
You can access the IIIF API of a private collection using our key based API. Querying public collections does not need an API key.
You can download bulk export zip files containing page and work level transcripts and translations via our key based API. You'll need a key even if your collection is public.
To get a key:
- Log in to FromThePage and make sure your account has access to the private collections you'd like to export by clicking on the "Dashboard" link.
- Click on "Your Profile" under the "Signed In As..."
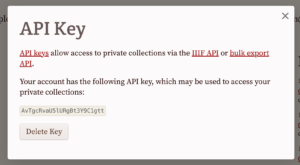
- Click "API Keys" button on the upper right.
- Click "Generate Key"
- Copy the key you just generated. (You can always find it again under your profile.)

To query the IIIF API, use your key:
curl -H 'Authorization: Token token=KEY' 'COLLECTION_URL'
where KEY is your key and COLLECTION_URL is the IIIF collection URL found on the collection export tab in the user interface.
for example:
curl -H 'Authorization: Token token=AvTgcRvaU5lURgBt3Y9C1gtt' 'https://fromthepage.com/iiif/collection/4'
To initiate a bulk export API:
curl -H 'Authorization: Token token=KEY' -X POST "https://fromthepage.com/api/v1/bulk_export/collection-slug?option1=true&option2=true
Where the collection-slug is the part of the collection url (find it in the settings page for the collection, or just look at the URL for the collection). Options are different types of files to be included in your export zip file. You must have at least one. You may have all options. The following are valid options for the formats included in the export file:
plaintext_verbatim_page plaintext_verbatim_work plaintext_emended_page plaintext_emended_work plaintext_searchable_page plaintext_searchable_work tei_work html_page html_work subject_csv_collection subject_details_csv_collection table_csv_collection table_csv_work
For example, the following API call will start an export a plaintext verbatim file for each work in the collection and one plaintext verbatim file for each page in the collection, organized into folders by work.
curl -H 'Authorization: Token token=4e258CaCK71WWrQS13PP4gtt' -X POST "http://localhost:3000/api/v1/bulk_export/east-civil-war-letters?plaintext_verbatim_page=true&plaintext_verbatim_work=true"
This will return:
{
"id":26,
"status":"queued",
"status_uri":"https://fromthepage.com/api/v1/bulk_export/26/status",
"download_uri":"https://fromthepage.com/api/v1/bulk_export/26/download"
}
To monitor the status of your export, take the ID that is returned from that request and use it in the status API call:
curl -H 'Authorization: Token token=4e258CaCK71WWrQS13PP4gtt' 'http://localhost:3000/api/v1/bulk_export/ID/status'
Once the status is complete, like so:
{
"id":25,
"status":"finished",
"status_uri":"http://fromthepage.com/api/v1/bulk_export/25/status",
"download_uri":"https://localhost:3000/api/v1/bulk_export/25/download"
}
You can download the export file using the URL in the response:
curl -H 'Authorization: Token token=4e258CaCK71WWrQS13PP4gtt' 'https://fromthepage.com/api/v1/bulk_export/14/download' --output out.zip