
Last month, Ben and Sara Brumfield hosted a webinar to introduce the new AI-assist feature: Handwritten Text Recognition. The presentation, linked below in a video and embedded as slides, presents a walkthrough of the new HTR feature. This was one of FromThePage's most-attended webinars, and it was exciting to have so many people join. You can sign up for future webinars here.
Watch the recording of the presentation below:
Read through Ben and Sara's adapted presentation:


Today we’re going to start with some background on what Handwritten Text Recognition is, how it’s different from OCR or crowdsourced transcription, then cover the ways we’re integrating HTR technology into FromThePage. Finally, we’ll close with some AI hallucinations we encountered during the process, which is something everyone enjoys.

Let’s start by talking about what HTR is.

Most of us are familiar with OCR – Optical Character Recognition. This is a technology that’s been around for decades, which looks at an image of a printed document and automatically transcribes the contents of the document into electronic text.
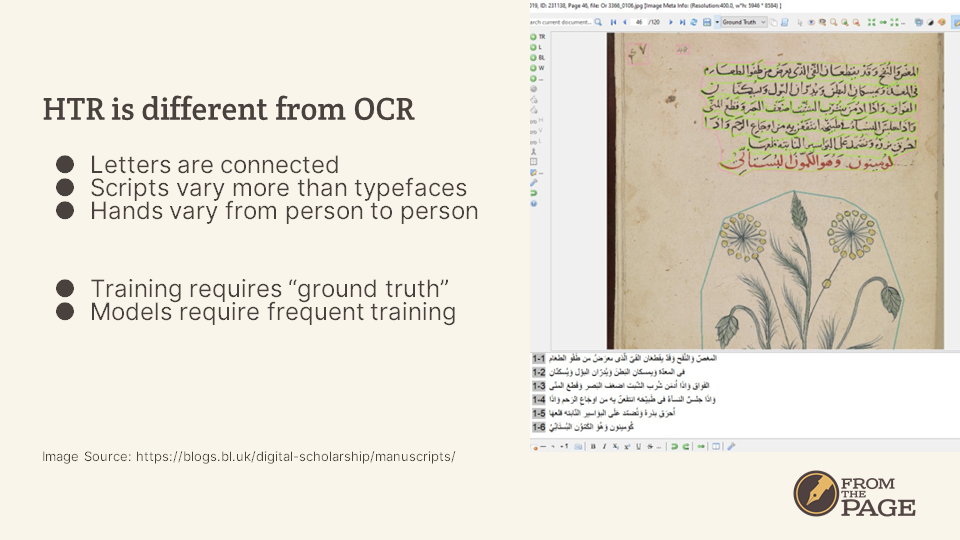
Handwritten Text Reconition – HTR – is similar to OCR, but it runs into some challenges that OCR doesn’t have. Letters are connected in many handwritten documents, which means that the software isn’t able to isolate a single character to match against a database of similar characters – instead recognition must be done word-by-word, which complicates the problem.
Also, scripts vary a lot more than printed typefaces do. And two people who have been taught the same cursive script may write very differently – a clerk will probably write in a different hand than a farmer will, even if they were taught the same script.
As a result, HTR software must be trained on “ground truth” – human-transcribed text matched to the images it was transcribed from. HTR software often must be re-trained on a particular hand, which is rarely the case with OCR.

HTR is also different from Human Transcription. Aside from the difference in process, HTR output is like OCR output in that it maps transcribed words onto matching regions of the image.
The output of HTR engines usually includes bounding boxes for each word, describing the coordinates of the image matching the text.

This bounding box linking can be really powerful – it’s what powers any full text search that highlights matching keywords, whether in digitized newspapers or in PDF files.

HTR engines don’t differentiate between important text and unimportant text. This is HTR output from a diary entry, and you can see that–in addition to the diarist’s writing–it transcribes the pre-printed information on each page, including notes about the pheasant hunting season which I doubt that anyone reading this diary would care about. But the HTR system doesn’t know that.

So how good is HTR?

It depends. It depends on the document, the engine, and the model, but most importantly, it depends on what you plan to use the text for.

Most automated transcription systems talk about CER, Character Error Rate. The classic definition of CER measures the number of changes that need to be made to correct computer-generated text: substitutions + insertions + deletions divided by the total number of characters. So you’ll see CER numbers like 5% or 10% or 3%.
If the average word in English is 4.7 characters, the Word Error Rate you’d expect from a CER of 5% is 23%. That means that approximately 1 in 4 words will be incorrect.

CER isn’t perfect, however. For one thing, not all errors are equal: reading “Renée” as “Renee” has a CER of 20%, but so does reading “Renée” as “8enée” – these are really not equivalent errors. In addition, CER is a poor predictor of the amount of effort it will take to correct a text – finding subtle errors is a lot harder than finding obvious errors. For this reason, some alternative measures weigh substitution errors at 5 times the severity of insertions or deletions.

Because HTR and OCR tools match a transcription to the region of the image where it was written–which is a wonderful feature for word highlighting in full-text search–they can produce kinds of errors we wouldn’t see in human-transcribed text. People generally transcribe text in the order they read it, with some exceptions for footnotes or marginalia. HTR systems can slip up when they are analyzing the layout of a document, interpreting a two-column document as a single column, resulting in an unreadable text like this one.
(Note that the Character Error Rate of this text is 0 – a perfect score that hides an unusable text.)

Okay, I could nerd out about transcription errors all day long, but we need to get back on track.
We’re partnering with Transkribus, an HTR tool produced by the READ Coop, a group of universities, libraries and archives led by the University of Innsbruck. Over the past decade, they’ve advanced HTR technology for archival documents substantially.
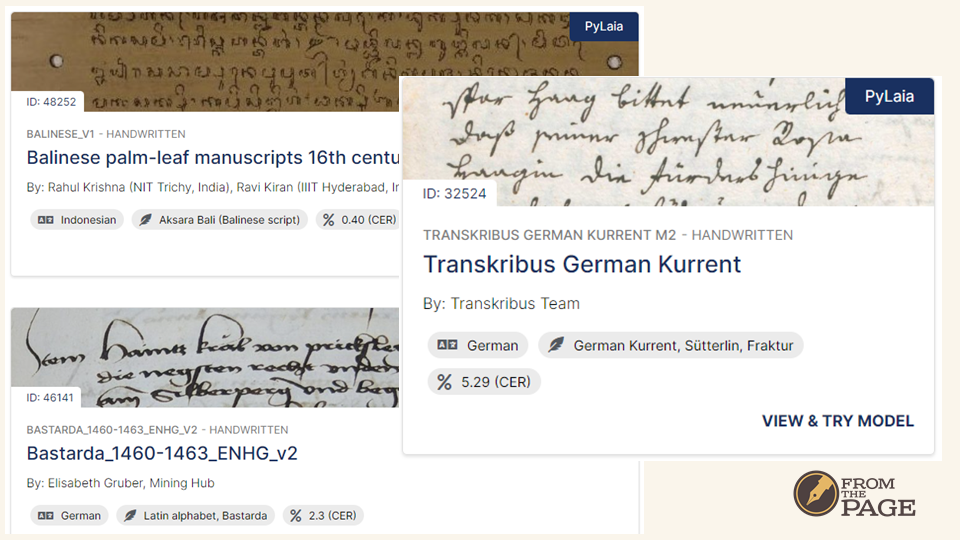
Transkribus offers thousands of models trained by their users on their own documents with their own ground truth.

Okay, so now that we have HTR, we can replace human transcription!
Hmmm… not so fast.
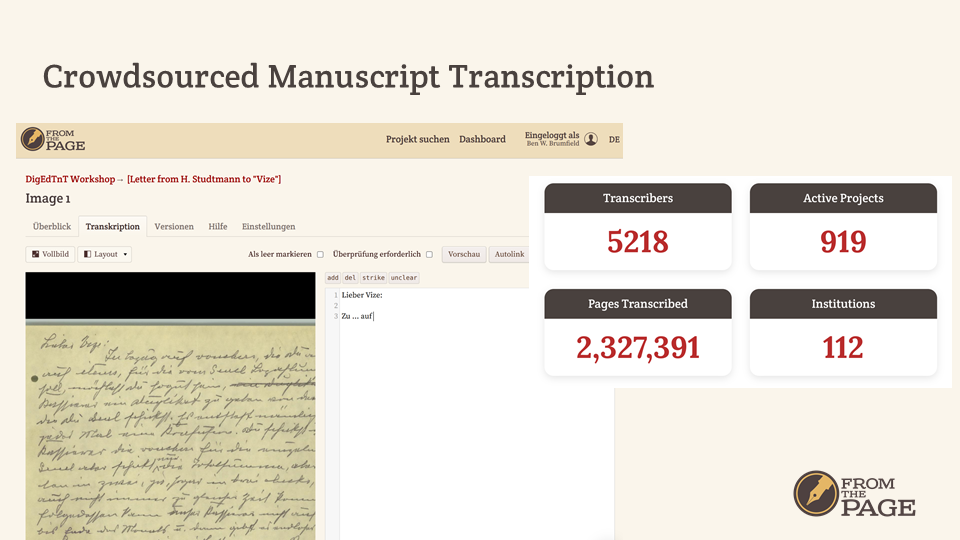
Sara and I run FromThePage, a web-based platform for manuscript transcription. Unlike HTR, however, we use crowdsourcing and collaboration to transcribe documents.
We've hosted hundreds of projects over the last few years, and our users have transcribed more than two million pages on the platform.
Why would the libraries and archives who we host want to keep human transcription?
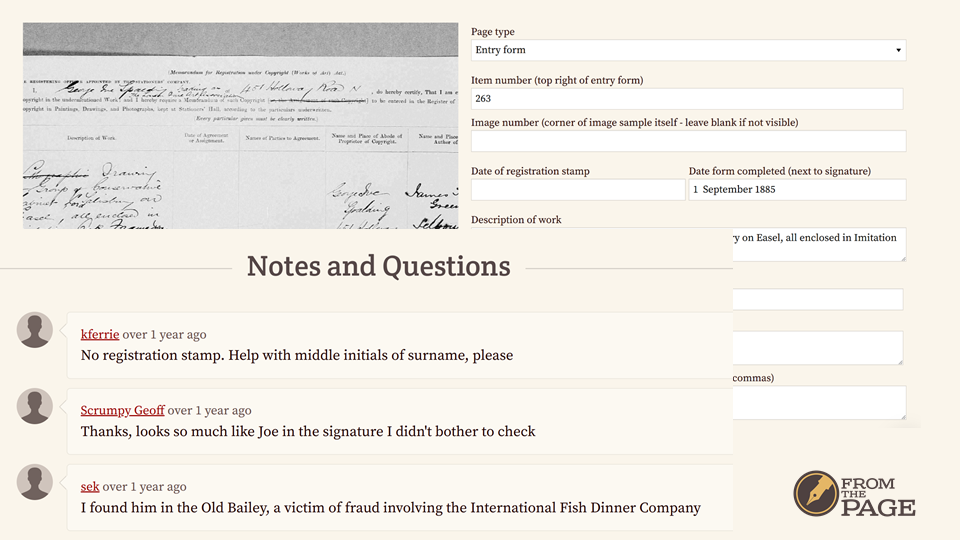
Humans are more accurate than machines. They can learn from context and develop expertise on a hand or a subject. Best, they can collaborate, as in this example at the British National Archives, where volunteers are helping each other decipher a name.
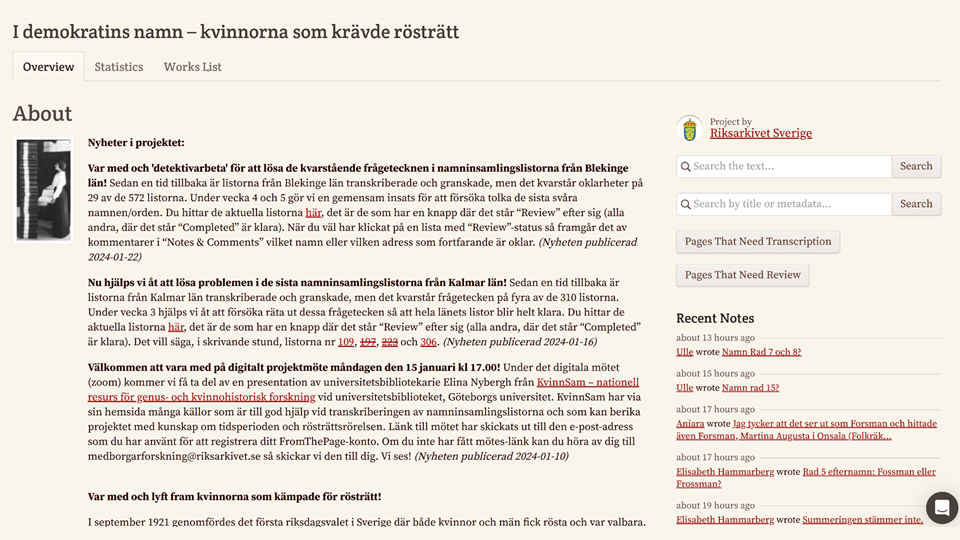
All of that collaboration provides an additional benefit: public engagement for the institutions we host. The Riksarkivet, has drawn 318 people to volunteer on I Demokratins Namn, transcribing women’s petitions for the right to vote. These are people who might not interact with the Riksarkivet normally, and now they have a connection to the institution and to its holdings.

Finally, transcribing documents provides meaningful volunteer work to people who are elderly, home-bound, or retired. (These are quotes from Tom York, who spends several hours each day volunteering for the Indiana State Archives and other institutions which we host.)

So HTR presents a challenge -- if we do not want to replace humans, can we use HTR technology in a way that increases our users' accuracy, enjoyment, and productivity?

These are the principles we want to follow for integrating AI into crowdsourcing.

We want AI functionality to be optional instead of required.
We want AI-generation of data to be transparent to users rather than invisible.
Finally, we want AI-generated data to seem tentative instead of "authoritative".

Here's how we're trying to use HTR to help transcribers.

It all starts with a page image -- this test is done with the 1883 Diary of Emily Creaghe, which is held at the State Library of New South Wales. These have been imported into FromThePage using IIIF, but they could have been uploaded as a PDF or text document.
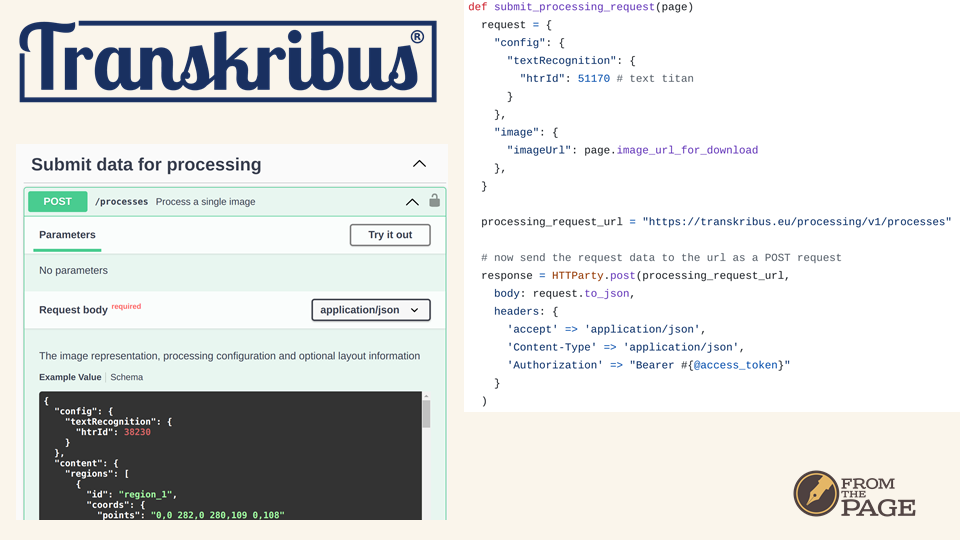
We take the URI for that page image and submit it to Transkribus using the Processing API, which lets us specify a model ID -- in this case the Text Titan model, which is excellent for general-purpose western scripts.
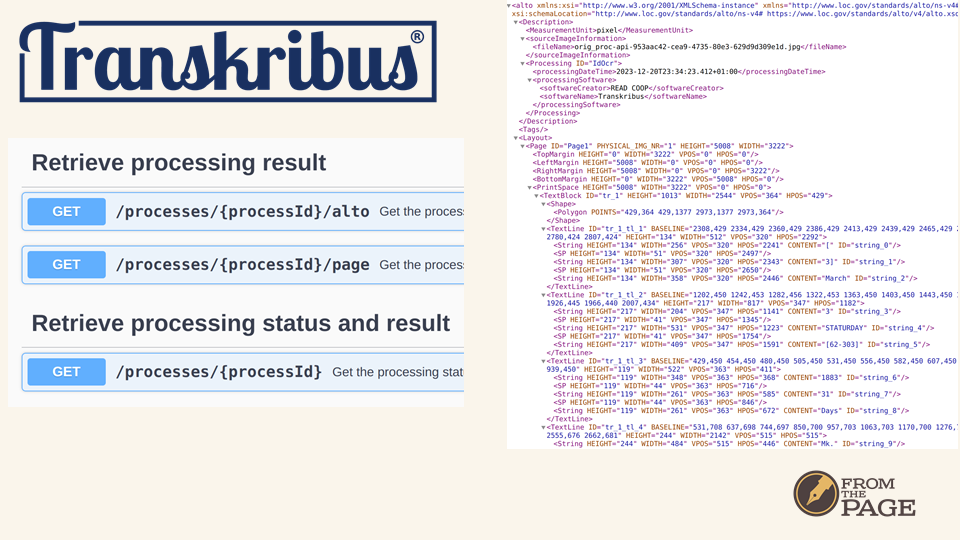
We then poll Transkribus to see when the processing has finished, and fetch the HTR text as ALTO-XML
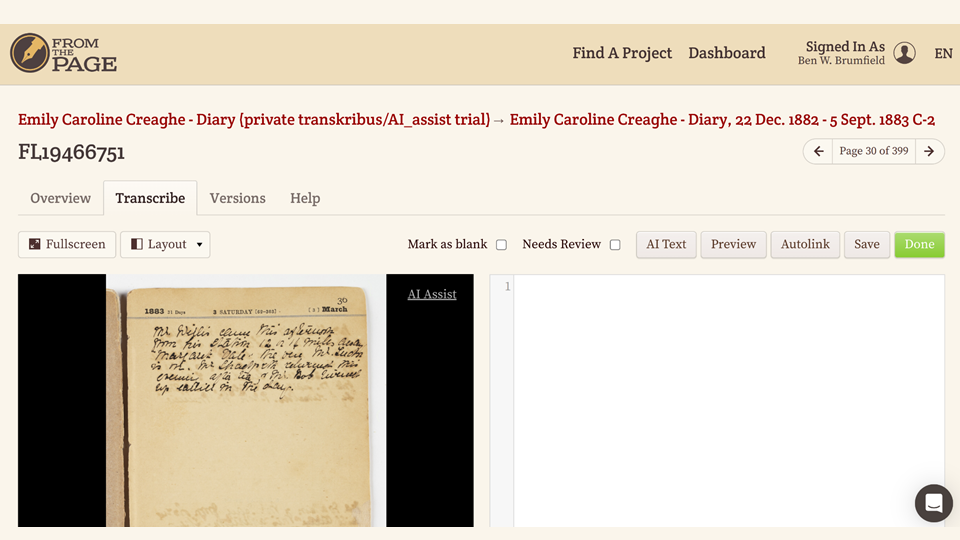
The next step is to present that text to our users as they are transcribing a document. Our transcription screen is pretty simple -- the image viewer appears on one side, and the text area is on the other.

Let's take a closer look at that image viewer. We've added a new button on the upper corner of the viewer. We're calling it "AI Assist" in our English interface, but French, German and Spanish use a variant of "AI assistant".

Clicking that AI Assist button takes the ALTO-XML and paints that text onto the image as a text overlay, letting users see what Transkribus thinks the text is.
(And I have to say that this is where I usually hear gasps from librarians and archivists -- Transkribus's output is really impressive!)
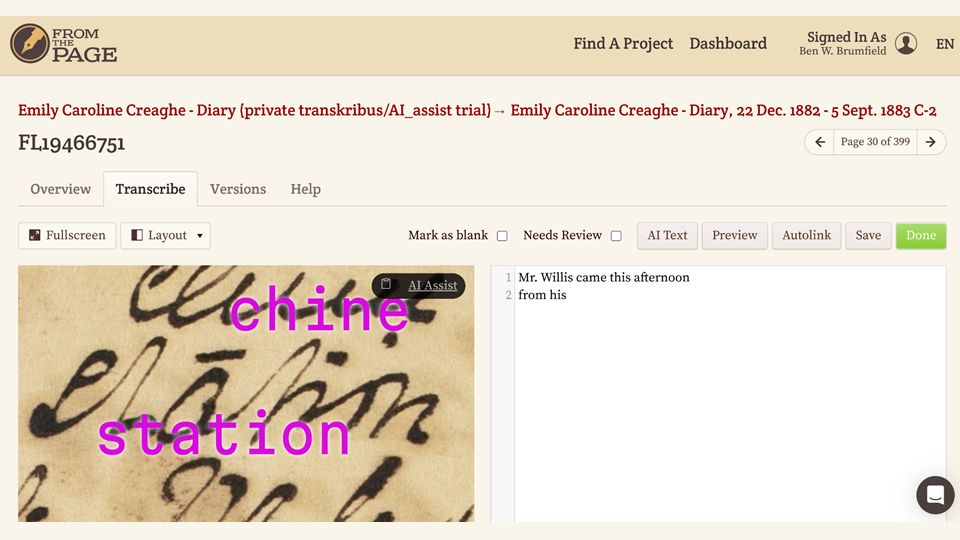
The text scales with the the image viewer, so users can zoom in and pan the image to see a word they are having trouble reading.
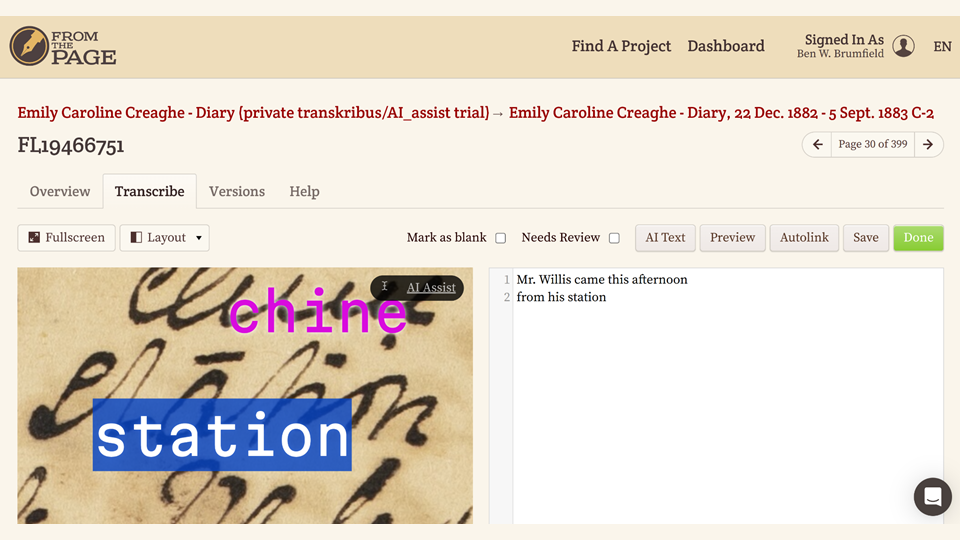
In this case, I've been transcribing the document and come across a word that does not make sense -- I can zoom in on the word and request an AI Assist, and I can see that Transkribus has identified the word as "station", which is an Australian term of what we in Texas would call a ranch.
Users can also lock the image display to select text to copy and paste into the editor.

But copy-and-paste can be a little slow. Can we use the text from Transkribus as a first draft for our transcribers to use?
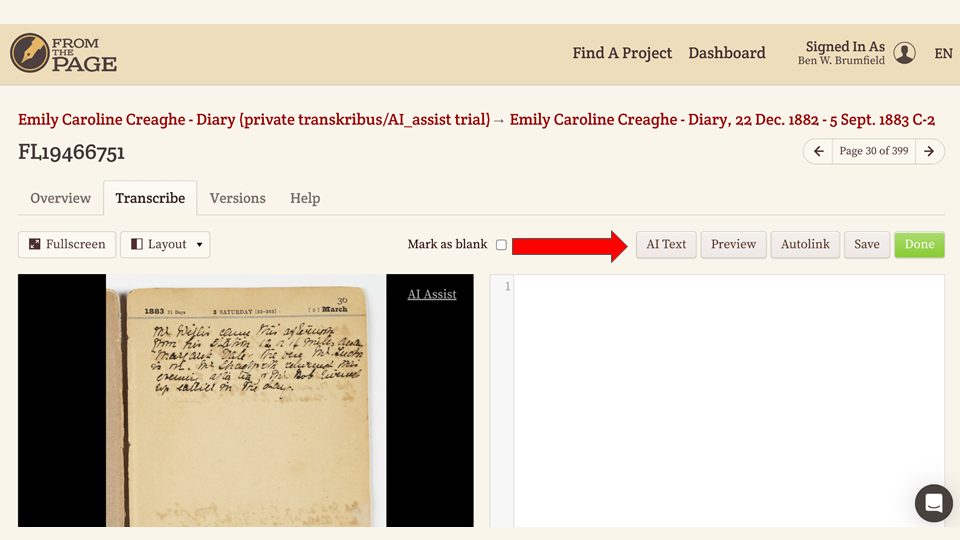
We added a new "AI Text" button to our transcription interface. It's optional--users do not have to click it--but if they do it should pull the HTR text in for them to edit.

First we need to convert the ALTO-XML into the wikitext which our transcribers prefer, a straightforward process.

But that text has errors -- a lot of them! We don't want that process of correction to be more difficult than necessary, so we want to highlight the errors so that our users can focus on them.
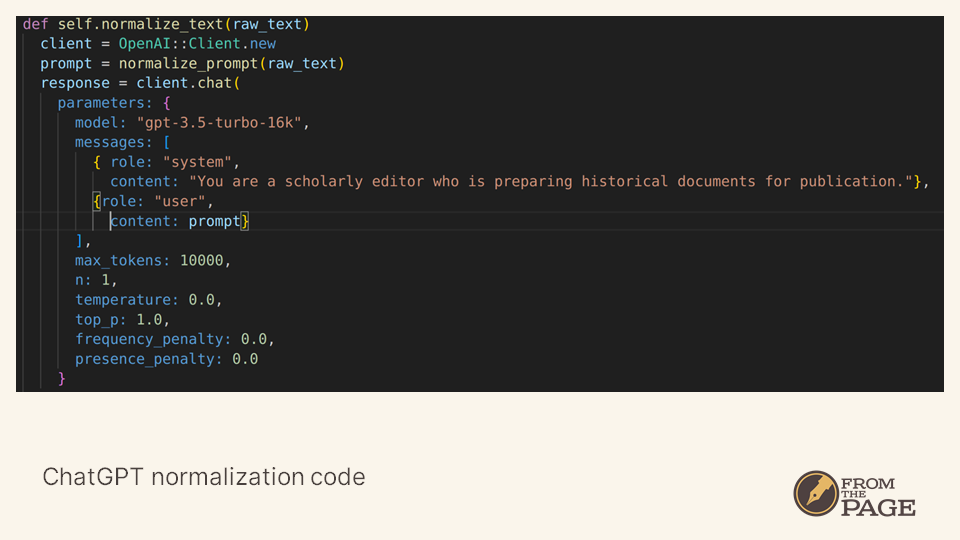
The first step in that process is to ask ChatGPT to normalize the text -- we tell it to be a scholarly editor preparing historic documents for publication.

Then we feed ChatGPT the raw HTR text with this prompt, in which we ask the large language model to correct any errors produced by the automated process.

That does a very nice job of producing a readable version of the HTR text. Most of it makes sense, and ChatGPT knows not to correct personal names.
There's just one problem with ChatGPT's corrections.

They are absolutely poisonous! The corrections are not based on a better reading of the image or better knowledge of the people and places in this document -- they are plausible but wrong!
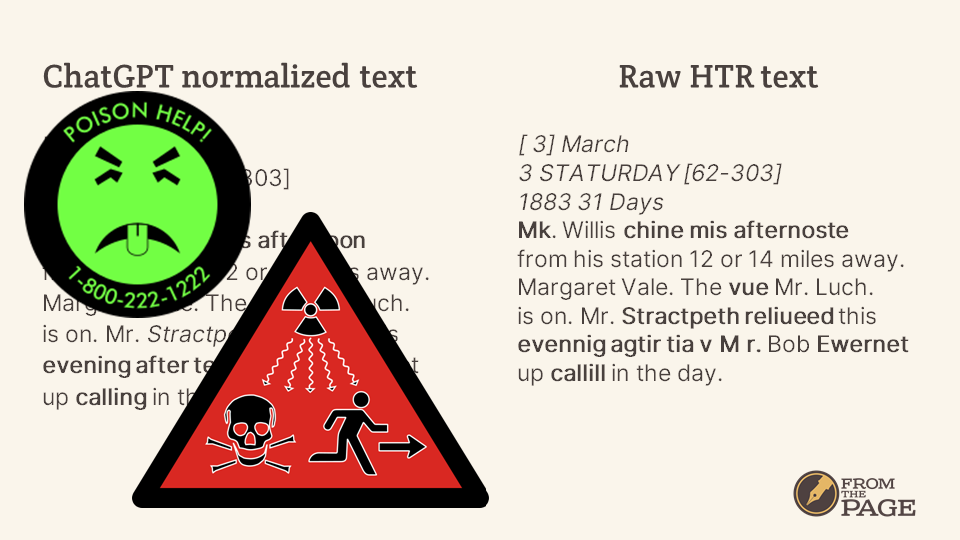
We want to treat AI-produced text like this as radioactive -- we never want to show this to users. Far better to show them the raw HTR text, with its obvious errors.
How can we use this poisonous text? The corrections produced by ChatGPT are worthless! But knowing what ChatGPT thought should be corrected -- that's valuable.
We also want our users to view AI-produced text with skepticism, and to be critical about it.

Hmm -- "puzzled face emoji"
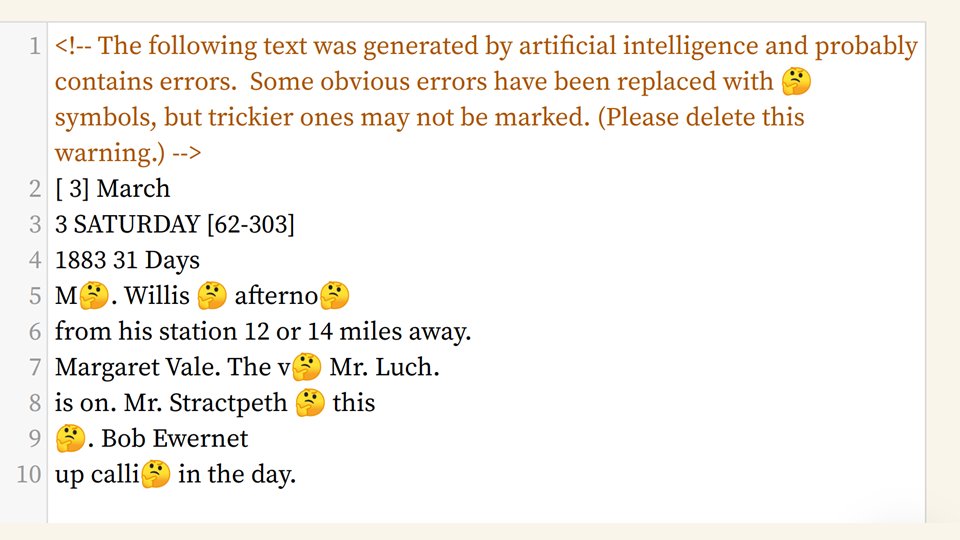
So we compare the ChatGPT-"corrected" text with the raw HTR text produced by Transkribus. Any time the texts are different, we replace the text with a puzzled-face emoji. Our goal is to make this AI-produced text look as un-authorative as possible, so that our users feel comfortable editing it.
(We also add a warning to the beginning of the text, which users are forced to delete as they edit.)
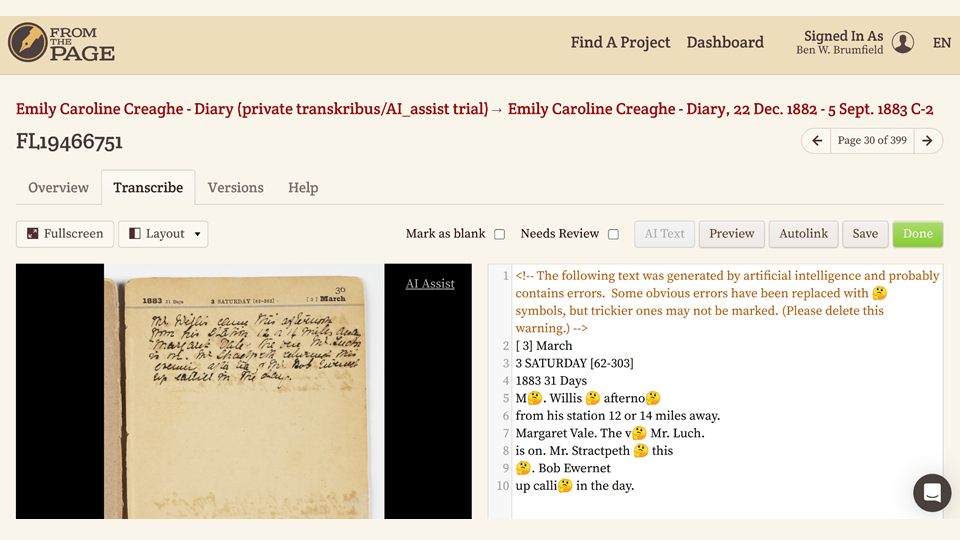
So this is what a transcriber sees when they request AI Text as they work. Our goal is to force them to consult the image as much as is necessary to get a good transcription.

At the moment, our friends at the State Library of New South Wales and the Center for Archival Futures at the University of Maryland are testing the usability of this feature.
We are testing differences in workflow -- should we start users with HTR and have them correct it, or should we make the AI text optional?
We are also testing differences in the text we show users -- do they prefer the raw HTR produced by Transkribus, or do they prefer the placeholder approach I just showed you? Should the placeholders be at the character level or should we used them to replace any word that contains a difference?

We hope to evaluate this testing on the basis of transcriber enjoyment; engagement with the task, volunteer productivity, and accuracy of results.

We received our first results this Monday

We’d like to thank the students at the Design, Cultures and Creativity Honors Program for their impressive work.

Students prefer using an AI text – they liked having a draft of the text to edit, and liked that they had control – they were able to decide whether to use it or not.

They also found that it helped them understand the contents of the letter before they transcribed it. On the other hand, they were not as happy with the emoji placeholders.

Once we have the results of this testing, what are the next steps?

We plan to integrate Transkribus HTR into the FromThePage user interface, allowing project owners to enter their Transkribus credentials, select a model, then process their documents.
We will also use the bounding boxes in the ALTO-XML files produced by Transkribus and merge in the corrected text, producing corrected ALTO-XML.
We also plan to explore additional HTR services – Transkribus is the highest quality, but lower-cost alternatives might be useful for some applications.

Let’s wrap this up with some fun stuff we encountered during the process.

Anyone who’s used OCR will be familiar with the gibberish produced when it encounters ink bleed-through – random punctuation marks.
When you feed similar images to Transkribus’s Text Titan Model, you get brief phrases in French or German.

We ran into another hallucination when we accidentally asked ChatGPT to correct blank pages. In those cases, it always produced the same text: a wild letter from a research who claimed to discover lost writings from the American Revolution written in code. This is straight out of a conspiracy theory!

Check out our HTR Sandbox and become a development partner for FromThePage's AI-Assist.