
This month’s update is a bit more technical than usual, but we think it’s important. It offers a behind-the-scenes look at how bot traffic—often related to AI training—impacts platforms like FromThePage and the digital infrastructure of cultural heritage institutions more broadly.
Over the past year, FromThePage has experienced three major service outages caused by waves of bot traffic. We documented the first of these, which was traced to Anthropic’s ClaudeBot.
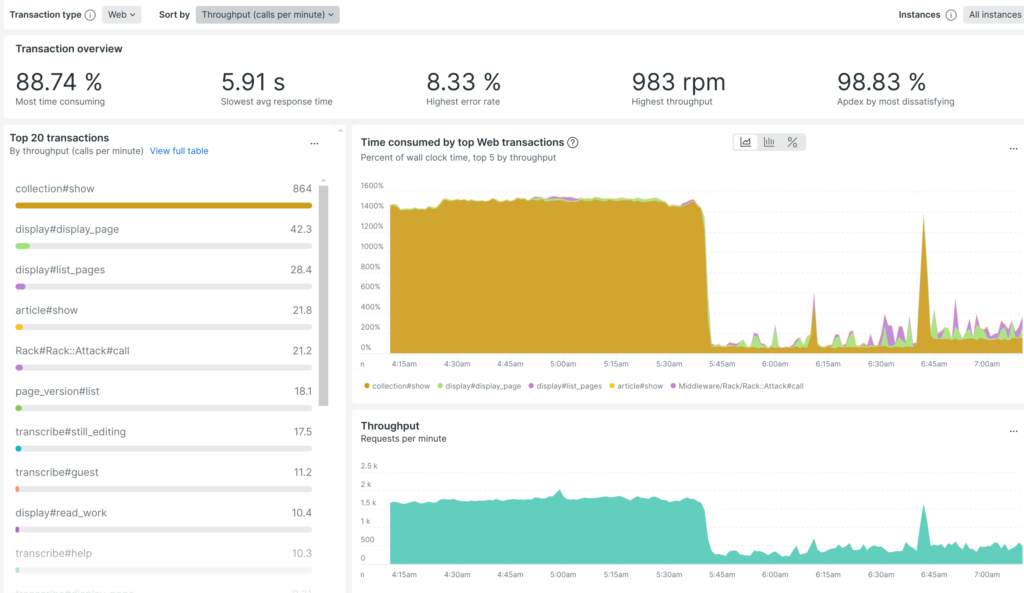
We’ve heard similar reports from other institutions, and the IIIF Slack community has had good conversations around this problem. The Wikimedia Foundation recently shared their own experience. These incidents don’t just affect our site—they sometimes disrupt our connections to content platforms where customers host their material, which may restrict API access in response.
[You can skip this next paragraph if you’re not into the technical weeds.]
The most recent bot-driven outage occurred Friday, June 10. This time, the traffic didn’t come from a well-known bot that plays by the rules (like respecting robots.txt or identifying itself). Instead, it appeared engineered to avoid detection: it hit obscure parts of the site that no one would casually browse, cycled through IP addresses, and used a rotating set of fake user-agent strings. We traced the IPs to Huawei and AliCloud data centers in Singapore and restored service by blocking entire IP ranges. We don’t love doing that—blocking whole regions might catch legitimate users—but in this case, it was the only way forward.
These kinds of attacks make us skeptical that rule-based approaches like robots.txt or proposed standards will be effective – and if the worst scrapers ignore them anyway, are we just penalizing the ones who follow the rules?
One thing we’ve realized: we can often respond to outages faster than larger organizations. That might be due to our tech stack—Rails has a great tool called rack-attack that lets us block IP ranges or suspicious bots quickly. But just as likely, it’s because we’re small. When something breaks, the two of us are in the same room. We troubleshoot together, decide what to do, and deploy fixes—all in under an hour.
Unfortunately, these waves of scraping traffic have consequences beyond our platform. Nearly every digital library system we interact with has blocked FromThePage from accessing their materials—which we usually do via IIIF (International Image Interoperability Framework). While we’ve been able to work directly with partners to restore access, it’s clear the mood has shifted. Institutions are no longer asking, “How do we share our assets responsibly?” but instead, “How do we protect our servers from being overwhelmed?” Whitelisting FromThePage is a workaround, but it’s not a scalable or interoperable solution.
Let us know if you’re seeing similar issues, or if you’ve found ways to mitigate them in your own systems. We’d love to compare notes.
— Sara & Ben
FromThePage