publishers sued Google for indexing copyrighted books and surfacing snippets from those books in search results. It took 10 years, but Judges in that -- and similar – cases ruled that google’s approach was indeed transformative.
The Getty is one of the plaintiffs in the two current suits around image generation using AI. They claim that the image generation models were trained on their corpus without licensing/permissions, but only that *some* images generated by the image models are derivative. So who gets to decide?!
And this is about images, what about models trained on 30 years of the “open web”?

The question is "who owns the result of one of these prompts?" -- the creators of the input used to create it? The transforming software that led to this particular image? The prompt-writer who figured out the right question to ask?
I love creators, and the work they do. I love innovation. I love open data and the creative commons. And I know that
- the law doesn't understand technology very well, and
- technology moves so fast the law can't keep up, and
- national borders can't contain online resources very well.
I think we’ll at least start with lax laws here -- even though it does threaten makers -- and I’m OK with that because I want to see what this technology can do and I want it to innovate fast. I know not everyone is going to agree with that.

What does this mean for libraries & librarians?
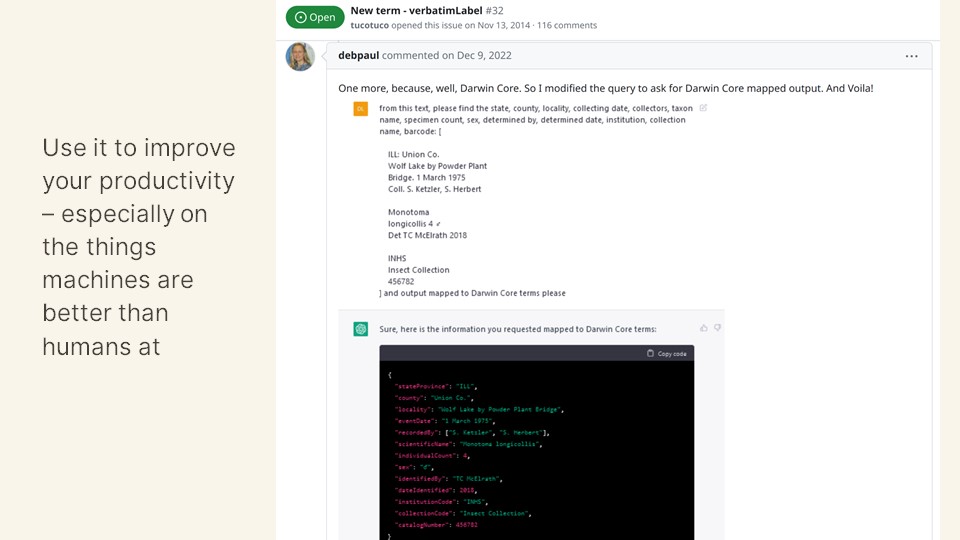
Use it to improve your productivity – especially on the things machines are better than humans at.
Deb Paul is the digitization and information technology specialist at iDigBio.

We write 2 newsletters every month for FromThePage. Last month our transcriber newsletter featured some cemetery interment cards and some marriage certificates. My teammate Ana used this prompt to come up with a *draft* of the introduction to that newsletter. But look what we put in to get that – we had to pick the collections, come up with a clever theme, a phrase we wanted to use, and a high level description of the two collections.

For our second newsletter, we took a very rough transcript of a rambling interview Ben had done – when he had COVID! – and asked ChatGPT to turn it into a newsletter. That was a bit too formal for what we were going for, so I asked it for a less formal version. Between the two, we were able to put together an essay for a newsletter with about 10 minutes of editing – but we couldn’t have without Ben’s years of thinking about transcription and digital editions, and the interview as input.

Librarians are information professionals that often work for public institutions.
Start by learning it yourself.
Then teach others.

One of my last quotes is by Tom Scheinfeldt, a digital humanities professor at the University of Connecticut. There’s a link to his talk on AI, Primary Sources, and Teaching in the resources doc. I was really shocked to read this, because we have all been working so hard for decades to make our resources more findable and accessible. I’ve been in conversations that literally go “how can we get Google to index this library material”.
I brought this up with Tanya Clement, another digital humanities professor at the University of Texas and her immediate response was “don’t we want this archival information, our history, to be part of the knowledge base of humanity?”
Two totally different perspectives, and it’s worth thinking about both sides of this.
I think there’s some lessons to be learned from the Github Copilot example earlier – none of the open source developers are worried about our code being used to train a language model – we understand that the value comes from what we build, not the specifics of how we build it.

- Use more primary sources.
- Not part of ChatGPT’s model (probably)
- Even if they are, they aren’t going to be statistically common
- Use more “human” traits.
- Teamwork
- Creativity
- Transcribe.
- Puzzling out handwriting might not be a core skill for students, but it forces a deep reading of a text.
- Asking for observations on the process & material makes them reflect on the task – something we’ve learned large language models are particularly bad at.
- Put material in historical context.
- I think it still requires humans to make connections between the spoken: “No butter at the store” and the unspoken: “rationing”.
- Asking for examples that speak to the historical context of the documents, forcing students to read deeply and look for clues. Historical detective work is fun, too.
- Compare the use and choice of language in the document.
- How does it compare to the student’s language use and choice? How is it similar in tone, if not content?
- Explore the materiality.
- What was something written on? Why would that be the material? How did the writer use that material?
- Did they reuse material (from a palimpsest to a daybook from a previous year)?
- What does that say about the technology and supply at the time? Did they write different material back-to-front than front-to-back?
- It’s hard for any digital format to capture all of these nuances.
- Look for commonalities.
- What events, emotions, or expenses in the documents remind students of their own experiences? What resonates?
- What is so far outside of the student’s experience so as to be foreign?