
We recently released our new spreadsheet transcription feature, and we're excited about how it can unlock structured data in your collections -- everything from scientific observations to census data. We're already seeing successful & diverse projects like Sewanee's Convict Leasing Transcription Project (part of their Roberson Project on Slavery, Race, and Reconciliation) the Indiana State Archives Jeffersonville Land Office Receipt Books and the Missouri State Archives 1850 Census Slave Schedules. This new development involved a lot of collaboration and testing, and we wanted to share both the challenges we encountered and what we learned along the way.
We asked our steering committee -- members of the state archives who funded the feature -- to provide example documents. They provided us with some amazing material to work with, ranging from colonial tax records to escaped convict logs. Testing with real-world documents -- and many of them -- was a great way to make sure what we were building actually worked with the reality of historic documents.
We also chatted with Evan Roberts, a demographer, about challenges transcribing tabular data. From him, we learned the term “screen ruler”. We had known that “eye-skip” was a problem with dense ledgers and lists, but that was a new word, and the most mathematically complicated programming we’ve done in a while.
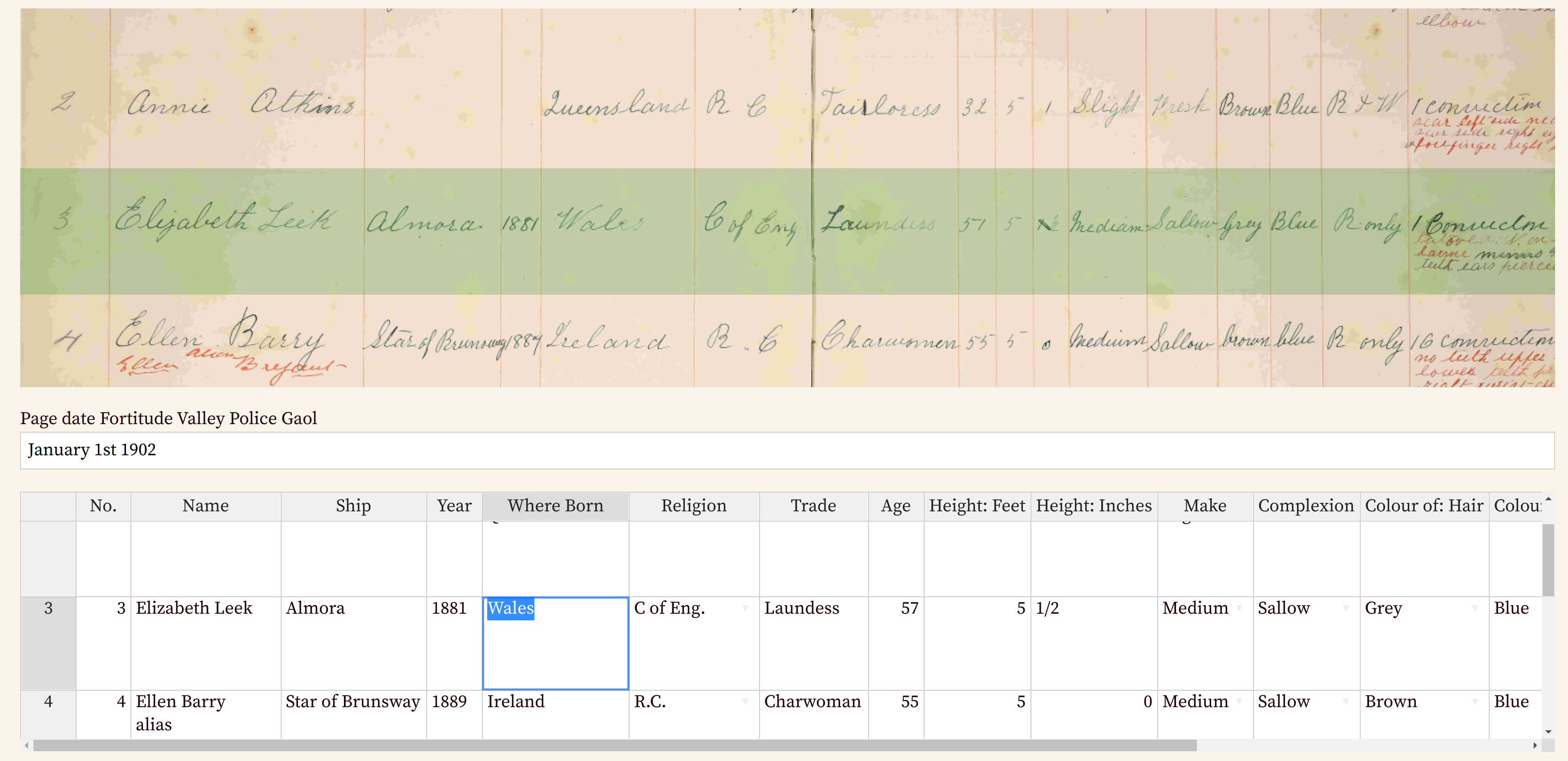
A green screen ruler tracks the part of the image a user is transcribing.
Evan also taught us some neat tricks like encouraging transcribers to go down columns instead of across rows.
During testing, we learned:
- “Age” can be listed as “6 mos” instead of a number like “12”.
- A field can be configured as a number, but needs to accept other types of data too
- If we highlight format mismatches (like text instead of a number), red is not the best color because it makes transcribers feel they’ve done something wrong.
- Some documents include conceptual lines, but are not a pre-printed form. The handwritten lines may tend to slope downward as you go down the page. This meant projects needed to be able to disable the screen ruler.

Papers of Ernest Henry Wilson, 1896-1952. Account book, 1906-1909, Arnold Arboretum Horticultural Library, Harvard University
As we worked with these documents, we improved project configuration which was simple with our field based transcription, but got substantially more complicated with up to 20 fields of structured data. Drag and drop to rearrange field order; automatic sizing of columns; and “add row” menus for transcribers to add unexpected rows at the end of a document made configuring spreadsheets (and other projects) easier.
The biggest bug we discovered with our beta testers was a doozy -- the lines of a spreadsheet would become garbled as they were saved. After some very tough digging through logs, we discovered that saving a page of this dense data was taking so long that the transcriber had time to hit the save button again before the previous version was completely saved. This conflicting save -- what’s called a “race condition” -- resulted in mixed up lines of the spreadsheet. Compared to figuring out the problem, fixing it was easy: we improved performance thirty-fold, which improved all transcriber experiences, not to mention no more garbled lines.
We had always struggled to determine if a page was completely transcribed or not. Our approach had been to assume if a page had transcription text it was transcribed, and to use the “needs review” checkbox to indicate if more work was needed. Materials transcribed using the spreadsheet feature though, were so *dense* that assuming a transcriber could get through the whole page in one sitting was unrealistic. To address this, we introduced a new “done” button in addition to our “save” button. The “save” button saves a version of the page, but the “done” both saves and marks it as complete. (We were fans of the digital humanities philosophy “no final version”, but archivists and librarians actually need to know that something is “done” so it can be ingested into downstream systems.) This then led to clearer page statuses -- “untranscribed”, “incomplete”, “transcribed” and “needs review” that we used to improve the user interface for all types of documents so transcribers have an easier time finding pages to work on, and project owners have a better sense of what is complete
Export
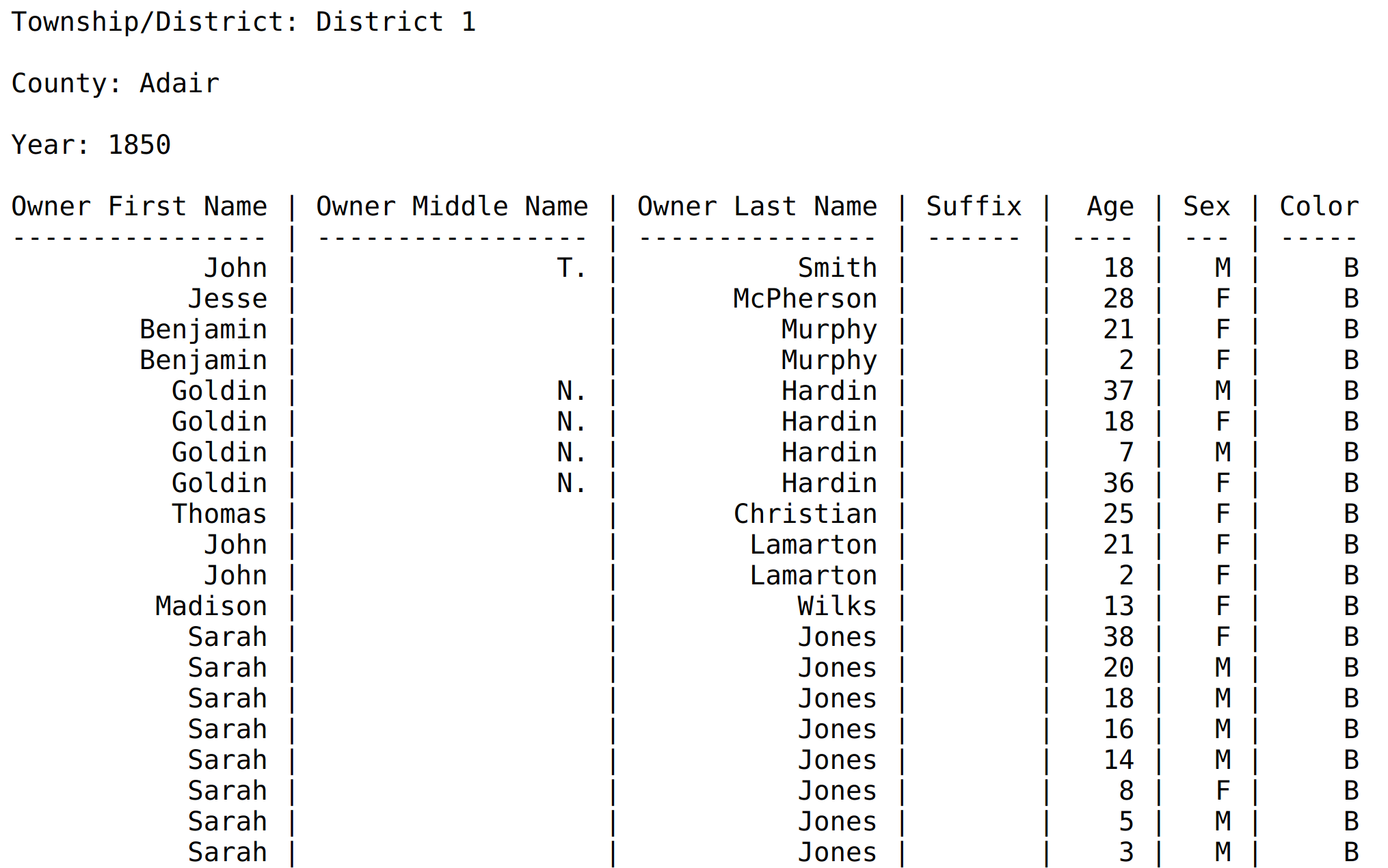
Another issue we encountered was handling dense structured data in a text export. A lot of our project owners use CONTENTdm, which we push plaintext transcripts to, but what does a plaintext transcript of a spreadsheet look like? We eventually settled on markdown tables, which are human readable, but still structured and easy to turn back into a spreadsheet in the future.