
At the 2021 IIIF Annual Conference, Ben and Sara Brumfield presented "More Than Round Trip: Using Transcription for Scholarly Editions and Library Discovery." In this presentation, linked as a video below and embedded as slides, they talked about the challenges of bringing crowdsourced metadata and transcription back into multi-party library systems, and how FromThePage can help facilitate these complex collaborative projects from start to finish.
Watch the presentation here:

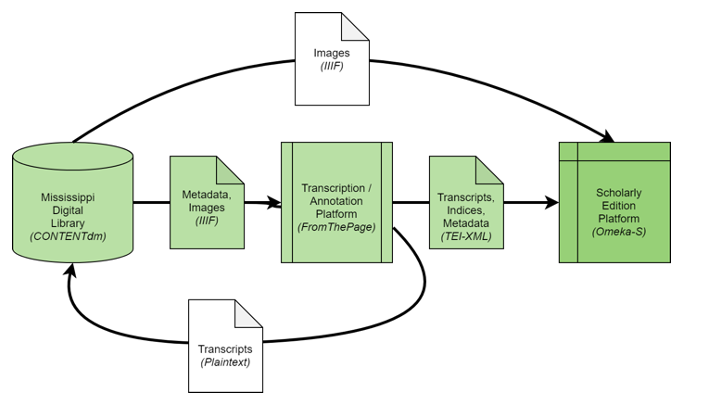
In the IIIF community, we talk a lot about interoperability. For crowdsourcing platforms, that usually means making sure that images and metadata from digital library systems are loaded onto the crowdsourcing platform, while crowd contributions are brought back into the digital library system.

Sometimes we describe this as "round trip" integration, as in this connection between the Fedora repository at University College Dublin and our own crowdsourcing platform, FromThePage.
But what if there are more than two platforms to integrate? What if there are more than one constituency defining the digitization practices -- each appropriate to their own systems, but arising from very different needs?
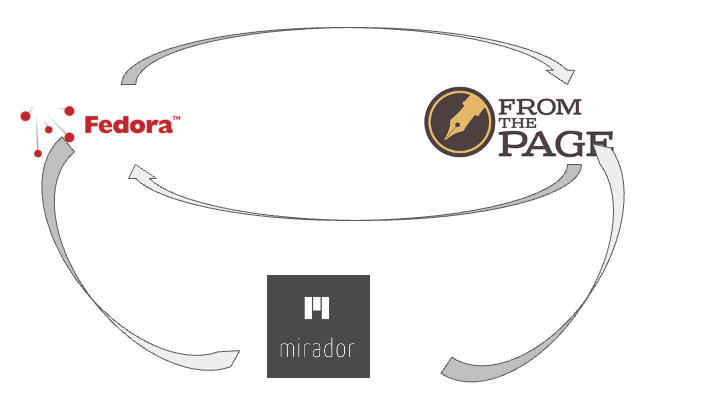
We're going to talk about multi-party integration enabling scholarly editors to use library materials and digital libraries to use metadata from those scholarly editions.
What about scholarly editions? Scholarly editions are a particular challenge for this kind of integration.
We’d probably better define them, however.
Scholarly editions are critical representations of primary sources, created by scholars who transcribe, edit, and annotate them.
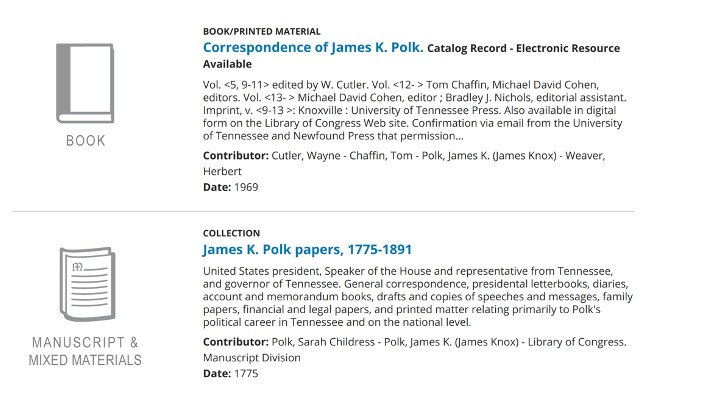
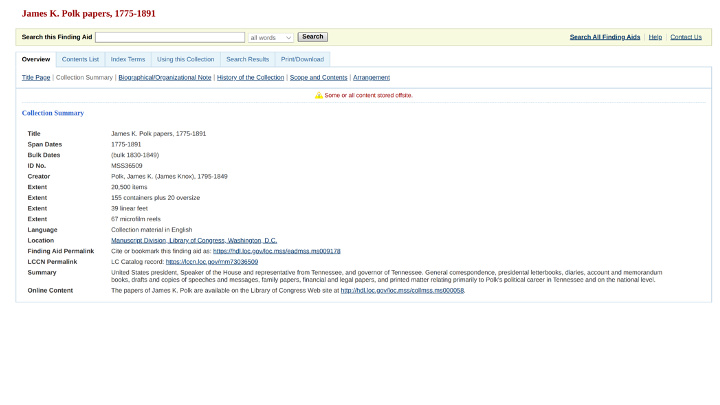
You have probably seen or used scholarly editions like these documentary editions from the United States. Often they are in printed volumes with titles like “The Papers of so-and-so.” (See examples below).

Scholarly editors have been working with special collections and archives for centuries.
However, in the print world, the possibilities for integration are limited.
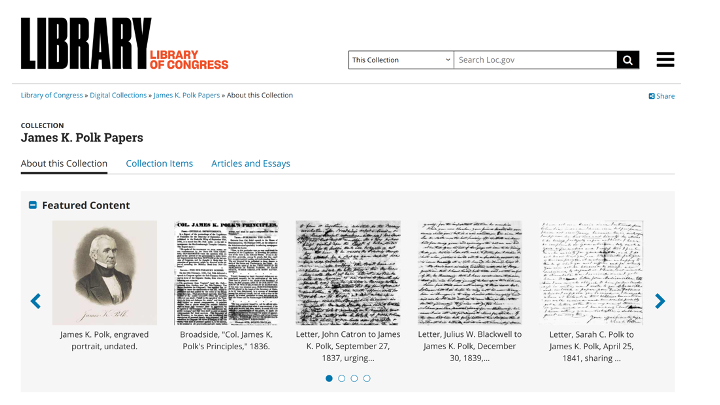
An editor consults material in an archive, either in person, requesting photocopies, or now viewing scanned images online (like the examples below of the James K. Polk Papers at the Library of Congress).
They transcribe and annotate the papers and publish them in printed books called letterpress editions.
The problem with this is there is no way for the library to use the edition to update finding aids on the original materials to help other researchers

At best, the letterpress edition could be acquired by the library but even then it would likely sit in the stacks separate from special collections. Perhaps material from the edition could be integrated into finding aids at the archives, but that process would be entirely manual.
The move to digital editions may have exacerbated this problem. At least the holding institution could direct researchers to both an edited volume and the archival documents used to created it -- when a publication is online, it's not really possible for the holding institution to accession it as they would a print edition.
Certainly there is no way for the user of this finding aid to search the full text of an edition to find the original document, as would be possible with, say, OCR text the library had created itself.
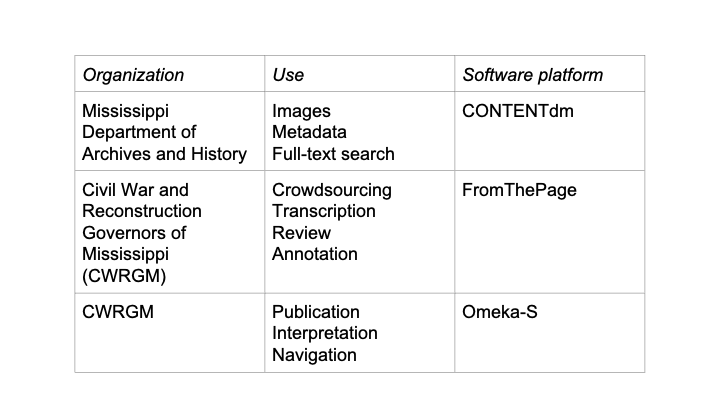
The Civil War and Reconstruction Governors of Mississippi Digital Documentary Edition is a new scholarly edition exploring the lives of everyday people through the lens of the Governor's office. From the “secession crisis through the early Jim Crow South, CWRGM is uncovering the voices that remain buried in vast archival collections. Because Americans — regardless of class, race, or gender — contacted their governors with abandon during the Civil War and Reconstruction, these papers offer insights into nearly every major issue of the age in Mississippi.”
It's a collaboration between Scholarly Editors, librarians, technologists and the public.

And it uses standards like IIIF and TEI to integrate a digital library system, a crowdsourcing platform, and a digital publication platform.
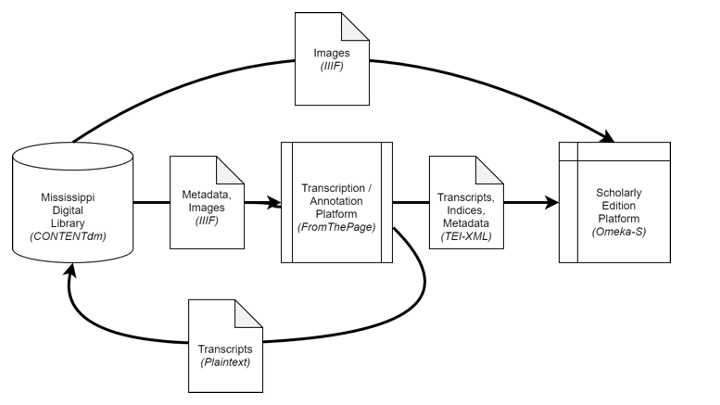
Let's take a look at each step in this process, as we trace a letter on its journey to the digital edition site we see here:
We’ll start at the archives:
The original documents are held by the Mississippi Department of Archives and History. Staff there have scanned this collection and posted them in their digital library system, hosted on OCLC's CONTENTdm.

We have images and metadata on a digital library system. How do we get them out?
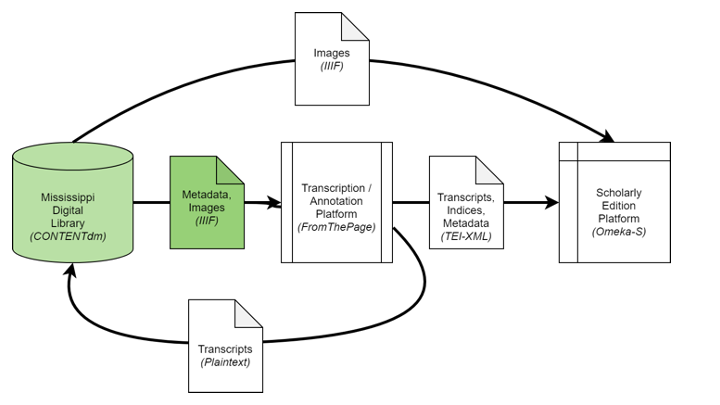
Fortunately CDM supports IIIF, the International Image Interoperability Framework suite of protocols.

Here's the IIIF manifest for this letter, it provides us with metadata about the item:
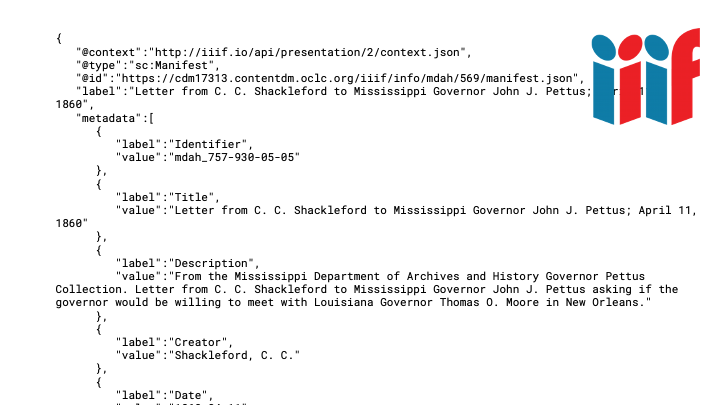
...and also the structures we need to access the IIIF Image Server for each page:
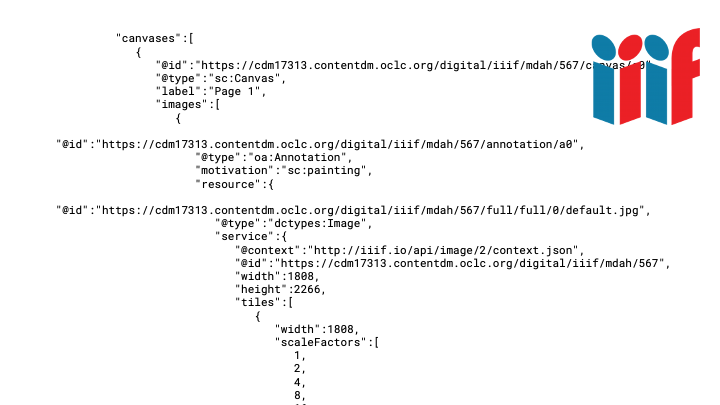
So we can import that manifest, with its image references, into FromThePage, the crowdsourced transcription platform we run.
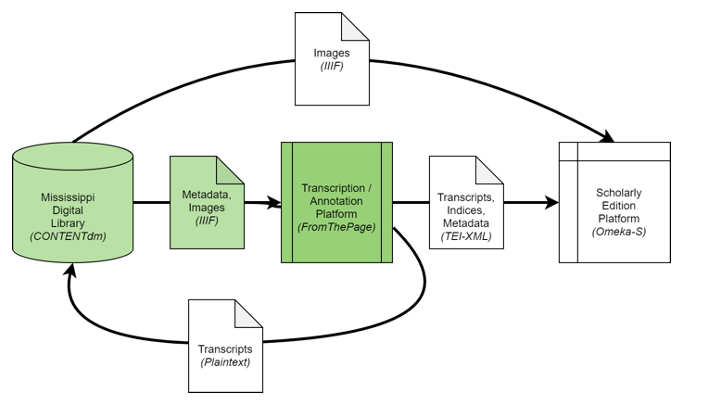
Now it's ready to be transcribed.
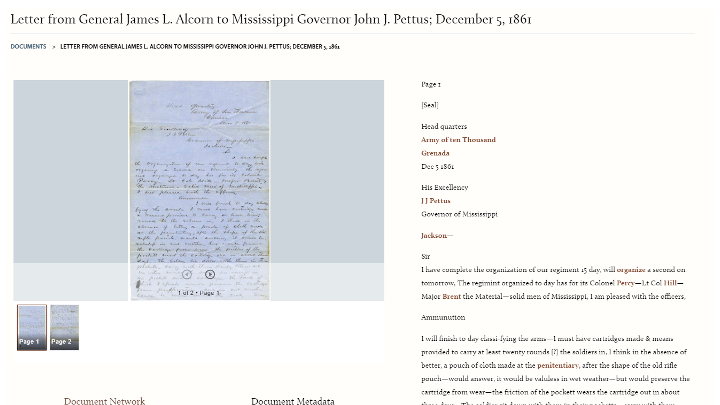
Members of the public can see the image of the document -- which is deep linked from the MDL image server -- and transcribe it in FromThePage.
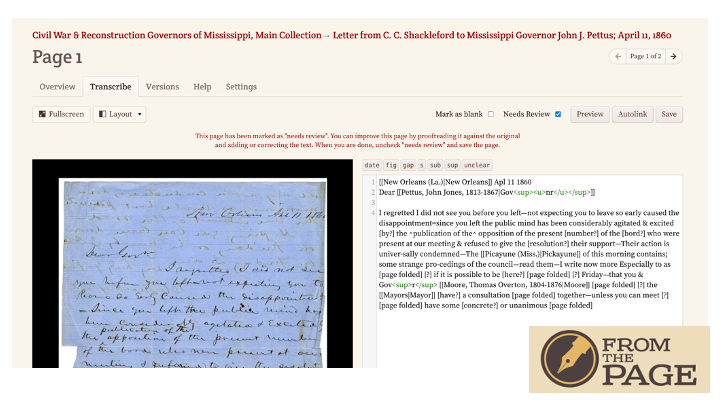
We store each edit made by the public or a staff member, so it’s easy to review who changed what using a different view within the platform.
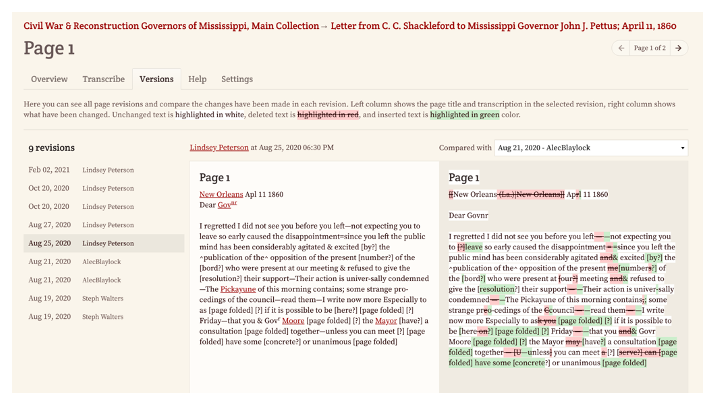
Once the public has made initial transcripts, the editorial team review their work and add scholarly annotations, identifying people mentioned within the text, like secession-era governor Pettus.

They use XML tags to mark-up features like superscript or underline and use wiki links to identify people and places mentioned in the text. These entities form subjects which will be used to index documents and let researchers navigate documents mentioning those subjects, as with this example of New Orleans.

Now the text is transcribed and annotated in the crowdsourcing platform, but needs to be published.
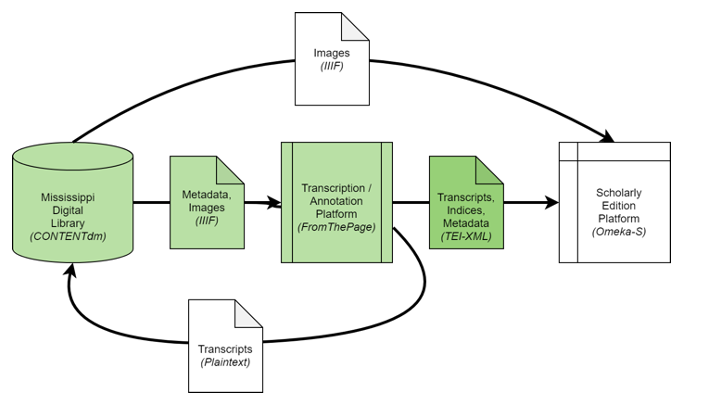
While FromThePage acts like a IIIF client to CONTENTdm, it also acts as a IIIF server. This means that any IIIF client can query our API to read from the collection of documents ready to be imported into Omeka-S.
This lists the document we’ve been discussing, along with its originating URI and a status service describing its completion

Following that link takes the client to a derivative manifest for that item, which links to the original images, but adds elements linking to all available export formats.

For scholarly editions, we want to pull the transcripts in TEI-XML. This XML standard supports extensive mark-up of features like unclear text or gaps in the text due to water damage.
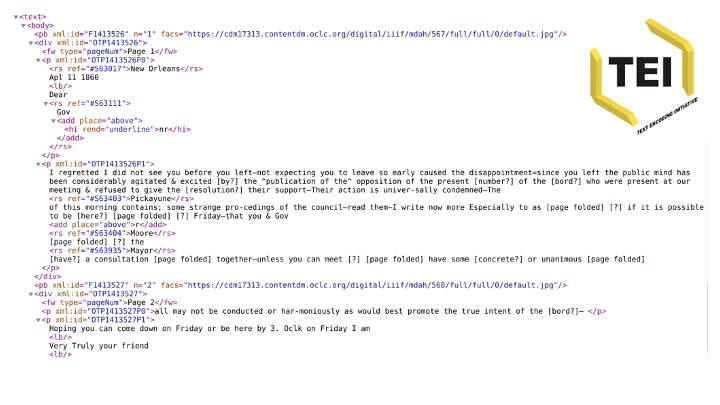
It also encodes annotation like the people and places mentioned within the text, or the contributors to the transcription process.

The TEI is imported into Omeka-S the CWRGM publication platform.
You can see what a reader does -- image, transcript, and metadata all together.

All that encoding that was done at transcription time is visible here: you can see the underlines, superscript, and expansion of the word governor.

The subjects that were tagged during annotation are now visible as metadata tags, and can be used to retrieve other documents mentioning the same person or place.

And the metadata is copied over as well.

But we don’t want to copy the images when we have IIIF!
The publication platform embeds Mirador 3 to display page images directly from the Mississippi Digital Library's image servers.

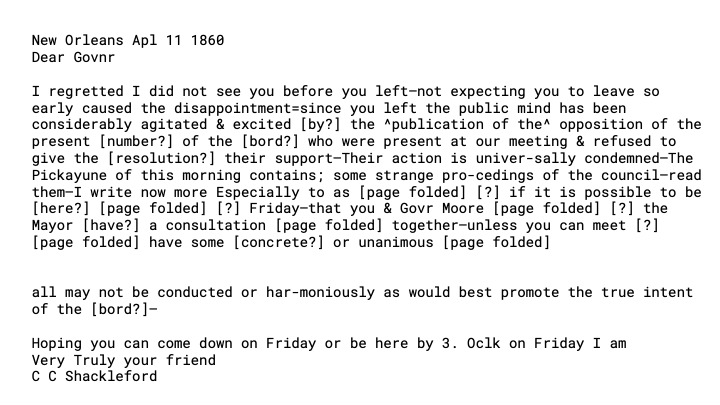
So now we have a transcript we could use to update the digital library metadata. But there's a problem. The transcript is richly annotated and includes names of contributors, tags, and other text that should not be part of a full text search.
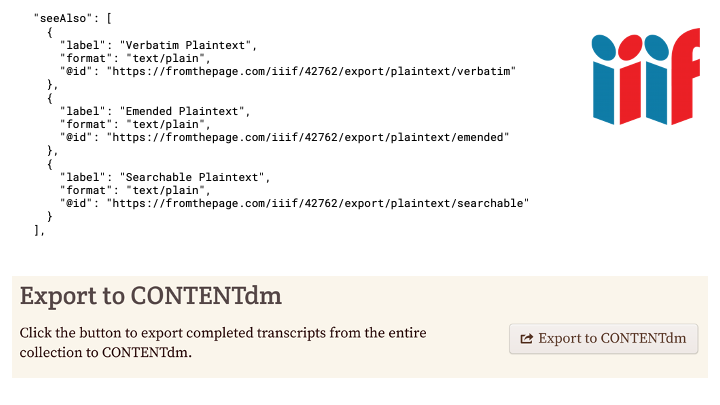
FromThePage produces plaintext transcripts that strips all these tags, or transforms them appropriately.
These are accessible via IIIF. We're also able to push them directly into CONTENTdm using the Catcher API
Future Directions
What's Next? CWRGM just launched, but we'd like to see other projects follow this model, and we think there is a lot of new potential.
Thanks to funding by the NEH, we have added PDF and MS Word exports, so it should be possible to use this approach to produce a traditional printed edition. This might enable the same kind of interoperation with digital libraries even for scholars producing letterpress editions.
The same grant will also fund a Jekyll-based static site generator. This will allow editors to export stand-alone web-pages for minimal computing needs and digital preservation.
We'll close by describing an even more distributed scholarly editing project, and the possibilities it offers for reuse.
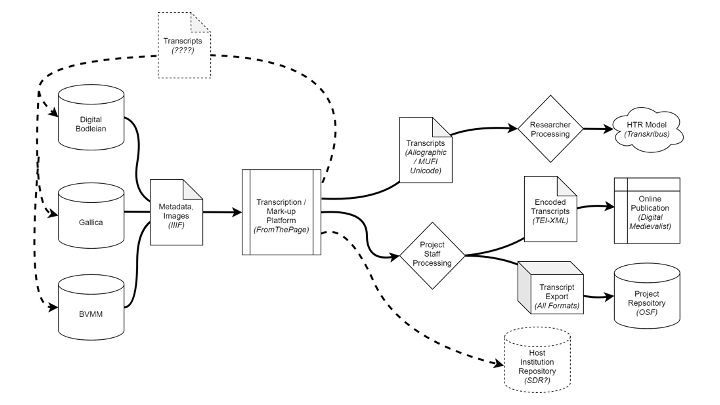
The Image du Monde Challenge gathered medievalists to transcribe the Image du Monde, a natural history and astronomical poem by Goussin de Metz. The poem exists in ten different manuscripts, and different teams transcribed each of them.

The project was hosted from Stanford, but the images themselves were hosted at three different holding institutions, each of which supports IIIF

The scholars running the project had very different publication venues and research goals.
Some of the text was submitted for publication in the Digital Medievalist.
The edition of the text itself was published online at TEI-Publisher.
The scholarly work -- the source text, but also the process documents -- were preserved on OSF.
And further scholarly products continued, with the text being used for a lemmatization workshop at the Ecole nationale des Chartes.

The plaintext export was used to train an AI model for Handwritten Text Recognition in the Transkribus platform

How can these be integrated?
Of course not all scholarly work can be re-integrated, such as these animated GIFs produced during the project, which we’ll leave you with for questions.
