
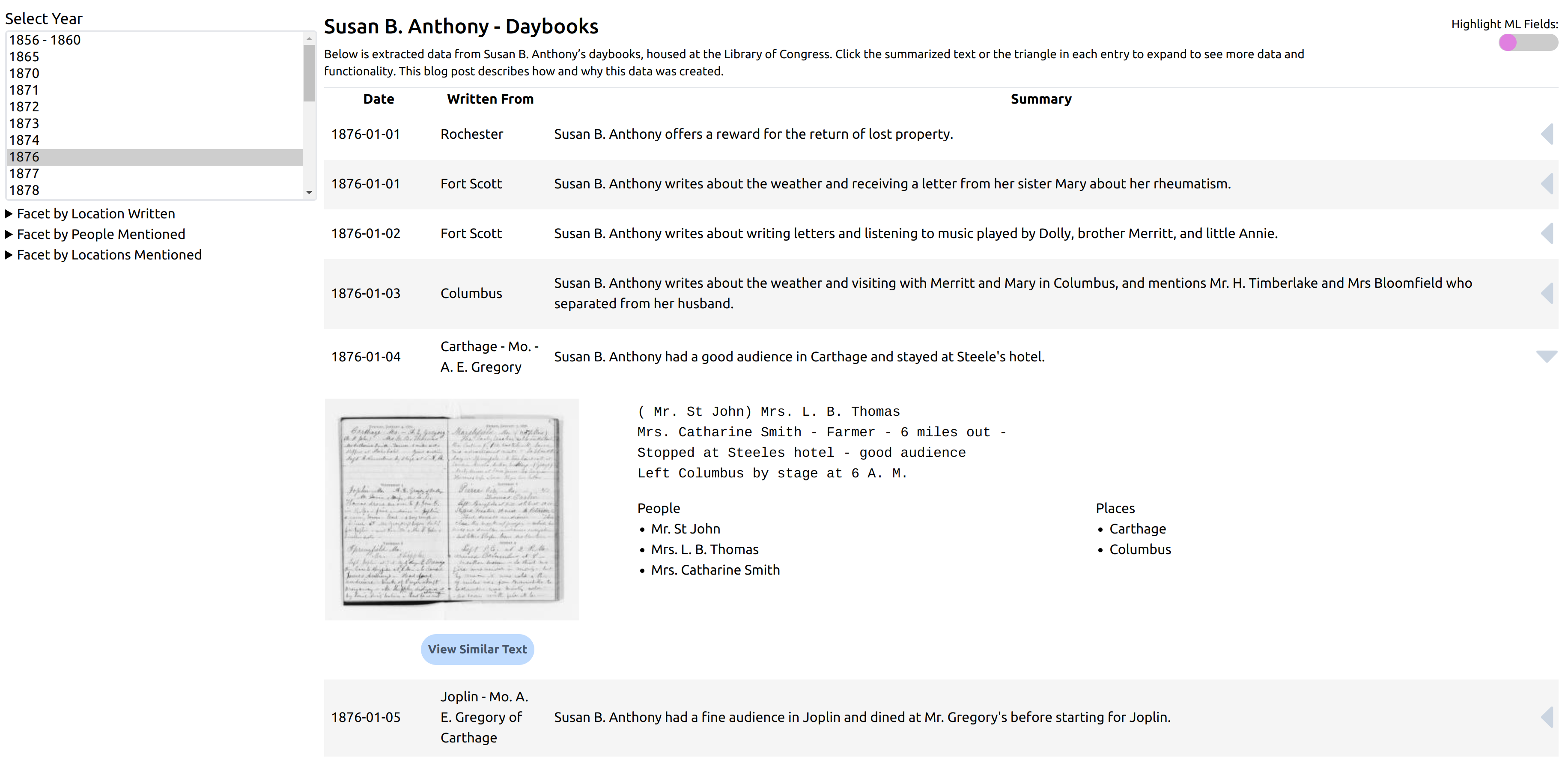
Have you seen Matt Miller’s experiments using the GPT APIs on the Library of Congress’ Susan B. Anthony Papers? If you want to understand the possibilities of AI for archives, this is a great place to start. You can read Matt’s write-up and explore his interface to the collection. He’s using the GPT APIs to achieve a lot:
- Parsing the documents to create structured metadata: date, location, and entry for her daybooks; sender, recipient, and date for her letters.
- Extracting people and places mentioned. (This is great for finding aids, but also for mapping documents.)
- Summarizing: Matt actually experiments with four levels of granularity: 1 sentence, 2 sentences, 3 sentences, 4 sentences. This is great for his user interface (or any search or browse output), and would be handy in a finding aid.
- Semantic searching: Highlight a concept or phrase to see documents related semantically to that phrase. Try it with concepts like “fear” or “scare” to see its power. This is different from keyword search in some interesting ways and is going to take training to teach researchers how to interpret its results.
- Suggesting similar documents: Using similarity to suggest other, possibly related, documents. I think this is the weakest part of the GPT APIs – I’m curious if you uncover anything useful with this.
- Acknowledging and showing machine-generated text. Possibly the most important demonstration here is how to indicate machine-generated material in the interface. Matt does it with a pop-up and with a toggle that highlights the machine-generated text.