
Last month, Ben and Sara Brumfield hosted a webinar to introduce the new spreadsheet transcription feature. The presentation, linked below in a video and embedded as slides, presents a walkthrough of the spreadsheet transcription interface, and shares how to configure and begin using the new feature. This was one of FromThePage's most-attended webinars, and it was exciting to have so many people join. You can sign up for future webinars here. Also, check out our blog post on the process of creating the spreadsheet transcription feature here.
Watch the recording of the presentation below:
Read through Ben and Sara's adapted presentation:

About a third of the people who signed up for the webinar are new to FromThePage, so we’ll start with some very quick background.
FromThePage is a system that allows users to collaborate to transcribe, translate, and edit documents. It was originally designed for documents like this -- prose text like letters, diaries, or this commonplace book of medical treatments.

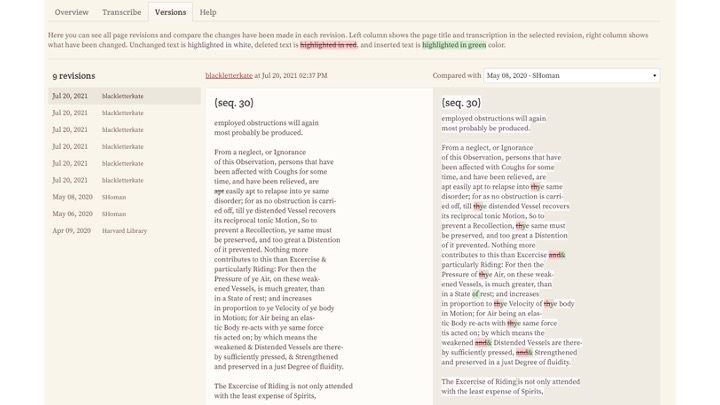
Users collaborate to edit the transcriptions, and we track all versions, so that we can see who did what. In this example, the user blackletterkate has revised an earlier transcriber’s modernizations back to the colonial original.
Thanks to support from the Council of State Archives, in 2018 we added support for field-based transcription to support pre-printed forms, like this marriage certificate from the Maryland State Archives. That allows transcription of structured data from index cards, government forms and questionnaires, but work still did not address multi-record documents.


We’d like to show off some early projects which have used the spreadsheet transcription feature to talk about the kinds of records this feature supports.
Queensland State Archives:
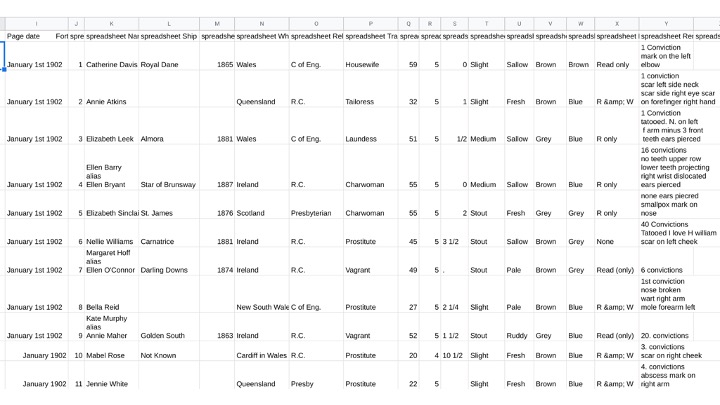
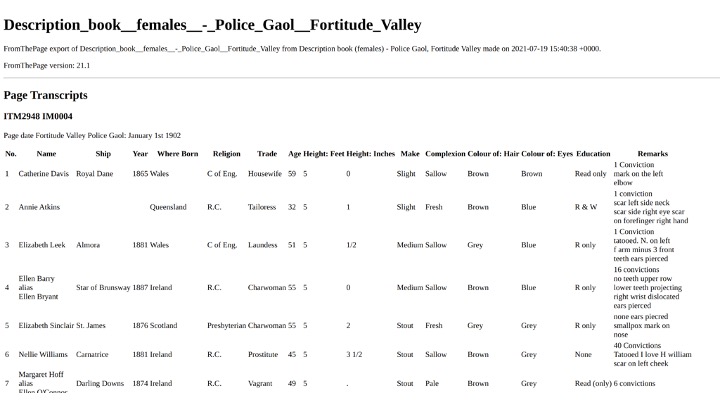
Register of female prisoners admitted - HM Prison, Fortitude Valley
Description book (females) - Police Gaol, Fortitude Valley
Missouri State Archives:
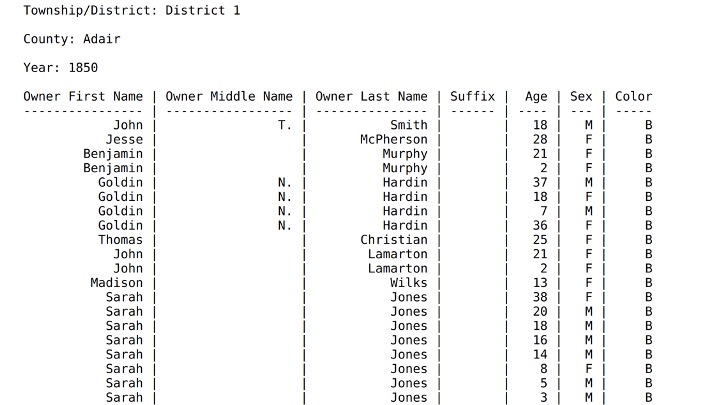
1850 Missouri Slave Census
Indiana Archives and Records Administration:
Jeffersonville Land Office Receipt Books
Camille Westmont’s Lone Rock Stockade Convict Leasing Project (Sewanee University):
Tracy City Good Time Releases
Arnold Arboretum Horticultural Library (Harvard University):
Papers of Ernest Henry Wilson -- Account Ledgers
Tennessee GenWeb is starting indexing names mentioned within newspaper articles:
TN Newspaper Indexing
Transcription Demo:

To configure these spreadsheet style projects:
In the collection settings, on the right side, look for the “Transcription Type” and select “Field Based”
This is going to look familiar if you’ve ever configured our “standard” field based configuration -- one page per record, like a World War I service card.

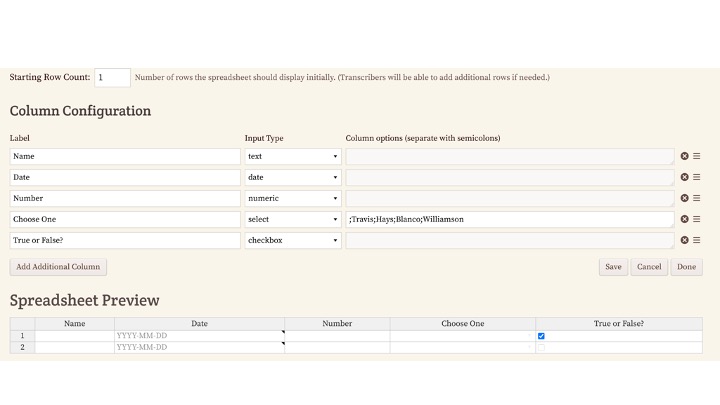
I’ve added my header fields here, a line of instruction text, and then the spreadsheet. You should put your spreadsheet on its own line, and it needs a label, which will be invisible to transcribers.
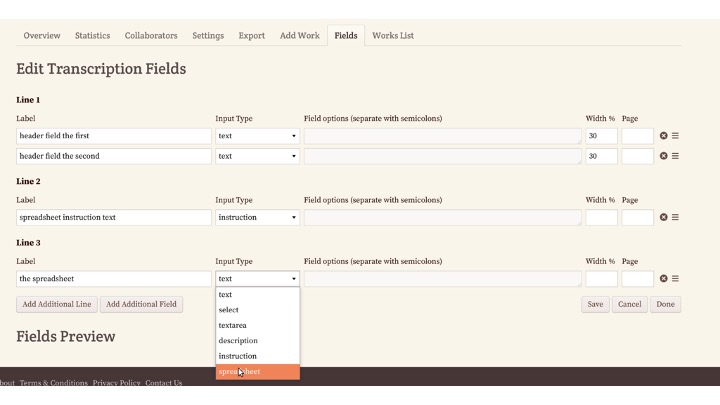
After saving this configuration, you’ll have a button to configure the spreadsheet.
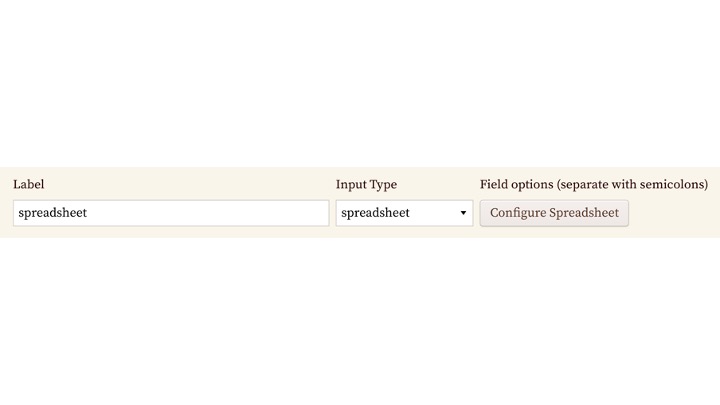
Clicking it brings you to this screen where you can enter each column you want in your spreadsheet. You’ll want the column name, the type of data -- text, date (which we’ll go into in more detail in a bit), number, a select -- which is a misnomer because it doesn’t present a drop down, but rather a controlled vocabulary that lets you tab-complete and highlights if you enter something that isn’t in the list., and a checkbox field (which we represent as true/false in the exports).
One optional feature of spreadsheet transcription is the screen ruler, which highlights the part of the image a user is transcribing. As the cursor moves to the next row in this document, the screen ruler will highlight the next portion of the image.
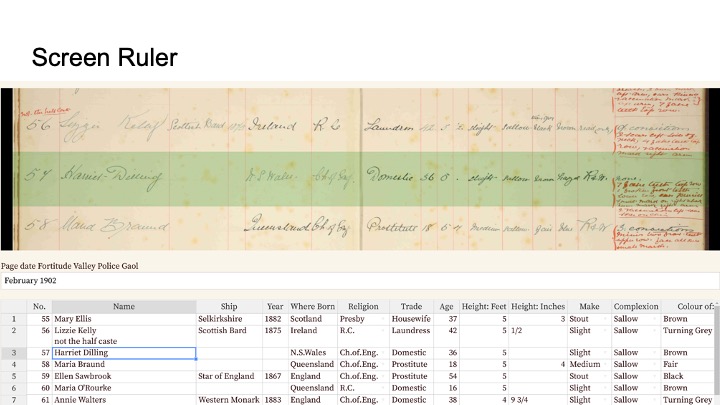

To do this correctly, we need to configure the software so that it can guess which the region of the image to highlight. Essentially, the software needs to know what portion of the image contains ledger data, and know how many rows to divide that image into.
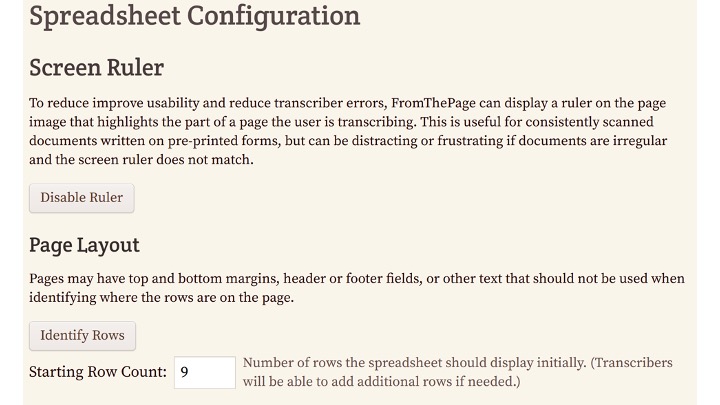
The Screen Ruler is disabled by default.

Once the ruler is enabled, you need to identify the spreadsheet rows on a sample image.
This is done by drawing a rectangle around a sample image and saving that configuration.
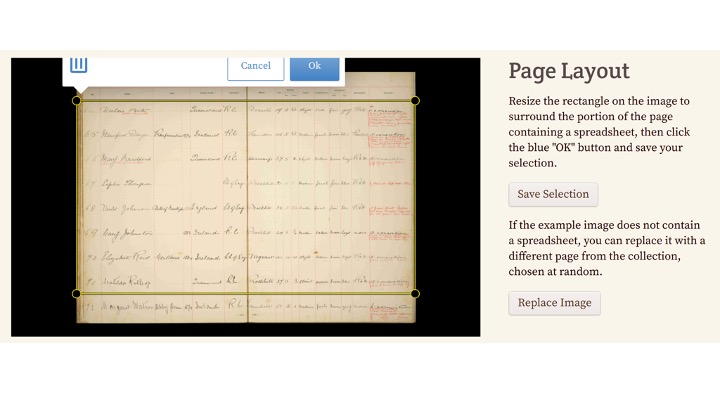
Now let’s talk about when to use the screen ruler. We need consistency in the image, which means consistent text on the paper, and consistent digitization.

Here’s the Queensland example again -- it’s a great candidate for the screen ruler because it’s pre-printed and has consistent lines. Transcribers can even work column-by-column instead of row-by-row if they like, which might save some effort as values are repeated for complexion or religion.

For documents with no ruled lines like these North Carolina troop returns, we don’t recommend the screen ruler. The text can drift downward or upwards as people write. We also don’t want to encourage column-by-column transcription, since the gaps might cause misalignments.

So you can export spreadsheets in a variety of different formats. We’re going to go into each of these

The obvious one is as a spreadsheet -- also called a “CSV”; comma separated values. Any spreadsheet application should be able to open a CSV.
Each row of data from your transcribed spreadsheet will have the transcribed data -- obviously -- but it will also have the header fields repeated on every line.
The next format is our plaintext export. Figuring out how to present spreadsheet data as plaintext was a big tricky -- we want this to be searchable when you ingest it into your various library systems, but we also wanted it to be human readable. We settled on this format, which is known as markdown. Markdown is very human readable, but it’s also machine readable and there are also tools that will turn markdown into other formats like html or back to spreadsheets. It seemed most appropriate for searching, reading, and preservation.
Our final export format is HTML. This is very stripped down HTML -- it has all the structural coding, but no styling. It’s a good starting place if you want to publish your project on a webpage, but you’ll probably want to do some editing and “pretty” it up.
Let's talk about other considerations and best practices.
Many older forms, especially from the 19th century and even older than that, will have will have information in the header and footer that applies to the entire document. Configuring the fields to capture that information is really important.
As mentioned earlier, auto-complete for controlled vocabulary will also accept input outside of the controlled fields and if necessary, will flag inputs in red.
One idea that came up -- and no one is doing this yet and we would love for someone to -- is to add a column at the end of your columns to capture notes. In our traditional text transcription, we have a section for notes and comments at the bottom of the page. These spreadsheet style documents are so dense, that that doesn't seem as useful. In existing projects, people are still leaving comments, but another possible idea is to leave a notes column to tie areas that need review to their row.
We do think that the farther you get from literary and letter transcription, and the closer you get to structured documents and government records, the more important it is to emphasize usable data. In some cases, you may end up with data that does not structurally match the document, but the goal is to have data is a usable form.
We encourage that people save often. If you have an incomplete page, save the page. If the page is complete, click Done to save and mark the page as complete and ready for review. Pressing the full screen button will give a larger screen for transcription. Also, setting the screen to over and under vs side by side transcription is a choice for both project owners and transcribers. Project owners can set a default style for their project, but transcribers can change the screen to display in the mode that works best for them.

Let's talk about dates. Dates are complicated. There are, in our opinion, three ways to represent dates, and you'll need to consider which one of these is appropriate for your project. There's a built in date format that does the same kind of red highlighting if the user input is not expected. This date format is called the Extended Date Time Format (EDTF) and it's a format that is very standard in spreadsheets and data analysis, but it's not very common outside that so it may be new to transcribers. Also, no one is going to have data like this in your historic documents. We're really excited about the possibilities of this format, and what it will let you do. Because this format can be less discrete, if your document sometimes records month and day, sometimes just month, it allows you to encode that successfully. You have the ability to support a little bit of uncertainty. It's great from the standpoint of analysis, but no 19th century clerk or 13th century scribe wrote this way, and it requires interpretation on the part of the transcribers. It may be worth it, if you have analysis or other things you plan to do downstream.
One alternative is to set dates as text and have users type what is on the page exactly as it appears. It's a very easy thing for people to do, but it is not very useable on the other side, especially because formats may not be consistent. The third alternative is to have separate columns for month, day, and year, within the date, and sometimes that even matches what's written on the form.

Let's talk about limitations. The first, configuration in FromThePage is collection-wide. In FromThePage, we have collections (which we sometimes call projects), documents, and pages. So, you are setting configurations (like spreadsheet transcription) for an entire set of documents.
Changing the configuration in the middle of a project is a challenge and is not recommended.
For reconfiguring, you can add fields to an existing project and have users circle back and transcribe those, but you can't delete fields. If you remove or rename fields, the data transcribed in the deleted or renamed columns will be lost. Also, if you do add a field to a page already marked "Done," it will still appear done. As a project owner, you can go behind the scenes and reset the page's status, but you would have to do that by hand.
This is really designed for very large projects that are dealing with tabular data.
Currently we only support one spreadsheet per page. We know that some documents have multiple spreadsheets in one page, and we anticipate being able to support that in the future.
Another limitation is that exporting takes quite some time.

Where are we going next? We're going to be enhancing our TEI-XML export to use the TEI-flavored encoding.
We would really like people to be able to request review on individual rows, instead of just the entire page.

We also want to hear from you! If you’re new to FromThePage, we invite you to try it out, either as a transcriber or by creating a trial account and configuring your own spreadsheet transcription project. Let us know if you have any questions, and how these features can work for you.