
In a recent discussion on BlueSky, Ben and Scott Weingart (and others) had a conversation about the explosion of possibilities that might come from good, cheap, AI transcription. Scott asks “how the bias of the spotlight of what’s searchable will reshape how people will engage with the past. That is, how will history be remembered and written in new ways, and privileging what new voices?”

We’ve been meeting with librarians who are using Gemini 3 AI Drafts in FromThePage, asking about their observations and looking for examples of "weird results" or surprising successes. Here are some of our observations.
Financial records and account books are much easier to transcribe
Every early article on Gemini 3 transcription talked about how it did the math to check transcriptions of accounting records. At first I thought this was just an outlier – yeah, ok, whatever: it does math. Here’s the deal. The math isn’t what really matters. What matters is that Gemini is more than willing to transcribe historic accounting records. What we know from years of crowdsourcing projects (and our involvement with scholars editing financial records) is that humans aren’t. When Gemini does an initial transcription – including the tedious table encoding that’s needed to make financial records analyzable – humans are willing to review and correct the interesting bits, like what people are buying or selling or inheriting.
We think this will encourage some distinct trends in historical research – big-picture economic histories like Caitlyn Rosenthal’s Accounting for Slavery or Bonnie Martin’s work on slave mortgages will be much easier, but we might also see improvements in small-scale projects like property history at house museums.
Low-quality documents are easier to transcribe
Do you like reading scanned microfilm documents? Yeah, neither does anyone else. While there have always been some dedicated researchers and volunteers who transcribe these documents, many of us avoid them because they are challenging to read, even if they aren’t handwritten. What we’ve seen with material like the Letters of the Office of Indian Affairs from the Los Angeles County Library is that Gemini transcription is very good.

Gemini doesn’t care if the text is blurry or harder to read than a nice digital photograph. We saw similar results from Transkribus on documents with a lot of bleed-through – humans had trouble deciphering the text, but the AI system did not.

LLMs are better at OCR than OCR
While FromThePage has historically focused on handwritten material, folks are using us – and Gemini – on typographic material as well. The Ayn Rand Archives uploads typewritten drafts with handwritten edits. Their volunteers don’t like wasting their time if a computer can generate a good draft for them, but find their edits are still important.
Iowa State has uploaded early agricultural catalogs, and are comparing the Gemini results with the original OCR. Guess what? Gemini wins, both for text and a readable layout.

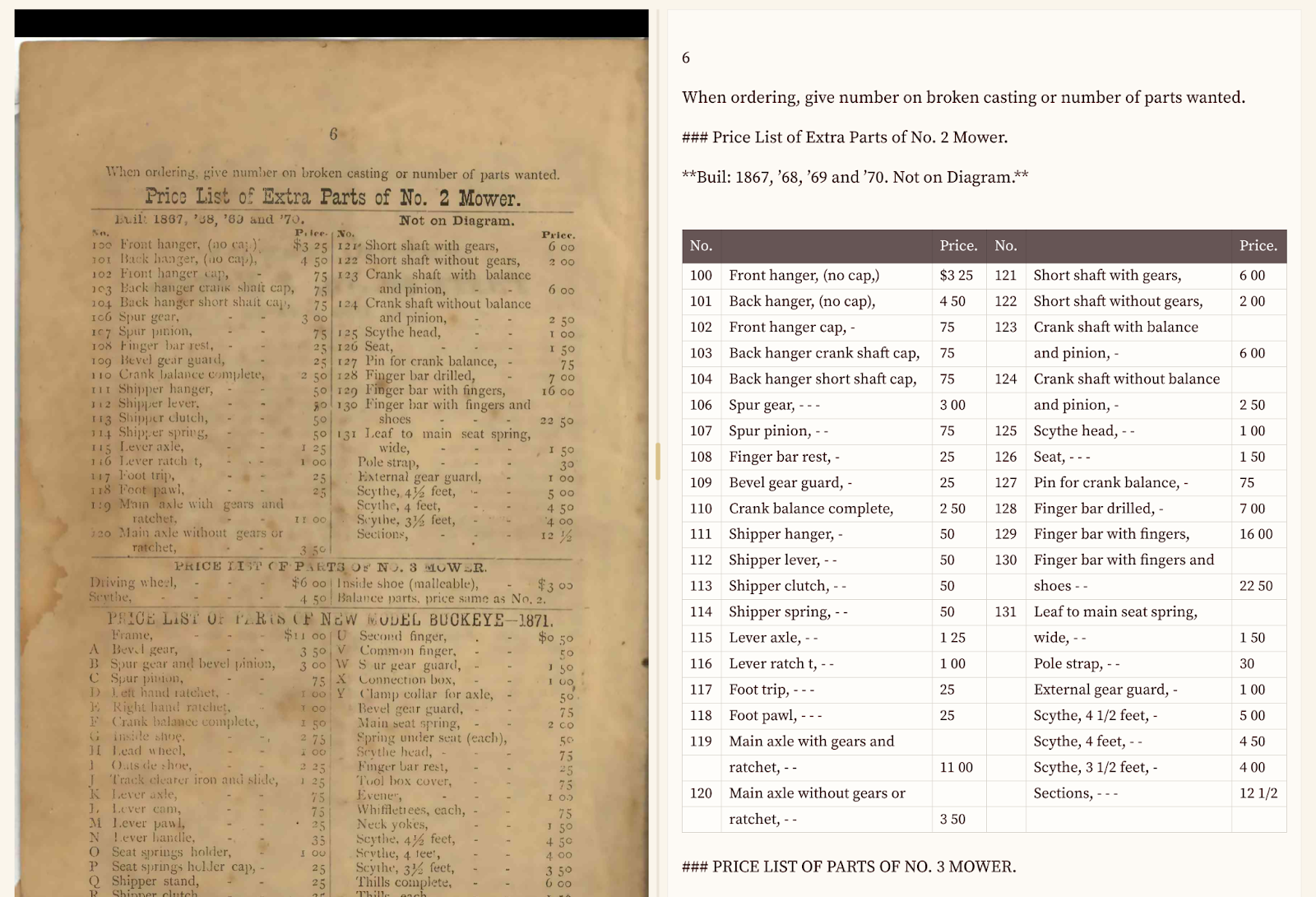
The burden of not having to decide where or how to encode handwritten annotations or a two column table from a farm implement catalog also makes the work of transcription easier. What the AI does is likely “good enough” (and if it isn’t, we refine prompts until there’s a good enough standard).
Typographic Facsimiles
Gemini really wants to make transcriptions match the page layout. It will jump through hoops to add spaces or HTML non-breaking space (“ ”) characters to center titles and right-justify dates to make a transcription look like the image. But it will also turn structured data into markdown tables – something we’ve always supported but is very onerous for humans to do. We’re already starting to see more volunteer activity on historic accounts because the burdensome layout is done by AI.
Sometimes this backfires on us – like a middle English poem in two columns that – because of underlines in the text, perhaps? – Gemini encoded a table. The table output looked OK visually, but made no sense when read or edited. We had to refine our prompt to explicitly state that text should be in reading order but financial records should be in tables.

In the Iowa State catalog example, the table layout was perfect for sighted humans looking at the image and the text, but wouldn’t work at all for screenreaders. We’d need – and are starting to think about – new derivatives for accessibility in places where these new typographic facsimiles might not serve a vision-impaired audience in the same way that our older “just type what you see” transcriptions did.
All of this will affect the future of research – because as Scott says “what’s searchable will reshape how people will engage with the past.” But it’s also changing what we’re working on in FromThePage. We need to display whitespace because it’s an important part of the transcription. And our table exports are getting a work-out, and needing focus in a way they haven’t before. And wide tables means our “image on left, reading version on right” gets cut off. We’re not complaining – but it’s interesting to see the snowball effect of introducing Gemini drafts has on the work we do, just three months after introducing it.