
This is a transcript of my talk at the 2012 TEI meeting at Texas A&M University, "What does it mean to 'support TEI' for manuscript transcription: a tool-maker's perspective."

You can download an MP3 recording of the talk here.

Let's get started with a couple of definitions. All the tools and the sites that I'm reviewing are cloud based, which means that I'm ruling out--perhaps arbitrarily--any projects that involve people doing offline edition and then publishing that on the web. I'm only talking about online-based tools.
So that's a very strict definition of clouds, and I'm going to have a very loose and squishy definition of crowds, in which I'm talking about any sort of tool that allows collaborative editing of manuscript material, and not just ones that are directed at amateurs. That's important for a couple of reasons: one, because it gave me a sample size that was large enough to find out how people are using TEI, but--for another reason--because "amateurs" aren't really amateurs. What we see with crowdsourcing projects is that amateurs become experts very quickly. And given that your average user of any citizen science or historical crowdsourcing project is a woman over 50 who has at least a Master's degree, this isn't sort of the unwashed masses.

Okay, so crowdsourced transcription has been going on for a while, and it's been happening in four different traditions that developed this all independently. You have genealogists who are doing this, primarily with things like census records. The 1940 census is the most prominent example: they have volunteers transcribing as many as ten million records a day. The natural sciences are doing something similar, particularly GalaxyZoo, the OldWeather people are looking at climate change data, where you have to look at old, handwritten records to figure out how the climate has changed, because you need to know how the climate used to be. And then there are also some projects going on in the Open Source/Creative Commons world: the Wikisource people--particularly the German language Wikisource community--and libraries, archives, and museums have jumped into this recently.

So here are a couple of examples from the citizen science world. OldWeather has a tool that allows people to record ship log book entries and weather observations. As you can see, this is all field based -- this isn't quite an attempt to represent a document. We'll get back to this in a minute.

The North American Bird Phenology Program is transcribing old bird[-watching] observation cards from about a hundred years ago. They're recording species names and all sorts of other things about this particular Grosbeak in 1938.

All of these--this is the majority of the crowdsourced transcription that's happening out there--there are millions of records--there are millions of records that are happening that are all record based. These are not document-based, they aren't page-based. They're dealing with data that is fundamentally tabular -- those are their inputs. Their outputs are databases that they want to be able to either search or analyze. So we're producing nothing that anyone would ever want to print out.
And another interesting thing about this is that these record-based transcription projects--the uses are understood in advance. If you're building a genealogy index, you know that people are going to want to search for names and be able to see the results. And that's it -- you're not building something that allows someone to go off and do some other kind of analysis.
Now what kind of mark-up are these record-based transcription projects using? Well, it's kind of idiosyncratic, at best.

Here's an example from my client FreeREG. This is a mark-up language that they developed about ten years ago for indicating unclear readings of manuscripts. It's actually fairly sophisticated--it's based on the regular expression programming sub-language--but it's not anything that's informed by the TEI world.
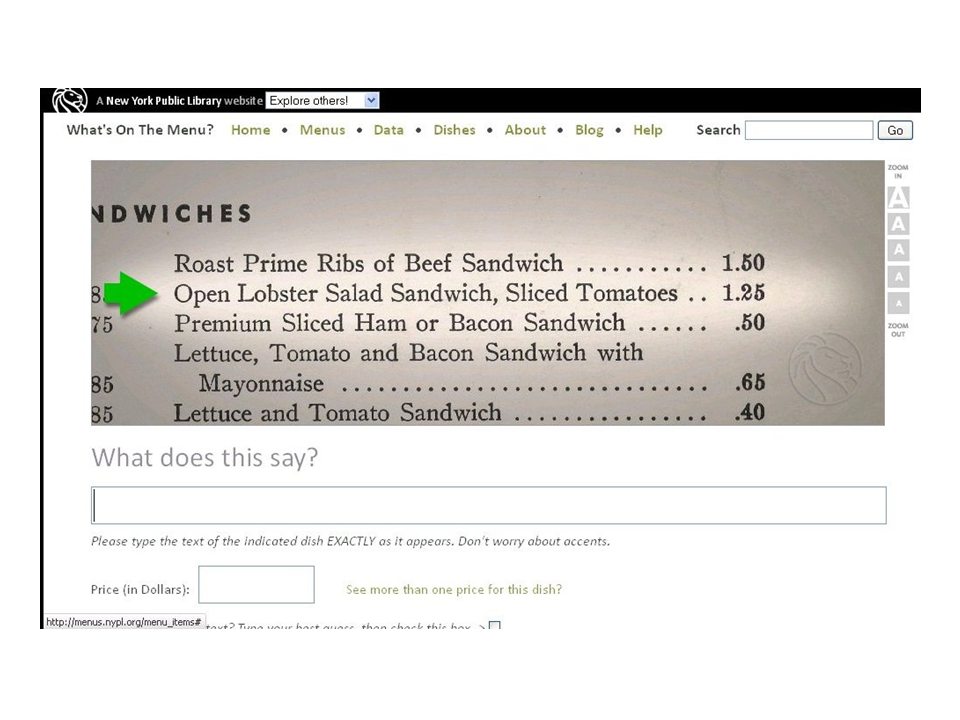
On the other hand, here is the mark-up that the New York Public Library is using. Let me read this out to you: "Please type the text of the indicated dish exactly as it appears. Don't worry about accents." This is almost an anti-markup.

So what about free-form transcription? There's a lot of development of people doing free-form transcription. You have Scripto out of CHNM. You have a couple of different (perhaps competing) NARA initiatives. Wikisource. There's my own FromThePage. What kind of mark-up are they doing? Well, for the most part, none!

Here's Scripto--the Papers of the War Department-- and you type what you see, and that's what you get.

Here is the French-language Wikisource, hosting materials from the Archives departmentales du Cantal (who are doing some very cool things here). But this is just typing things into a wiki and not even internally using wiki links. This is almost pre-formed text -- it's pretty much plaintext.

My own project, FromThePage.

I'm internally using wiki-links, but really only for creating indexes and annotations, not for indicating...any of the power that you have with TEI.

So if no one is using TEI, why is TEI important? I think that TEI is important because crowdsourced transcription projects are how the public is interacting with edition. This is how people are learning what editing is, what the editing process is, and why and whether it's important. And they're using tools that are developed by people like me. Now how do people like me learn about edition?

The answer is, by reading the TEI Guidelines. The TEI Guidelines have an impact that goes far beyond people who are actually implementing TEI. I started work on FromThePage in complete isolation in 2005. By 2007, I was reading the TEI Guidelines. I wasn't implementing TEI, but the questions that were asked--these notions of "here's how you expand abbreviations", "here's how you regularize things"--had a tremendous impact on me. By contrast, the Guide to Documentary Editing--which is a wonderful book!--I only found out in January of this year.
TEI is online, it's concise, it's available. And when I talk to people in the genealogy development world, they know about TEI. They've heard of it. They have opinions. They're not using it, but -- you people are making an impact on how the world does edition!

Okay, so if all of these people aren't using TEI, who is doing it?
I run a transcription tool directory that is itself crowdsourced. It's been edited by 23 different people who've entered information about 27 different tools. Of those 27 tools, 7 are marked as "supporting TEI". There's a little column, "does it support TEI?", seven of them say "Yes".
Actually, that's not true. Some of them say "yes", but some of those seven say "well, sort of". So what does that mean?

To find that out, I interviewed five of those seven projects.
- Transcribe Bentham.
- T-PEN (which there's a poster session about tonight), which is a line-based system for medieval manuscripts.
- A customization of T-PEN, the Carolingian Canon Law project, out of the University of Kentucky.
- Our own Hugh Cayless for the Papyrological Editor, which is dealing with papyri.
- And then MOM-CA is one of these "sort of"s. You have two implementations of it.
- One of them is the Virtualles deutsches Urkundennetzwerk, which is a German charter collection. It supports "TEI, sort-of" -- actually it supports CEI and EAD.
- But it's been customized for extensive TEI support for the Itinera Nova project which is out of the archive of Leuven, Belgium.

I'm going to talk about what I found out, but I'm going to emphasize Transcribe Bentham. Not because it's better than the other tools, but because they actually ran their transcription project as an experiment. They wanted to know, can the public do TEI? Can the public handle it? And they've published their results: they've conducted user surveys of what was your experience using TEI? Which makes it particularly useful for those of us who are trying to figure out how it's being used.

Okay, so there's a lot of variation among these projects. You've got a varied committment to TEI. Transcribe Bentham: Yes, we're going to use TEI! You see Melissa Terras here saying that "it was untenable" that we'd ask for anything else. These people know how to do it; why would we depart from that?
For T-PEN, James Ginther says: Hey, I'm kind of skeptical. We'll support any XSD you want to upload, if it happens to be TEI, that's okay.

Abigail Firey, who's using T-PEN, basically says: look, it's probably necessary. It's very useful. It lets us develop these valuable intellectual perspectives on our text. And she considered it important that their text encoding was done within the community of practice represented by the people in this room.

Okay, so more variation between these. Where's the TEI located within these projects? Where does it live? I'm a developer; I'm interested in the application stack.
It turns out that there's no agreement at all. Transcribe Bentham has people entering TEI in person. And then it's storing it off in a MediaWiki, using MediaWiki versioning, not actually putting [...] pages in one big TEI document.
On the other hand, Itinera Nova is actually storing everything in an XRX-based XML database. I mean, it is pure TEI on the back end. But none of the volunteers using Itinera Nova actually are typing any angle brackets. So we have a lot of variation here.

However, there was no variation when I asked people about encoding. There is a perfectly common perception that is: Encoding is hard!
And there are these great responses--that you can see both on the Transcribe Bentham blog and in their DHQuarterly paper that just came out, which I highly recommend--describing it as "too much markup", "unnecessarily complicated", "a hopeless nightmare", and the entire transcription process is "a horror."

But, lots of things are hard.
In my own experience with FromThePage, I have one user who has transcribed one thousand pages, but she does not like using any mark-up at all. She's contributing! She's contributing plaintext transcriptions, but I'm going back to add wikilinks. So it's not about the angle brackets. (Maybe square brackets have a problem too, I don't know.)
And fundamentally, transcribing--reading old manuscripts--is hard. "Deciphering Bentham's hand took longer than encoding," for over half of the Bentham respondents.

So there's more commonality: everyone wants to make encoding easier. How do we do that? There's a couple of different approaches. One approach--the most common approach--is using different kinds of buttons and menus to automate the insertion of tags. Which gets around (primarily) the need for people to memorize tag names and attributes, and--God help us--close tags.
So these are implemented--we've got buttons on T-PEN and CCL. We've got buttons on the TEI Toolbar. We've got menus on VdU and the Papyrological Editor.

And you can see them. Here's a screenshot of Jeremy Bentham. A couple of interesting things about this: it's very small, but we've got a toolbar at the top. We've got TEI text: angle-bracket D.E.L. Angle-bracket, slash, D.E.L. So we're actually exposing the TEI to users in Transcribe Bentham, though we're providing them with some buttons.

Those buttons represent a subset--I'll get to the selection of those tags later. Here's a more detailed description of what they do.

Here's what's going on with VdU. Only in this case, they're not actually exposing the angle brackets to the user. They're replacing all of these in a pseudo-WYSIWYG that allows people to choose from a menu and select text that then gets tagged.

Okay -- limitations of the buttons. There's a good limitation, which is that as users become more comfortable with TEI, they outgrow buttons. And this is something that the people at Transcribe Bentham reported to me. They're seeing a fair number of people just skip the buttons altogether and type angle brackets. Remember: these are members of the public who have never met any of the Transcribe Bentham people.
On the down side, users also ignore the buttons. Again users ignoring encoding, but in this case we've got something that's a little bit worse. Georg Vogeler is reporting something very interesting, which is that in a lot of cases, they were seeing users who were using print apparatus for doing this kind of work, and just ignoring the buttons -- going around them.

So the problem with using print-style notations. People are dealing with these print editions [notations] -- this can be a problem or it can be an opportunity. Papyri.info is viewing it that way. Itinera Nova is using it that way.

Papyri.info, their front-end interface for most users is Leiden+, which is a standard for marking up papyri. And, as you can see, users enter text in Leiden+, and that generates TEI. (EpiDoc TEI, I believe.)

This is the same kind of process that's done in Itinera Nova. In that case, they're using for notation whatever it is that the Leuven archives uses for their mark-up. And they're doing the same kind of transposition [ed: translation] of replacing their notation with TEI tags before they save it.

And this is actually what users see as they're typing. They don't see the TEI tags -- we're hiding the angle brackets from them.
So this is an alternative to buttons. And in my opinion, it's not that bad an alternative.

This hasn't been a problem for the Bentham people, however. It's a non-problem for them. And they are the most "crowdy", the most amateur-focused, and the most committed to a TEI interface.
Tim Causer went through and reviewed all of this and said, you know, it just doesn't happen. People are not using any print notation at all. They're using buttons. They're using angle-brackets by hand. They're not even using plaintext. They're using TEI. Their users are comfortable with TEI.

So what accounts for the difference between the experience of the VdU and the Transcribe Bentham people? I don't know. I've got a couple of theories about what might be going on.
One of them is really the corpus of texts we're working with. If you're only dealing with papyrus fragments, and you're used to a well-established way of notating them--that's been around since 1935 in the case of Leiden+--well, it's kind of hard to break out of that. On the other hand, there's not a single convention for print editions. There's all sorts of ways of indicating additions and deletions for print editions of more modern texts. So maybe it's a lack of a standard.
Or, maybe it's who the users are. Maybe scholars are stubborner, and amateurs are more tractable and don't have bad habits to break. I don't know! I don't know, but I'd be really interested in any other ideas.

Okay, how do these projects choose the tags that they're dealing with? We've got a very long quote, but I'm just going to read out a couple of little bits of them.
Really, choosing a subset of tags is important. Showing 67 buttons was not a good usability thing for T-PEN. And in particular, what they ended up doing was getting rid of the larger, structural set of markup, and focusing just on sort of phrase-level markup.
This also, I think, true if we go back a minute and look at Bentham. Here, again, we're talking phrase-level tags. We're not talking about anything beyond that.

Justin Tonra said that it was actually really hard to pare down the number of tags for Transcribe Bentham. He wanted to do more, but, you know, he's pleased with what they got. They didn't want to "overcomplicate the user's job."

Richard Davis, also with Transcribe Bentham, had a great deal of experience dealing with editors for EAD and other XML. And he said you're always dealing with this balance between usability and flexibility, and there's just not much way of getting around it. It's going to be a compromise, no matter what.

So what's the future for these projects that are using TEI for crowds? Well, if getting people up to speed is hard, and if nobody reads the help--as Valerie Wallace at one time said about their absolutely intimidating help page for Transcribe Bentham (you should look at it -- it's amazing!)--then what are the alternatives for getting people up to speed?
Georg Vogeler says that they are trying to come up with a way of teaching people how to use the tool and how to use the markup in almost a game-like scenario. We're not talking about the kind of Whak-a-Mole things that we sometimes see, but really just sort of leading people through Let's try this. Now let's try this. Now let's try this. Okay now you know how to deal with this [tool]. It's something that I think we're actually pretty familiar with from any other kinds of projects dealing with historic handwriting.: people have to come up to speed.

Another possibility is a WYSIWYG. Tim Causer announced the idea of spending their new Mellon grant on building a WYSIWYG for Transcribe Bentham's TEI. The blog entry is fascinating because he gets about seven user comments, some of which express a whole lot of skepticism that a WYSIWYG is going to be able to handle nested tagging in particular. Other ones of which make comments about the whole XML system and its usability in vivid prose, which is very worth reading.

And maybe combinations of these. So we have these intermediate notations -- Itinera Nova, for example, they're using this let's begin a strike-through with an equals sign (which is apparently what they've been using at that archive for a while). And the minute you type that equals sign in, you actually get a WYSIWYG strike-through that runs all the way through your transcript.
That may be the future. We'll see. I think that we have a lot of room for exploring different ways for handling this.

So let me wrap up and thank my interviewees.
Transcribe Bentham: Melissa Terras, Justin Tonra, Tim Causer, Richard Davis.

T-PEN: James Ginther, Abigail Firey
Papyri.info: Hugh Cayless, Tom Elliot
MOM-CA: Georg Vogeler and Jochen Graf

Questions
[All questions will be paraphrased in the transcript due to sound quality, and are not to be regarded as direct quotations without verification via the audio.]
Syd Bauman: Of the systems which allow users to type tags free-hand, what percentage come out well-formed?
Me: The only one that presents free-hand [tagging] is Transcribe Bentham. Tim [Causer] gets well-formed XML for most everything he gets. There is no validation being performed by that wiki, but what he's getting is pretty good. He says that the biggest challenge when he's post-processing documents is closing tags and mis-placed nesting.
Syd Bauman: I'd be curious about the exact percentages.
Me: Right. I'd have to go back and look at my interview. He said that it represents a pretty small percentage, like single digits of the submissions they get.
John Unsworth: Do any of the systems use keyboard short-cuts?
Me: I know of none that use hot-keys.
John Unsworth: Do you think that would be more or less desirable than the systems you've described?
Me: I really only see hot-keys as being desirable for projects that are using more recent and clearer documents. Speed of data-entry from the keyboard perspective doesn't help much when you're having to stare and zoom and scroll on a document that is as dense and illegible as Bentham or Greek papyri.
Elena Pierazzo [very faint audio]: In some cases it's hard to define which is the error: choosing the tags or reading the text. I've been working with my students on Transcribe Bentham--they're all TEI-aware--and to be honest it was hard. The difficulty was not the mark-up. In a sense we do sometimes forget in these crowdsourcing projects, that the text itself is very hard, so probably adding a level of complexity to the task via the mark-up is very difficult.
I have all respect and sympathy for the people who stick to the ideal of doing TEI, which I commend entirely. But in some cases, it may be that asking amateur people to do [the decipherment] and do the mark up is a pretty strong request, and makes a big assumption about what the people "out there" are capable of without formation.
Me: I'd agree with you. However, there have been some studies on these users' ability to produce quality transcripts outside of the TEI world.... Old Weather did a great deal of research on that, and they found that individual users tended to submit correct transcripts 97% of the time. They're doing blind triple-keying, so they're comparing people's transcripts against others. [They found] that of 1000 different entries, typically on average 13 will be wrong. Of those thirteen, three will be due to user error--so it does happen; I'm not saying people are perfect. Three will be generally[ed: genuinely] illegible. And the remaining seven will be due to the officer of the watch having written the wrong thing down and placing the ship in Afghanistan instead of in the Indian Ocean. So there are errors everywhere. [I mis-remembered the numbers here: actually it's 3 errors due to transcriber error, 10 genuinely illegible, and 3 due to error at time of inscription.]
Lou Burnard: The concept of error is a nuanced one. I would like to counter-argue Elena's [point]. I think that one of the reasons that Bentham has been successful is precisely because it's difficult material. Why do I think that? Because if you are faced with something difficult, you need something powerful to express your understanding of it. The problem with not using something as rich and semantically expressive as TEI when you're doing your transcription is that it doesn't exist! All you can do is type in the words you think it might have been, and possibly put in some arbitrary code to say, "Well, I'm not sure about that." Once you've mastered the semantics of the TEI markup--which doesn't actually take that long, if you're interested in it--now you can express yourself. Now you can communicate in a [...] satisfactory way. And I think that's why people like it.
Me: I have anecdotal, personal evidence to agree with you. In my own system (that does not use TEI), I have had users who have transcribed several pages, and then they'd get to a table in some biologist's field notes, for example, and they stop. And they say, "well, I don't know what to do here." So they're done.
Lou Burnard: The example you cite of the erroneous data in the source is a very good one, because if you've mastered TEI then you know how to express in markup: 'this is what it actually says but clearly he wasn't in Afghanistan.' And that isn't the case in any other markup system I've ever heard of.
[I welcome corrections to my transcript or the contents of the talk itself at benwbrum@gmail.com or in the comments to this post.]
Another problem with buttons is that having to use the mouse slows things down and increases the risk of RSI. Autocomplete is a better option because users don't have to take their hands off the keyboard. oXygen is particularly good at this because it only suggests tags that the schema allows at that point, and it seems to learn as I type, so often the first suggestion is the one I want.
The impression I got from the Desenclos seminar discussion is that some people see TEI markup as difficult and not worth doing while others see it as easy menial labour that students can do for not much money. Maybe that's why no-one's hiring me to do it. All my work is just transcription – partly because my clients often want databases, not full text.
John Unsworth asked a question about keyboard short-cuts during the Q&A, so it's interesting that you bring it up. I sort of dismissed the idea for difficult texts like Bentham, but on reflection–and remembering my own client users' dislike of the mouse–I think you're on to something.
I'll try to post the recording and the Q&A soon.
Losing transcribers to RSI is a potential problem that I haven't seen discussed much. I think you're right that shortcuts don't necessarily speed things up – even I sometimes have to spend a long time on reading if the hand is difficult or image quality isn't very good – but safety is as important as speed. Dragging and zooming the image is likely to be done with a mouse, so it's putting strain on the user's muscles even if they're not typing. A big problem with the right-handed keyboard and mouse combination is that you have to reach a long way for the mouse (or move the keyboard to use the mouse) and that adds a lot of unnecessary strain. I've started using a trackball with my left hand to cut out that problem. Autocomplete is also good on these grounds because you get the tags for fewer keystrokes, and there's less chance of errors, which ties into the question about how well-formed the users' XML is. On that, validate as you type is another really useful thing that oXygen does.
Something that I see changing in this realm as well is the scholarly collaboration of people (perhaps some machines) in different roles. The model of a single scholar working start to finish and generating an encoded text along the way is at best out-dated (at worst a sort of mind projection fallacy).
Instead, one can imagine transcribers who may be students or a crowd generating an OCR-type first pass of simple text with only simple implicit markup included. A more qualified team may reiterate over this and proofread for spelling and editorial conventions (expansions, corrections). Someone else may be adding scriptural citations. A machine may be parsing out parts of speech, poetic stanzas, or other bits of interesting data.
Accommodating all these users is the specific challenge for an interface, though TEI does a solid job of identifying results. As the encoded data becomes more complex, however, and structural and semantic tags refuse to settle into a clean heirarchy, I believe the OAC data philosophy will begin to win out. TEI will remain a very important standard, but as a generated document (as it already is becoming in the Leiden+ implementations), not as a directly coded text.
Full disclosure: I am a serene malcontent and have worked on the T-PEN project.
I completely agree about collaboration, Patrick — in fact that was my entire purpose in building the wiki-like editing in FromThePage. Of course in that tool (or rather on my projects using that tool) we're dealing with amateur editions, but even there we've found experts in different areas collaborating.
For example, one prolific volunteer was very enthusiastic, but uncomfortable with doing any mark-up. She produced plaintext transcripts, which I (being technical) then added link mark-up to. Other commenters and transcribers have added their expertise on tobacco agriculture at the time of the diaries, identified the diarist's neighbors, or resolved incorrect readings of the original handwriting. None of these volunteers were professional editors, but they each were able to contribute significantly to the edition.
Perhaps instead of amateur editions and scholarly editions we should be talking about community or social editions?
Regarding interface, I agree that this is a real challenge, and it's not a capability I excel at. I find it interesting that many corrections to my projects have been suggested through comments on a page, rather than actually implemented by editing the text directly. Your point about TEI's value outside the UI is often missed — I've heard scholars quoted saying "TEI? That's just data entry", which I think we'd agree is doubly wrong.
Thanks to the pointer to OAC. I heard a lot about it (and TEI) at RootsTech last week, but haven't managed to do the research I need to do.