

https://www.loc.gov/item/2005681082/
Crowdsourcing can be an exciting way to improve metadata and to experiment with making metadata more comprehensive. We all describe materials differently and uniquely based on our own interests, perspectives, and life experiences. How do you take crowdsourced metadata and make it useful?
In the book, Metadata: Shaping Knowledge from Antiquity to the Semantic Web, in Chapter 9: Democratizing Metadata, Richard Gartner proposes the idea of enriching metadata, then filtering it as a way to build access. Gartner says:
"The idea is to move away from a monolithic view of the users of metadata to one that recognizes their diversity. Enriched metadata should provide ample raw material to embrace this: what is needed are ways to serve up different views of it that are tailored to the idiosyncratic needs of those at the end of the search chain."
Metadata: Shaping Knowledge from Antiquity to the Semantic Web by Richard Gartner, p. 104
Allowing the crowd to create metadata allows for more enriched and diverse metadata that can then be implemented into your records and access systems. In this perspective, it’s also important to think about users of your resources and how they access materials in different ways.
--
But where to begin? The support of crowdsourcing volunteers can help diversify access and imagine better ways to enrich metadata. Embracing your crowdsourcing volunteers is all about being open-minded and ready to experiment. Trusting your volunteers with creating and enriching metadata also builds community. One way to start is to assess current metadata fields to decide which fields might be simple to fill in. For example, fields that relate directly to text visible on the image — like a page title, a date, or transcribed text — could be more straightforward. More subjective fields like the subject of a material or a description might be more challenging and time consuming, but present a great opportunity for your crowdsourcing volunteers to invest in the collections they care about.
When it comes to crowdsourcing metadata, institutions and project owners are sometimes resistant to or unsure of where to let their volunteers take initiative. Metadata can be complex, but our perspective is that your engaged volunteers who care about your materials are prepared to tackle metadata. Metadata is such an integral part of cultural heritage access, and has been for years. Why not let your crowdsourcing community be part of building access by creating metadata alongside you?
--
First, some history and background on metadata. The word “metadata” was first officially coined in 1968 by Phillip Bagley, a computer scientist, as “data about data,” but metadata has existed long before 1968, since humans have been recording history. In Jeffrey Pomerantz’s 2015 book Metadata, he discusses how librarians have been cataloging collections for millennia. Pomerantz notes that even in the ancient Royal Library of Alexandria, the librarian Callimachus wrote a scholarly bibliography called the Pinakes, which recorded authors’ names alphabetically and included descriptions of their works. This is an example of ancient metadata, used as a sort of bibliography and classification schema, in the same way catalog cards have been created by librarians to make resources findable.
Today in the cultural heritage, metadata still exists as a way to organize information, now in databases and access systems, for internal use, and to make materials findable by an institution’s patrons. Standardized metadata also allows systems to be interoperable. Most commonly recognizable metadata in cultural heritage is descriptive metadata, that describes an item being accessed, and allows materials to retain their context.
Some institutions have internal staff and metadata librarians who create and make decisions about how metadata is described, to maintain the institution’s authority and control. Other institutions have embraced crowdsourced metadata, sometimes called folksonomies, where users generate tags and descriptive metadata. The idea behind this is similar to that of crowdsourced transcription, making use of the diverse skills and knowledge of others, and incorporating it into a material’s description.
One of the biggest challenges in metadata creation is deciding how best to describe materials to allow users to find and access them. Metadata terms and categorizations often follow well-known standards, but even within these standards, some terms can be subjective. For example, a title or a date is often more straightforward, while a subject or a description can be more fluid. There is no exact science here, only guidelines provided by standards and an institution’s local rules.
Pomerantz says that metadata is like a map or a guide. This reminds me of the one-paragraph story “On Exactitude in Science,” written by Jorge Luis Borges. Borges describes a fictional world where an attempt was made to create an exact map of a territory’s land. This was impossible, and as the attempt was made, the map began to grow as large as the land itself, and became useless. This short story reveals that even the creation of a map is representative and can never truly be objective, though maps are often necessary for navigation. Metadata is like Borges’ map, designed as a wayfinding tool to lead users to materials and build interoperable access, but at the same time, is always subjective, requires decision-making, and can never be perfect for every user.
--
This is where crowdsourcing comes in. Crowdsourcing descriptive metadata relieves some of the burden of an institution’s staff members, diversifies the way materials are described by including other voices, and upholds institutional authority while also building community through expanding who gets to contribute to a project. Metadata and field-based transcription can also be used internally by staff, and for projects for student workers. The example below from Ohio University Libraries is an internal staff project used to generate metadata. Something like this would be a great option to expand metadata enrichment to your crowdsourcing volunteers.
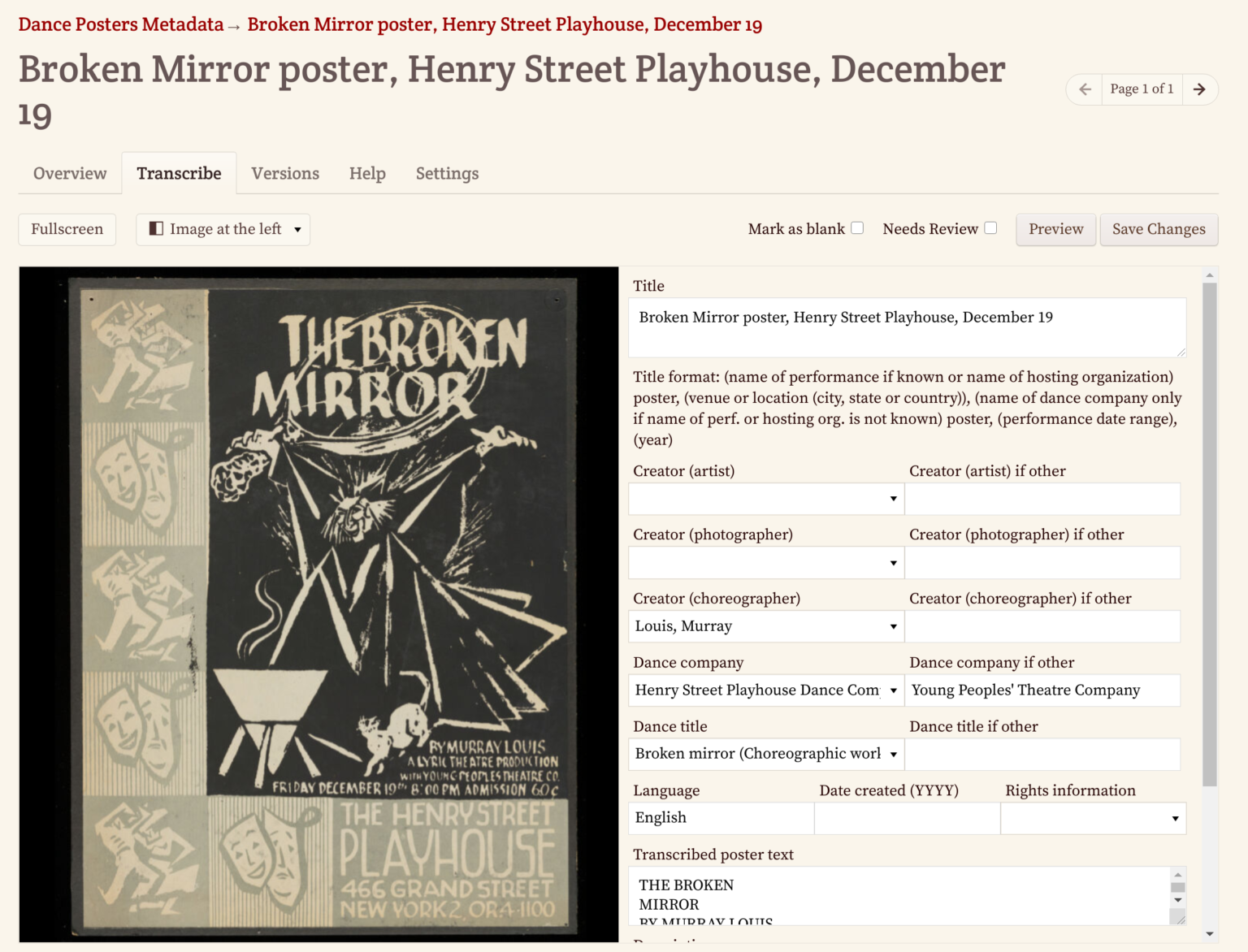
How do you know where to start to begin a project like this? Assessing current metadata standards and local implementation rules can help. It can be useful to think about the gaps in existing metadata. What collections use subject headings and which could improve? How are keywords and tags used? Better metadata can be achieved through a balance between institutional standards and community needs.
So, can the crowd create metadata? Our answer is absolutely yes. Don’t be afraid to let your crowdsourcing volunteers go for it and experiment with metadata. A chapter in The Collective Wisdom Handbook: Perspectives on Crowdsourcing in Cultural Heritage discusses designing crowdsourcing projects and working through challenges, goals, and objectives. The authors discuss a hypothetical crowdsourcing project that has the goal of enriching metadata to build better access. They share that in this case, in addition to creating metadata, part of the goal is allowing your crowdsourcing volunteers to dig in and learn about the collections—education is just as valuable as building access. Your crowdsourcing volunteers are often experts in the collections they transcribe, so they can be a good match for creating and enriching metadata, but even if they aren’t, this is a great learning experience and way to connect with materials. Our belief is that by harnessing the skills and power of your crowdsourcing volunteers, you’re adding more diversity and perspective to the way you describe materials, and contributing more knowledge and better metadata access points to your collections.
References and Further Reading:
Borges, J.L. (1975). “On Exactitude in Science” in A Universal History of Infamy (translated by Norman Thomas de Giovanni), Penguin Books, London, 1975. ISBN 0-14-003959-7. (Reprinted and translated from Historia universal de la infamia (A Universal History of Infamy) by J.L. Borges, 1946). (Short story text available here).
Gartner, R. (2016). “Democratizing Metadata” in Metadata: Shaping Knowledge from Antiquity to the Semantic Web. Springer. pp. 97-106.
Pomerantz, Jeffrey. (2015). Metadata. MIT Press.
Ridge, M., Blickhan, S., Ferriter, M., Mast, A., Brumfield, B., Wilkins, B., … Prytz, Y. B. (2021). 5. Designing cultural heritage crowdsourcing projects. In The Collective Wisdom Handbook: Perspectives on Crowdsourcing in Cultural Heritage - community review version (1st ed.). https://doi.org/10.21428/a5d7554f.1b80974b
Header image: Library of Congress. Card Division. General view., 1919. [or Later] Photograph. https://www.loc.gov/item/2005681082/.
Do you want enriched metadata from crowdsourcing? Book a live demo with Ben and Sara to find out more.