
Recently, both OpenAI and Google released new multi-modal large language models, where were immediately touted for their ability to transcribe documents.

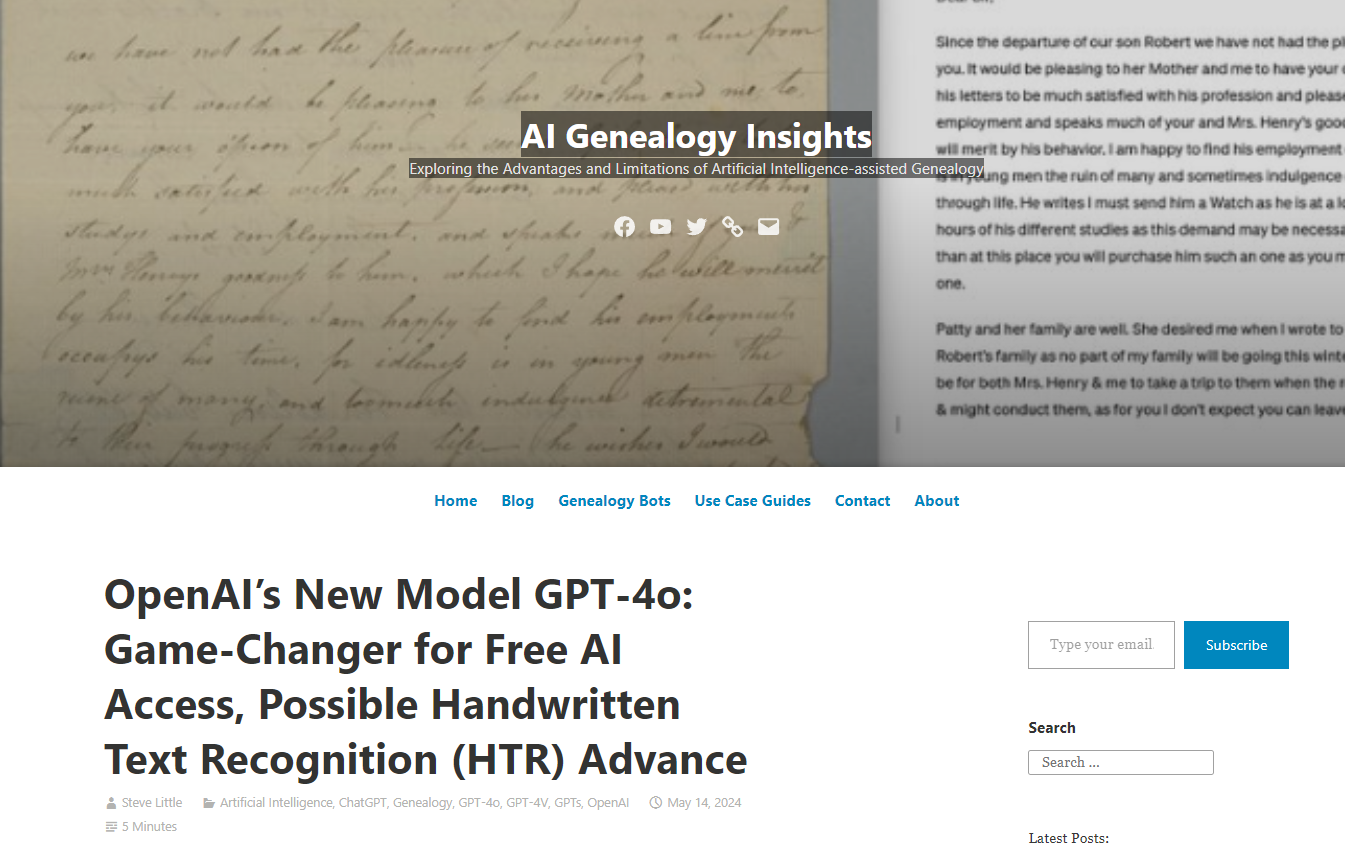
Also last week, I transcribed this document from the Library of Virginia’s collection from the Virginia Revolutionary Conventions. Let’s read it together:
Whereas his Excellency John Earl of Dun-
more Lieutenant and Governor General of this colony
by withdrawing himself from the Seat of
Government and on board one of
his Majthe King’sShips of War,
under pretenceby declaringthat he will
laydestroy the City of Williamsburg [illegible]
Emancipate our Slaveslay waste Emancipate our Slaves and destroy the country& by other wicked and hostile d[eeds]
There is this really interesting psychological distancing going on here, where the writer starts to say “his Majesty’s ship”, and changes that to “the King’s ship”.

This may ring a bell for some of you.
One of the central controversies of the New York Times’ 1619 Project involves the assertion that the Americans declared their independence in reaction to a rising Abolitionist sentiment in Britain, which threatened to end slavery.
This claim was disputed by socialist and conservative historians, but the discussion revolves around documents like the one we just read: colonists reacting against Lord Dunmore’s proclamation that enslaved and indentured servants joining his forces would be freed.
How do historians discussing this issue find these documents?
Traditionally, they had to be transcribed by humans, which is how I stumbled on this document.

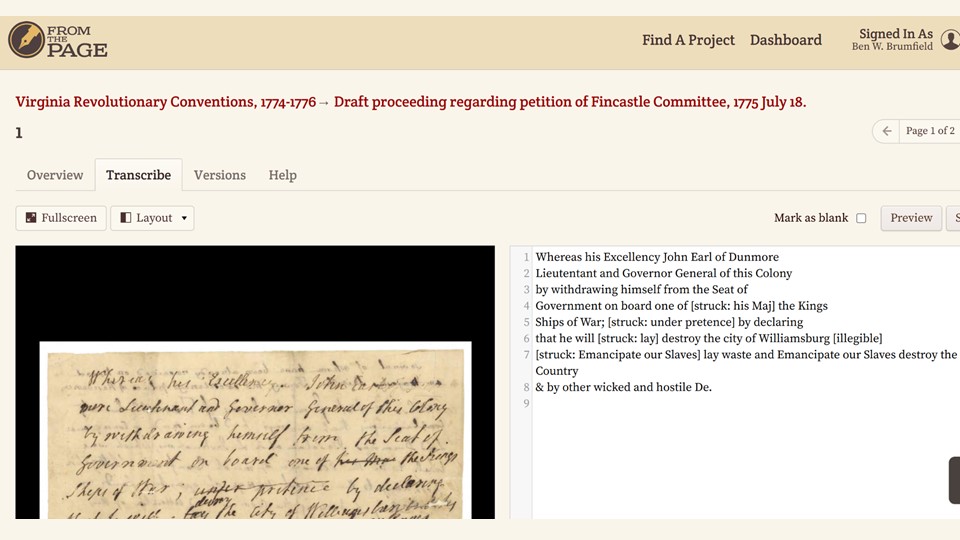
Traditional HTR tools like Transkribus’s English Eagle transformer model–and by “traditional”, I mean transformer technology from 18 months ago–produce output like this. It’s not great – the strikethroughs cause some recognition problems, and the insertions really scramble the reading order of the text.
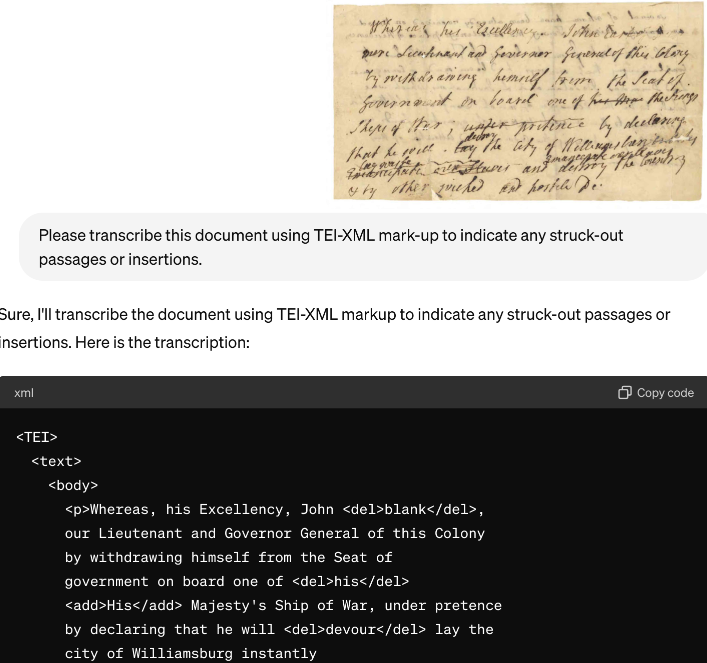
With the release of ChatGPT4o, we can attempt HTR via a large language model instead of a transformer.
I uploaded the document and asked ChatGPT to transcribe it, using TEI to represent the strike-throughs and insertions.

How do the results compare?
ChatGPT’s results make a lot more sense. But what are they missing?
Where is Lord Dunmore? That text was really faint in the image, so neither system transcribed it. Where is “Emancipate” or “Slaves”? If I’m honest, neither system produces the keywords I would want if I were researching this issue and looking for primary sources.
But there are hints of the subject in the Transkribus output – “Emaneepate oellaves Endrupare ol Haves” is the kind of thing which would raise red flags if I were reviewing uncorrected text.
More problematic is that the LLM output eliminates any hint of slavery, emancipation, or Lord Dunmore. Yes, it marked passages that had been struck through as if they were not, and mis-read “destroy” as “devour”, Yes, it swept away that psychological artifact with “his Majesty’s” and “the King’s”. But more importantly, it doesn’t look obviously wrong.
Which of these tools has a better Character Error Rate? I don’t know, and I don’t care!

The Transkribus output is obviously raw, and in need of correction. It looks tentative when you read it in isolation. The ChatGPT output looks much more plausible, and–in my opinion–that plausibility is treacherous.
LLMs are good at detecting subjects-like mention of slavery–in texts. I asked that question here, and the result speaks for itself.