
On May 25, I spoke on a panel at the Texas Conference on Digital Libraries with Liz Gushee from the Harry Ransom Center and Benjamin Albritton from Stanford University. Texas has seen little adoption of IIIF to date, and--aside from Brumfield Labs--the only participants I've seen in the community calls are the Harry Ransom Center at UT-Austin and the Jubilees Palimpsest Project at St. Mary's in San Antonio. I think that the panel was received well, and observed a lot of interest among attendees during the rest of the day.
This is a lightly edited transcript of my talk. You can also download the audio in m4a or ogg formats, or download the slide deck.


I'd like to start by introducing a couple of scholars: Laura Morreale and Nick Paul are medievalists at Fordham University. They work in the Center for Medieval Studies, focusing on Old French texts that were composed outside of metropolitan France.
Specifically, they're looking at a set of legal documents called the Assises de Jerusalem, which were written in the thirteenth century, and were the legal judgements of the Crusader court of Jerusalem. And they are fantastic documents: if you want to now the rules for trial by combat, they're in there. If you want to know what happens if a liege lord's horse tears up a vassal's stable, it's in there. It's really neat stuff.

They started working a couple of years ago, translating the full Assises from a printed edition that was produced in 1841, which was a combined/critical edition of all the texts that were available. They got through that, and what they're trying to do right now is focus on the manuscripts -- they've got a system for translating thte texts from Old French into English, but they want to go back to the original manuscripts.
They're concentrating on a particular text, the Livre au Roi, which has two witnesses. The Ms. Francais 19026 in the Bibliothèque nationale de France is a beautifully produced text, with room for initials -- it's a beautiful book. Then there's the Cod. gal. 51 in the Bayerische Staatsbibliothek, which is really more informal. This is interesting because the context that these documents in matters as much as the text itself, telling us about how these texts were received.

So a goal of the Old French Legal Texts Working Group is not just to produce translations, but to publish them in the context of the manuscripts.
But that's a challenge! First off, you have to get the images--you can't just start with something that was OCRed on the Internet Archive like the 1841 edition--and those images are in Paris and Munich, not at Fordham. How do you edit the texts is another interesting question. Finally, how do you publish those translations with their manuscript context at the same time?

Enter IIIF. IIIF is a set of standards and a community developed around those standards. It was primarily developed to solve the problem of presenting high-resolution images online. (I know that Liz and Benjamin will talk more about the background to this, so I'm going to go deeper on the technical side.)
There are two core API standards in IIIF: the Image API is just a way of serving images in a consistent manner, and the Presentation API, which is a way of saying this page follows this page; they both belong to the same book; here's the title of that book.
Two ancillary APIs are relevant for digital libraries: the Search API supports searching for OCR (primarily) within a document and presenting it, and there's an Authentication API, since not everything is freely available without restriction. Many times, libraries have to impose restrictions on the use of documents; the Authentication API supports this.
But let's go back and focus on the core APIs.

Let's talk about the Image API.
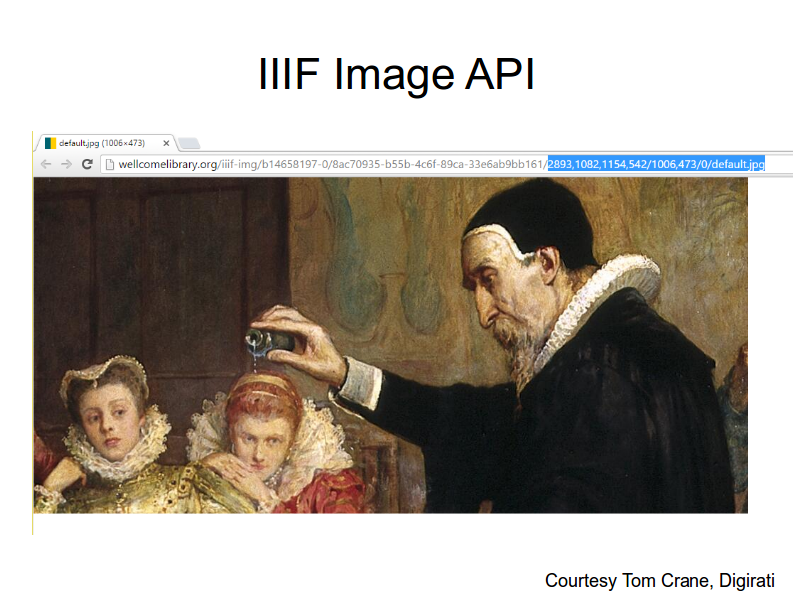
I'm going to point way up here. We've got this painting at the Wellcome library; let's take a look at this URL.
There's the Wellcome library hostname. We've got a lot of unique IDs (that look kind of horrible) that get us to this painting. But I'm going to concentrate on the pieces that are highlighted.
I'll read them out. We have /full/800,/0/default.jpg.
Everything between the slashes is meaningful.
If we change /full/ to a given width, height, and x,y coordinates, we get a section of the original image. Let me go back. [previous slide] Here's the full image. [this slide] Here's the region of the image.
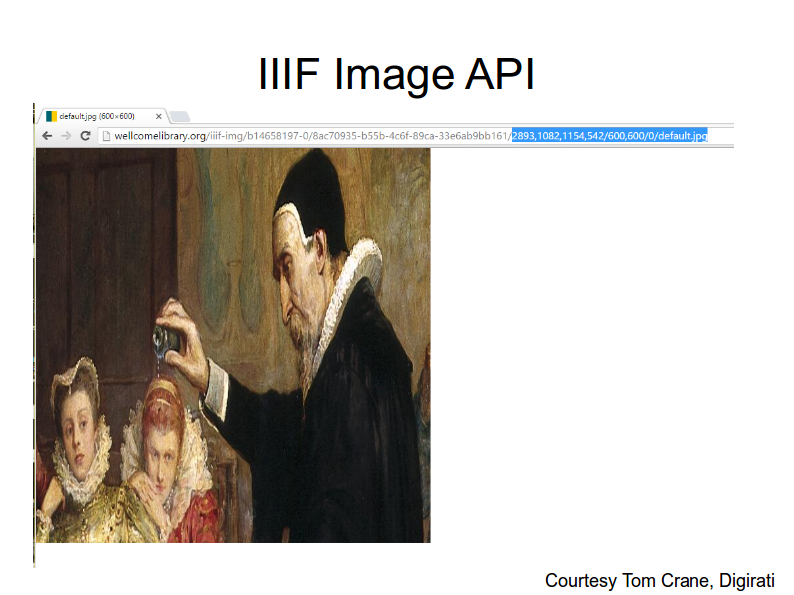
If we then pay attention to the second element of the URL--the element after the region--we can say "we really want this to be a 600x600 image. That's shrinking this down to a square and distorting the image appropriately.

Finally, we can rotate the image in the third piece of the URL by changing /0/ to /90/, rotating the image by ninety degrees.
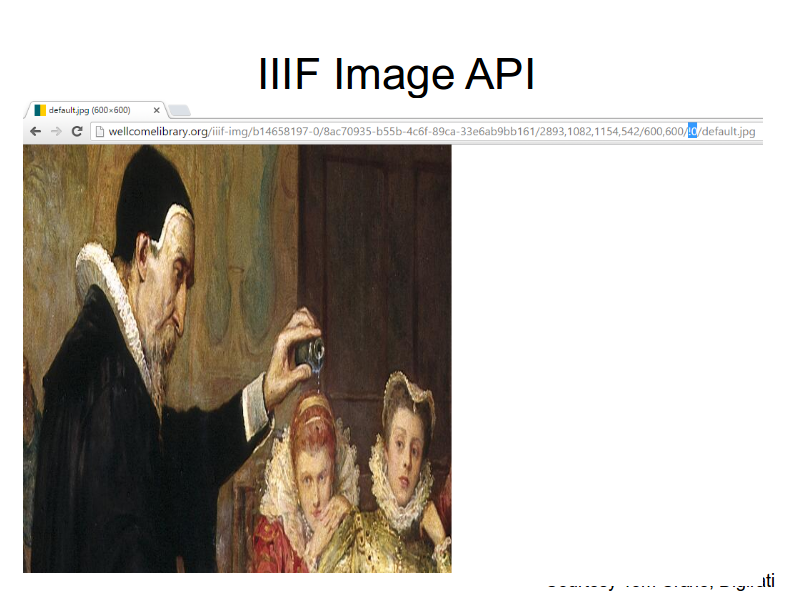
Or we can even reverse the image.
These are all things that image servers have done for years. Every image server supports functionality similar to this, if it supports deep zoom and tiling. What's unique about IIIF is this consistent way of having URLs that pull out regions, that pull out rotations, that describe size.

Let's talk about the Presentation API.
The Presentation API is a standard that is written in JSON-LD, which is a Javascript format that's very easy to parse, and very hard to read. It's designed for Linked Open Data.
The fundamental unit of the presentation API is the manifest. A manifest is, "I'm talking about an item. What's in that item?" So we have items that are manifests and we have collections that are manifests, listing the items or sub-collections in a collection.
The Presentation API is built on WebAnnotations, which is a standard that was made official about six months ago. It's something that Tim Berners-Lee is pushing really hard for.
So let's dive into a manifest!

Manifests, I mentioned, are hard to read. I mean, they're really hard to read! Here's this horrible JSON-LD file. It's unpleasant, and I hope you brought your opera glasses, because we're going to dive deep.

What's in a manifest that's important? There are core elements, namely
- The @id, which is a URL,
- The @context, which describes which version of the Presentation API standard this manifest supports,
- The @type down here, which says, "this is a manifest."
Then we have some very, very basic metadata that describes this item. So, this letter is part of a series of correspondence between German Army officials during WWI and Irish patriots talking about whether or not they could join up together against the British. It's a pretty interesting document.

I mentioned that this is a presentation API, that has limited metadata. And this is important to say. This is not a new metadata standard. This is a way of describing your objects, and then you can link to your metadata records.
So this particular manifest links off to the RDF serialization; it links off to a MODS record; it links off to a Europeana Data Model record. This allows clients to get to your metadata if they want to, but you're not duplicating your metadata within the document.

Other than, that is, the absolute bare bones that might be something a person using a page turner or a zoomer might want to see -- really, really basic stuff. Here is where it was published, when it was published, who it was published by.
(If you want to actually look at this manifest, the URL is at the bottom of this slide.)
Before I go on, I want to say, don't get too intimidated by this. No-one hand-writes these things. Manifests are usually generated by getting programmers to take an EAD file and transform it into one of these. Or they're generated by your software application -- your Hydra or Fedora or Islandora.

So then we get down to the meat. If you're displaying a manuscript book, you need to list the pages in the book. So we have a sequence of pages.
So we have a sequence, that says, "Here's the current page order, and the first page is a canvas..."

But wait a minute! What's a canvas? We're not talking about a painting; we're talking about a letter that has three pages here.
A canvas is the fundamental way that IIIF represents pages themselves.
This is a canvas. It has space; it has dimensions. And things can go onto the canvas.

Now the most important thing to go on the canvas, of course, is the image of the page. In this case, we have an image of the same page that goes on the canvas.
Why aren't these the same thing? Why would you separate them? Why have this layer of abstraction for a canvas?
Well, it's because not every page can be represented well by one image. In particular, in cases where manuscripts have been damaged and are fragmentary, you may have one fragment that has been imaged in one location, another fragment that's been imaged in a different location, and in order to display them on the page for scholars to study them, you need two images. There are also other examples of multi-image canvases where people are using RTI or ultra-violet photography to create different kinds of images [of the same page].
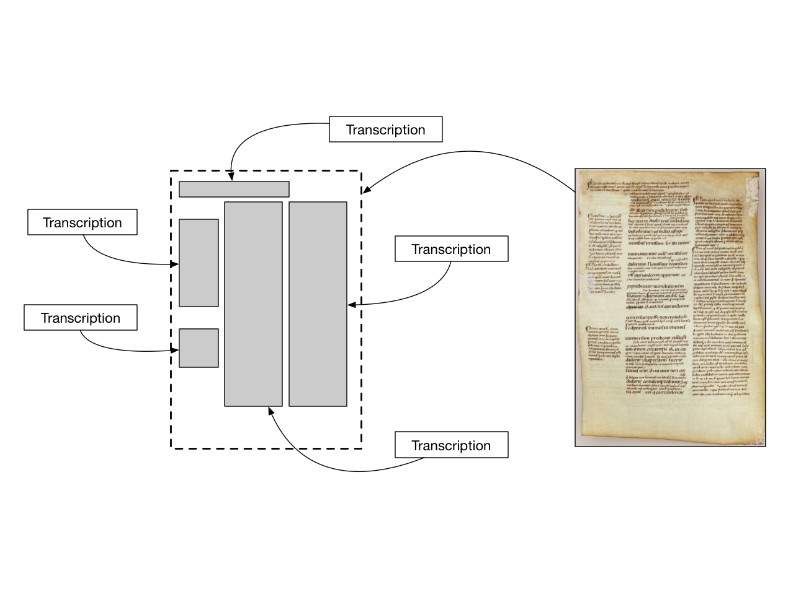
Other things can go on a canvas, like transcriptions,
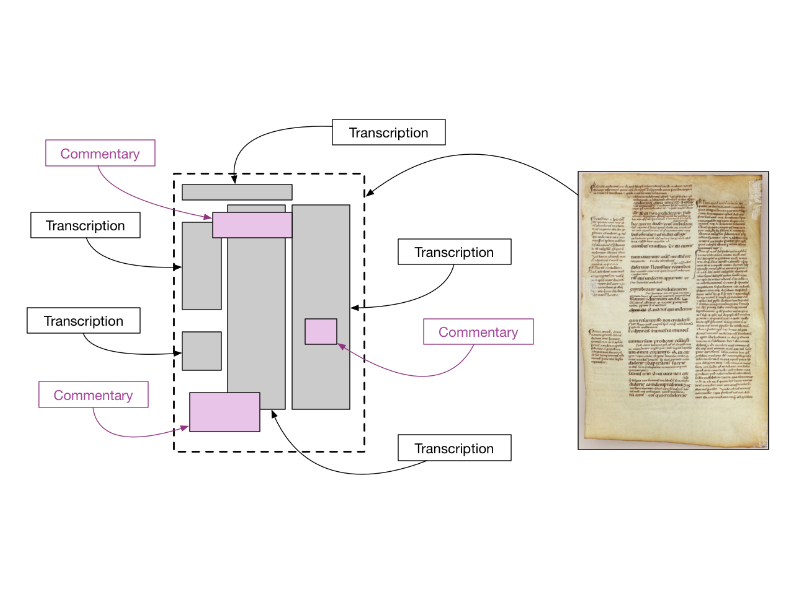
or commentary.

So, looking at one of the canvases in this document, we see that a canvas has a width; it has a height; it has a title (or a label, rather).
Then there are images, which are described as resources. What these are, are pointers to the IIIF Image API that serves this page image.

So why would you use this? I've just described a lot of hard technical stuff that doesn't seem to really buy you anything.
Fundamentally, IIIF is at the heart of a digital asset management ecosystem, because this allows your institution to work with other institutions. It allows your repository to communicate with other applications without people having to download and schlep a bunch of high-res files around. There's a really powerful community behind it.
There are people who are using IIIF internally to transform their digitization workflow. Jason Ronallo of NCSU has a fully IIIF-based workflow for scanning resources, in which IIIF resources are used to perform OCR and serve OCR back. It's really spectacular.
So these are some benefits to libraries for supporting IIIF. But what's the benefit of IIIF to me? I run an application that people use for editing documents, and here's the thing: I want to help people edit their texts. I want them to come to me with questions--and walk away happy--about how to encode difficult material; how to translate; how to annotate; how to motivate users. Before IIIF, most of my conversations were about how to upload PDFs; how to upload zipfiles; what image format [my application] needed. So IIIF allows me as a tool provider, to focus on what my tool does, rather than hosting images and worrying about disk space.

What are the benefits to scholars? Let's go back to Laura and Nick.
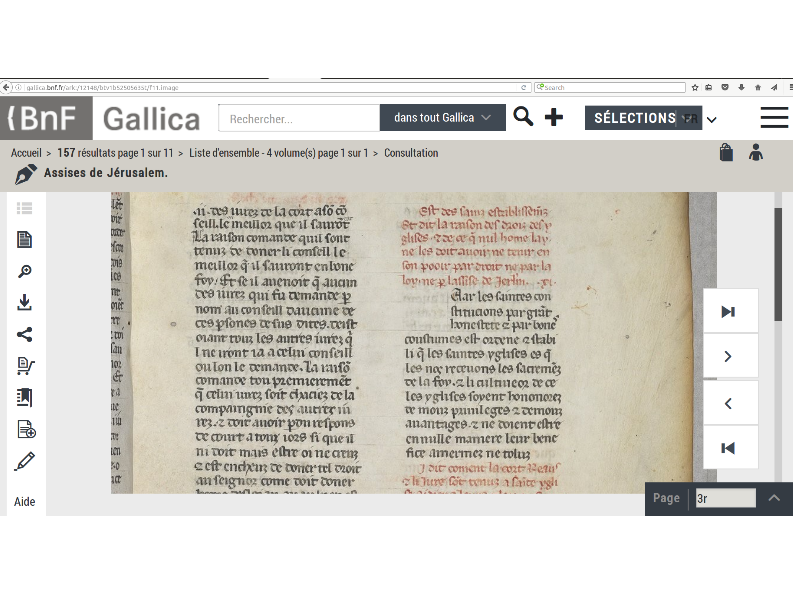
They have these documents they want to work with, and the first of them is hosted at the Bibliothèque nationale de France's digital library system, Gallica. (This is the beautiful one, that has all the space for initials.) So with a little bit of URL hacking, they can get at the manifest.
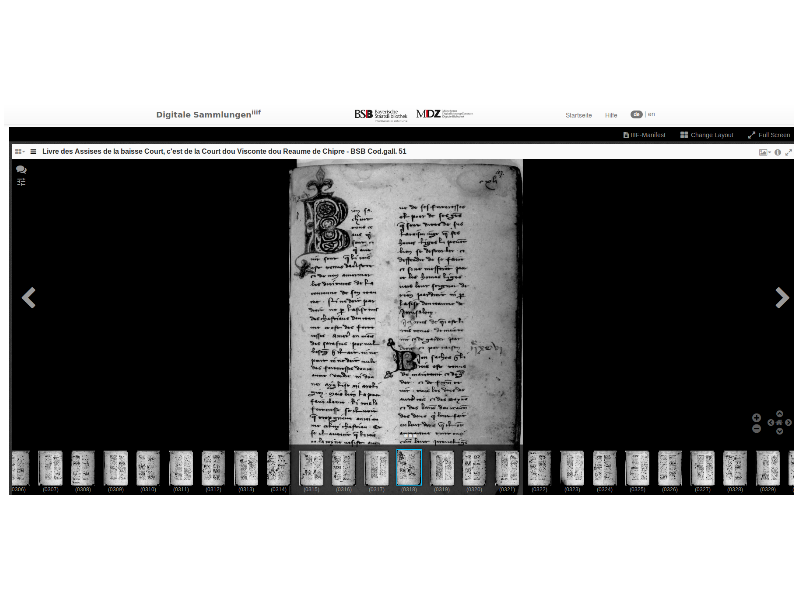
The second one, at the Bayerische Staatsbibliothek--it's hard to see on this screen, but actually it has a link to their IIIF manifest, right on their viewer. (This only went online--I'm going to say--in March, so they're a little more recent than the BnF.)
So, great! We have IIIF access to these images at the libraries.
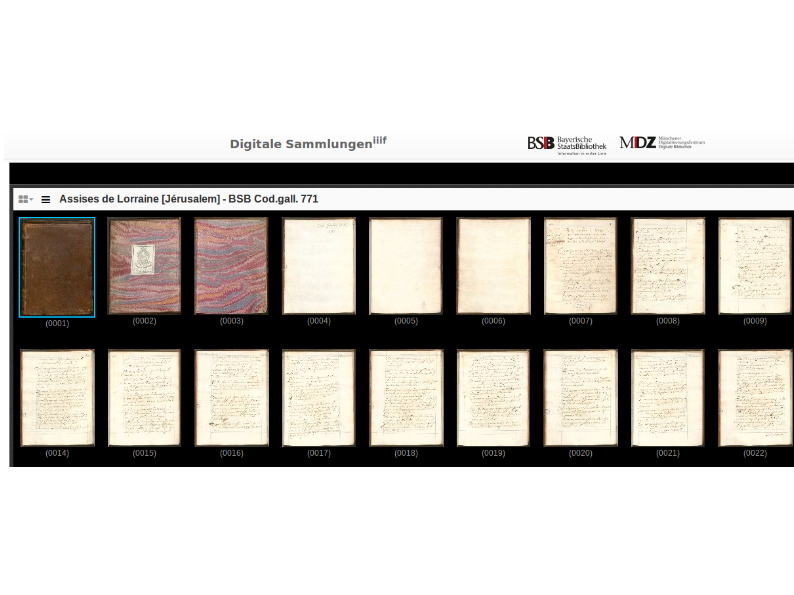
But there's a problem. Our editors want to work with one text within these documents: the Livre au Roi. And the documents are the entire codex, so you've got the cover; you've got the frontpapers; you've got a lot of other material that's not the text they want to work with. So they're going to have to edit that.
Well, in theory, they could download that manifest.json file, and edit out all the canvases they don't want, but that's horrible.

Fortunately, the Bodleian Library at Oxford has built a visual IIIF manifest editor. So all they have to do, is take that manifest from the Bayerische Staatsbibliotek and drag it into the manifest editor, and...
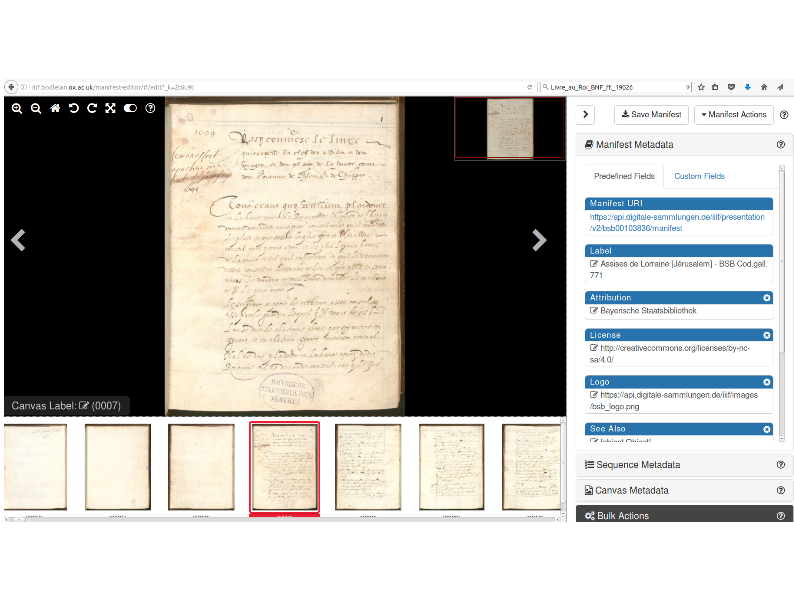
They have a visual editor in which they can delete the images they don't care about. They can reorder them. They can change the metadata. And they can save that as a new manifest.
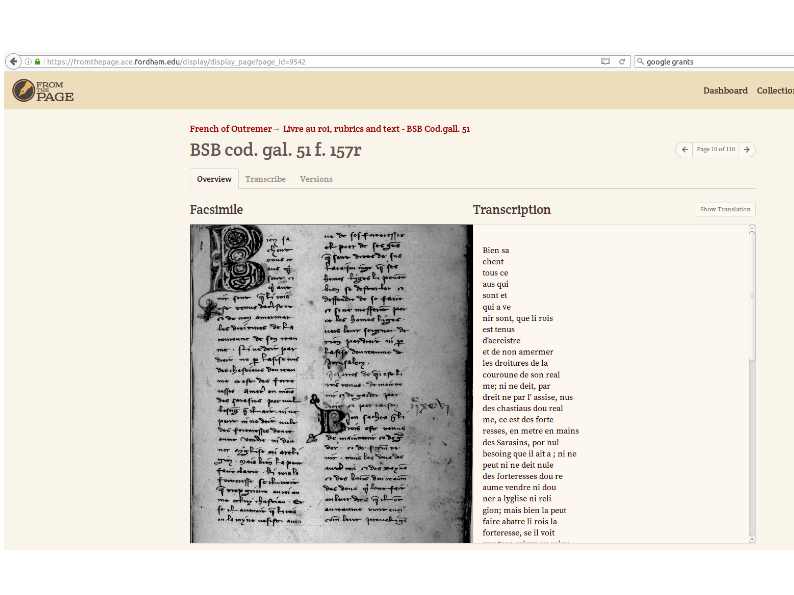
They can import it into the tool they're using for editing, FromThePage. Here, they're able to transcribe the manuscript,
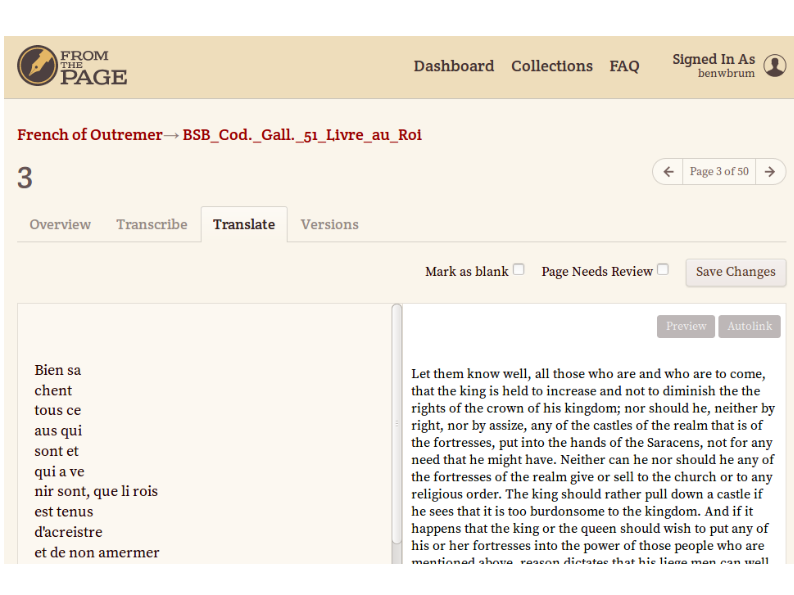
And then translate it into English.
But that still doesn't get them presentation and context. So they can take the manifests that are generated as they transcribe them in FromThePage, and their transcripts and translations then are Open Annotations.
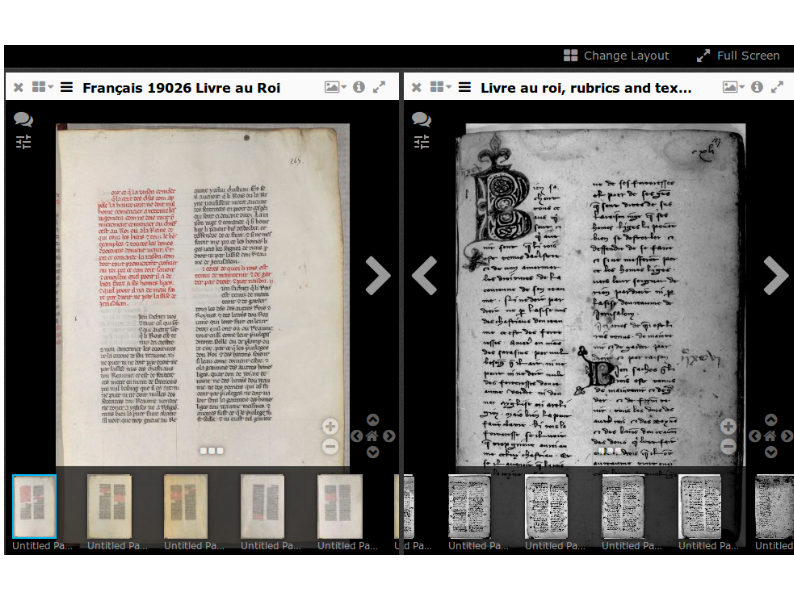
They can then import them into Mirador at Stanford.
Mirador is this wonderful tool--which Liz will talk about more--for comparing images. And if we mouseover, we get the pop-ups--I'm sorry I don't have a screenshot of this--of the translations. So you can see the translations in the context of the original images.
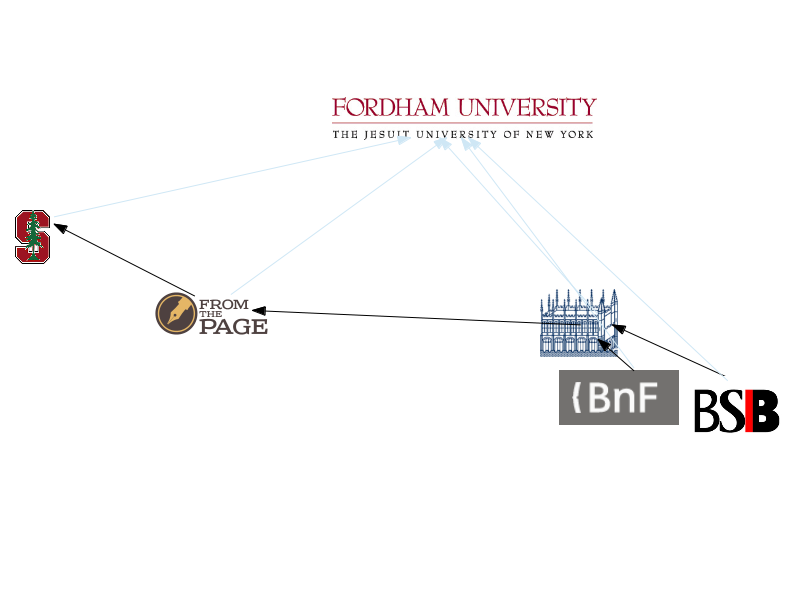
And the great thing about this--the amazing thing about this--is that you have images hosted by the Bibliothèque nationale and BSB, so we've got Paris and Munich that feed into Oxford, that feed into Austin, that feed into Stanford; all of which are used by editors in New York, and no one uploaded a single image. All the images that are being viewed in FromThePage are being served not by Fordham, not by FromThePage; they're being served directly off the image servers at the BnF and the BSB. The images being viewed in Mirador at Stanford -- again, they're being served directly from the originating libraries.
One of the things this means, is that all of that deep zoom functionality--all of that high-res functionality that those libraries provide--is being used at every stage of the process. So if the libraries, for example, have restrictions prohibiting people from doing high-resolution downloads of their original images, it doesn't matter. The scholars can still use the high-resolution images at every stage of the process, because they've never downloaded them.
Another great thing about this is, no one had to install any new software; no one had to hire any programmers; no one had to ask permission. They saw a link; they dragged it from one tool to another, to another, to another, and they got their digital scholarly edition.

Okay, that's what Fordham's doing, but Fordham's in New York City. What about Texas? What can people in Texas do with IIIF?

You can get involed. You can join the community. They're super friendly--I really encourage you to join the biweekly conference calls, join the Slack channel, take a look through the IIIF-Discuss Google Group.
You may already be IIIF enabled, because there are Digital Asset Management System vendors who are building IIIF into their systems already. There are image clients that already work wtih IIIF, including ones that were built for other purposes: the Internet Archive BookReader, for example, now works as a IIIF client.
Lots of people in Texas are using DSpace. Some people in Texas are using DSpace for special collections.
There are discussions that started about two months ago on the DuraSpace wiki about providing IIIF support in DSpace, and building it in directly. One of those discussions yielded a response from someone at a software consultancy in Italy called 4Science, that sells a ready-to-go commercial plug-in for DSpace that will support IIIF, and generate your manifests and generate your image service, just sort of right out of the box.
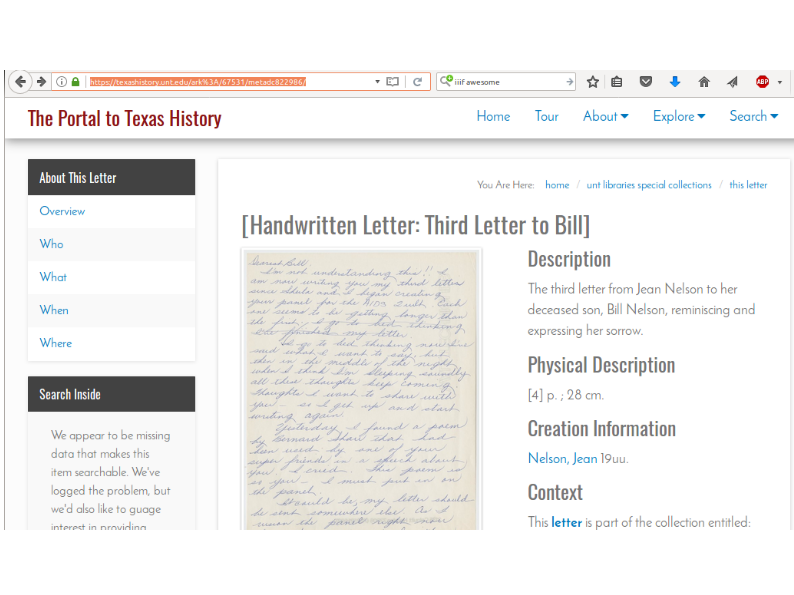
But we're not all using DSpace either. A lot of us are using the Portal to Texas History.
I am pleased to report that as of Monday, the Portal to Texas History supports IIIF -- both the Image API and the Presentation API.
So you can take any page--here's a letter from the LGBT Collections, a "Letter to Bill", talking about--it's kind of heartbreaking--It's written by a mother to her son who's died of AIDS--about what she's doing with the AIDS Quilt.
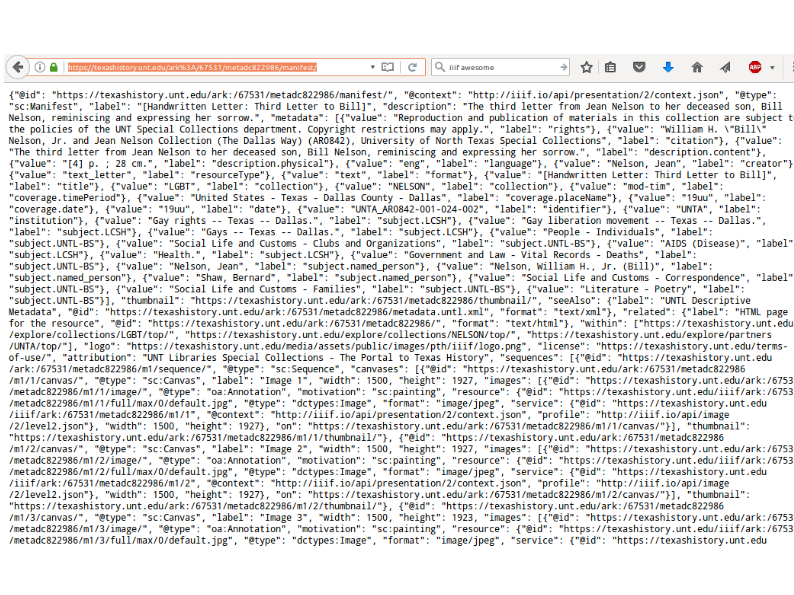
So we take the URL on the Portal site, and if you add /manifest at the end of that, you have a IIIF manifest, which you can cut-and-paste.
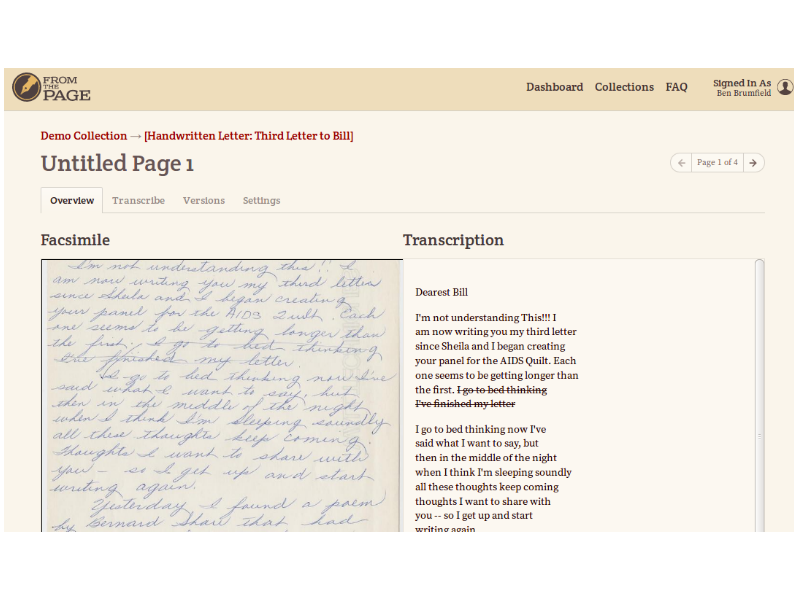
You can import it into a IIIF editing tool like FromThePage to transcribe it.
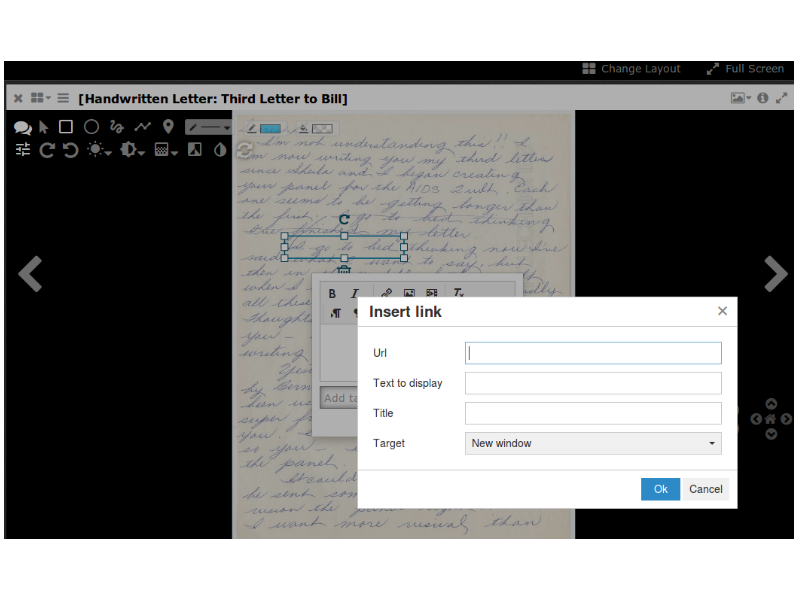
You can import it into an annotation tool like Mirador, and get people to add links directly onto the image with a link to the square on the AIDS Quilt, for example.
It's really powerful, and it's right there, and it's available this week.
Thanks!
If you or your organization would like to know more about IIIF, Brumfield Labs offers a 1 hour Introduction to IIIF webinars at no cost. Send an email to benwbrum@gmail.com.