
In 2013, Ben Brumfield gave an introductory talk on crowdsourced manuscript transcription at the Perkins Library: "The Landscape of Crowdsourcing and Transcription" at Duke University.
Watch the recording of the presentation below:
Read Ben's presentation below:


I'd like to talk about what transcription is. We're all dealing with problems of, most of us are dealing with problems of digitization and the problem of computers being unable to read, essentially to OCR handwritten materials. But there's really two kinds of transcription, two kinds of activities that get labeled under the name of transcription. One of them is one that genealogists in particular but also sometimes natural scientists call indexing.

With indexing kinds of transcription, you're looking at structured data. Here we have a census entry from 1860, from a couple of counties north of here. It is structured. The goal of a transcription process is to extract names and other kinds of data from this text, and usually to create databases that are searchable. This is the kind of thing that you are going to print out and read and vet, right? This is something that you're going to want to have some sort of searchable interface to pull things out. There are a lot of interesting things you can do with this. Because the individual elements are small, you can apply fine-grain quality control to them. You can also quantify people's contributions and use that to incentivize or dis-incentivize if it's done perfectly, imperfectly for gamification.

By contrast, the editing approach to transcription is one of which you're dealing with diaries like this one, which is the one that we've been working with. This is a travel diary from 1849 from a Viscountess who was traveling around Smyrna in this case. And it's actually really an interesting narrative. It's kind of hard to extract information out of it. But on the other hand, representing the entire text is really interesting and really useful. This is the kind of thing that you'd want to print out and read in bed. You don't do quality control through computational methods, you have more of a traditional editorial workflow for creating these editions. And sometimes, you might actually want to print them out.

So if those are the two kinds of transcription activities, let's talk about the kinds of people who are doing these transcription activities. Crowd search transcription as a methodology, because it's a methodology, has really evolved independently in about six different communities, all of whom feel like they came up with the idea on their own. So let's talk about those communities and the kind of projects they're doing. So the first one I want to talk about is libraries and archives. So if you are in a library and you have invested a lot of work into producing high-quality scans of digital facsimiles, you'd face a problem, which is, "Now what?"
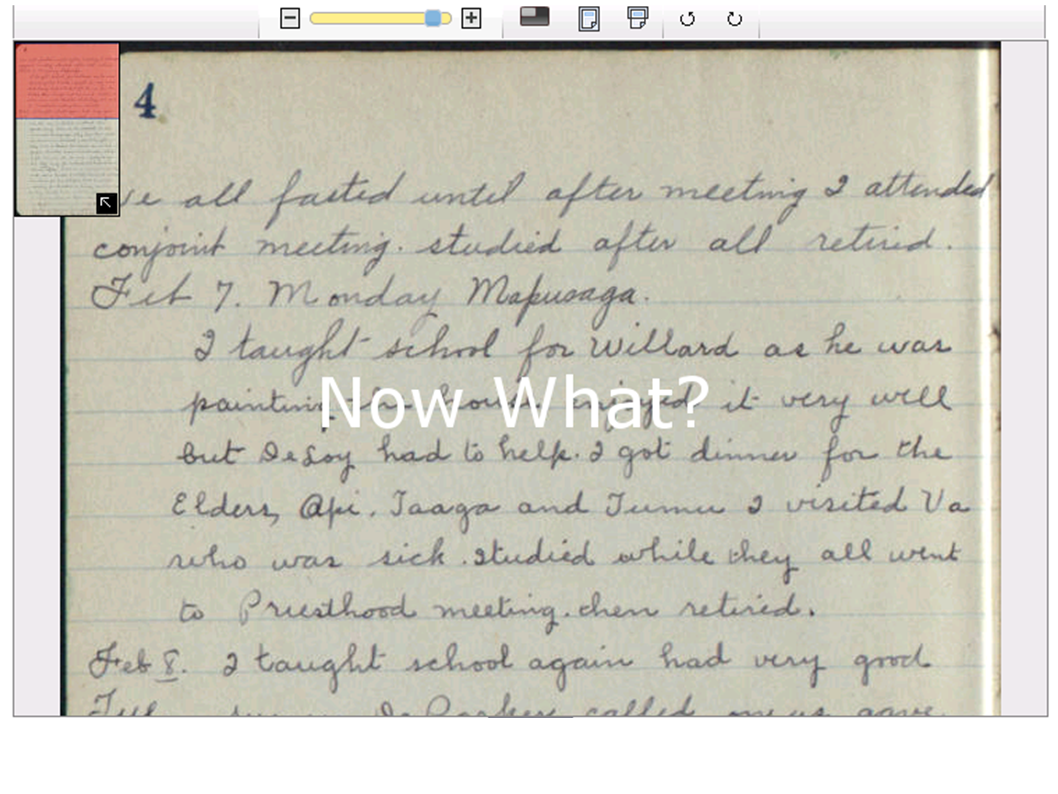
Right? The problem with this image is no one is going to read it. No one is going to find it, because Google cannot index it, because this is not text-to-Google. This is not text-to-somewhere in your institutional repository, these are pixels. And transforming that into text that can be findable means that you offer a lot more value to your patrons and you can engage with people better.

In fact right now, a transcription project I'm working on, working with my great, great grandmother's diaries, my top volunteer, the person who has done the most work this year, is someone who is unrelated to the diarist, does not live in the community, knows no one in the family. He was doing a vanity search for his name, "Matt Witting" in Google. And what are the first results? Well all the mentions of a Matt Witting in these diaries. He read a little bit more and discovered, "Hey, that's my great uncle!" The diarist's mailman. And now whenever he has a bad day at work, he goes through it, he transcribes the 1923 diary. He's just finished October this year. So I'm really excited. That's the kind of connection. This is the kind of serendipity that we get in the digital age through search engines of people making connections they wouldn't otherwise make, and they would not necessarily make through finding aids and subject headings and traditional cataloging practices. So the kind of materials that libraries' archives are working with, OCRed newspaper articles, we're not going to get into OCRed very much, hand written letters, again shooting for findability, and usually the format of your transcriptions are plain search transcripts, to be crawled by search engines to be searched by their indexes in their finding aids.
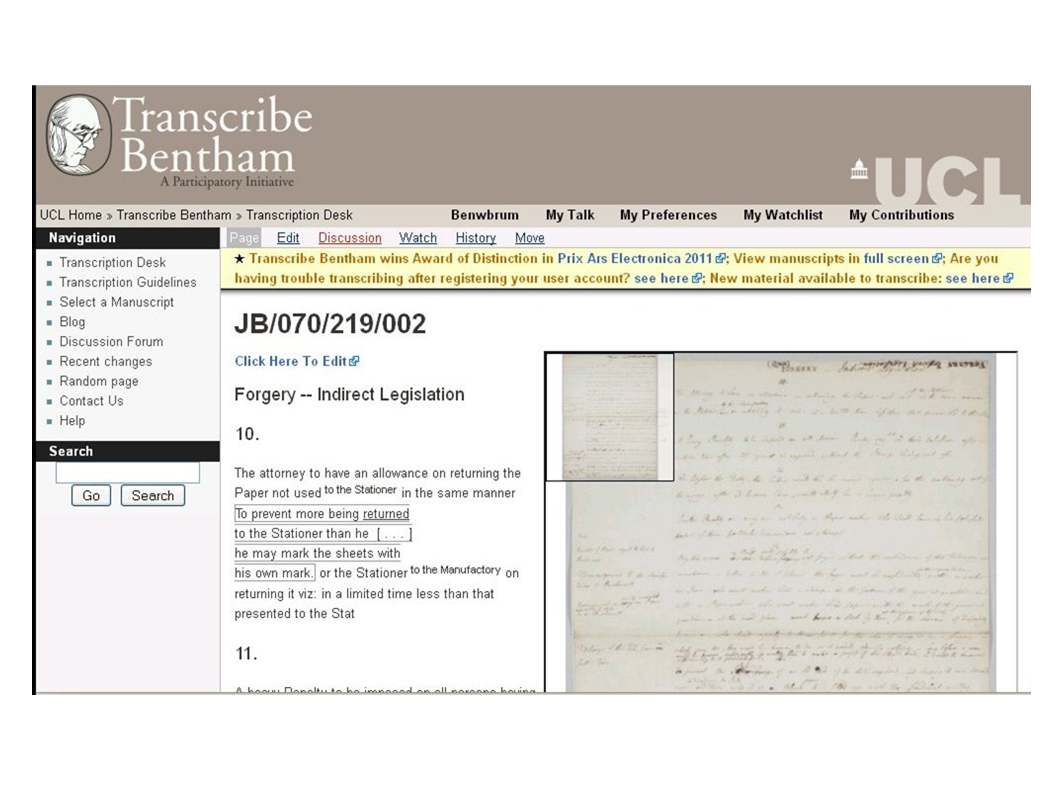
By contrast, documentary editors have also turned to crowd search transcription as a way to offload some of the burden, the initial transcription burden of this first step in the process of producing an edition. This is Transcribe Bentham, which is a project at University College London that is seeking to transcribe about 40,000 unpublished pages of Jeremy Bentham's papers. They created a media Wiki interface that has volunteers who go through and transcribe his handwriting. It's really hard to read and there's a really complex set of mark-up that they are asking their volunteers to do. To record all the changes that are made to these texts. You see there are places where he's crossed through elements, he's added elements, he's added marginalia, and they're getting their volunteers to capture all of that.

So what editors are doing the best, they are looking for high quality digital editions, which means something a little bit more than plain text transcripts. And the format that they're usually going for is TEI or some even more obscure variants of XML. Their goal, again, where these are going to live are going to be digital editions and sometimes print editions.

So, genealogists. This is a burial register from a parish in England that is being transcribed by a group called FreeReg, who I work with. They are a group of volunteers dedicated to putting the records of baptisms, marriages, and burials for England and Wales from 1538 through 1836 online, searchable, for free. They've been working on this for about 15 years now, mostly offline. Putting CD ROMs in the Royal Post. And they've entered 26 million of these. They're only about 10% done, so there's a lot more to do.

So these genealogy communities, they're again starting with handwritten records. They're again looking for findability, but they're looking for findability specifically for names and dates and places. So they're dealing with very structured data. Their goal is to produce things that can be found via their own internal search engines on their websites. So they're creating searchable databases.

If you're in the natural sciences, this is what a text looks like to you. This is an image that has been digitized from your collections. Now you want to do something with this. This is an entomology specimen from the Calbug bug project. And in order to make this thing findable, you need to record the collector name. You need to record what the specimen is. You need to record who identified it and where they found it. And then you can do interesting things, not only to increase the findability of the specimens in your collections, but you can also map the collections. You can look at a certain species and say, "Where was this species collected? Is that species still there, or has habitat destruction or climate change affected it?"

So in this case, what they're shooting for is analysis. And they're dealing with structured data, but they're dealing with visually very complex structured data. Let me tell you, the legs on an insect confuse OCR software to no end, because they look like letters. But the guesstimate is essentially museum professionals and scientists who are going to be analyzing this data and producing it in scientific journals.
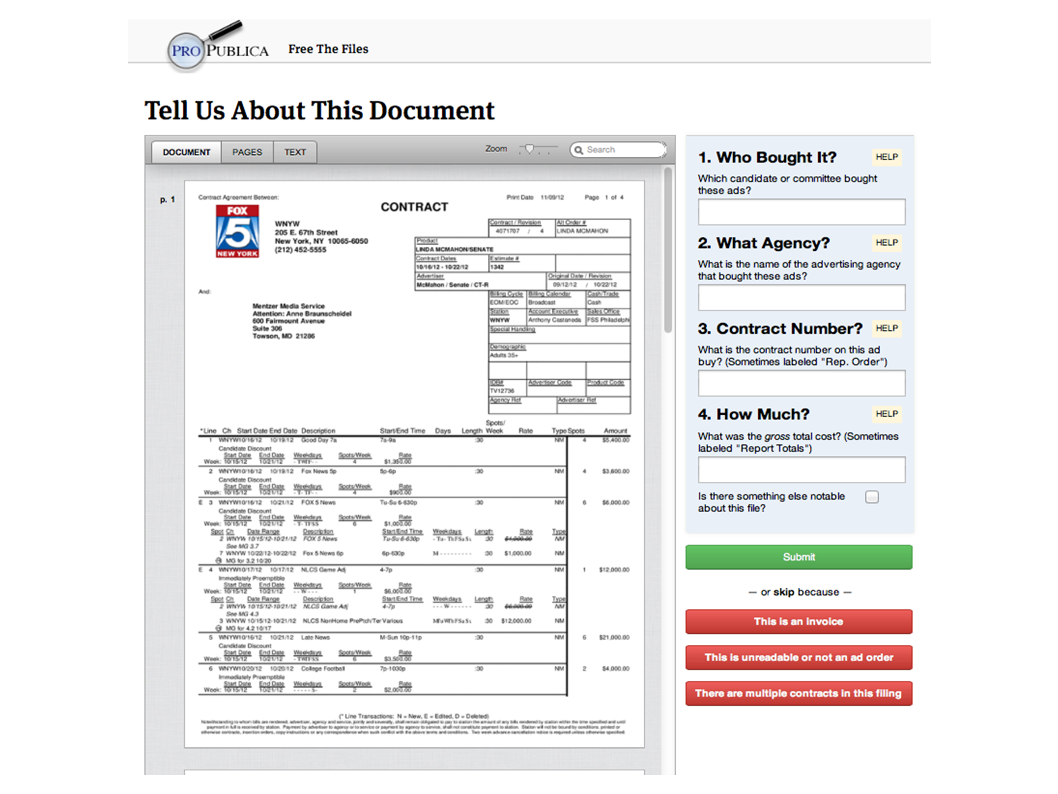
This is ProPublica, which is a use of crowdsource transcription in investigative journalism. One of the best examples of this was the MP expenses scandal in the UK about three years ago, in which it was found that a number of members of parliament were using government funds to build lines and ponds and other sorts of personal things. So they filed their equivalent of a freedom of information act request. This is The Guardian newspaper, and got millions and millions of scans of receipts. Now what? So they enlisted members of the public, activists essentially, to come online and flag these kinds of receipts. Many printed, many handwritten. This is an example of trying to track down campaign contributions and gifts in the United States. So they're looking for receipts for different kinds of things.

And the goal is to direct the attention of reporters to things that they may need to do research on, that they may want to write articles on that the public is really interested in. Again, in this case, we're dealing with structured data.

So the role of free cultures, specifically the Wikipedia world, and also to some extent Project Gutenberg, has also been working with crowdsource transcription. This is Wikisource, the journal language of Wikisource, which is a sister project to Wikipedia. It's actually an offshoot of Wikipedia that was started around 2004. And they pretty rapidly started trying to do OCR correction. Because the communities disagree with each other and have different policies, only the German language Wikipedia, oh sorry, Wikisource, started projects that allow people to transcribe manuscripts. Everyone else, because of the fear that Wikisource's credibility would be ruined and turned into a platform for pranks to publish their own materials. Everyone else required any kind of materials posted to have previously been printed on paper. But the journalists led the way. Nowadays the National Archives and Records Administration is collaborating with Wikisource and the United States to put some of their handwritten materials online and there are a number of small archives in France that are doing the same thing with the French language Wikisource.

Again, their origins are OCR because of the print aspect of this. They're looking for readability and they are doing traditional data validations. Okay. So if those are the institutions that are working with this, who are the actual volunteers who are participating in these projects?
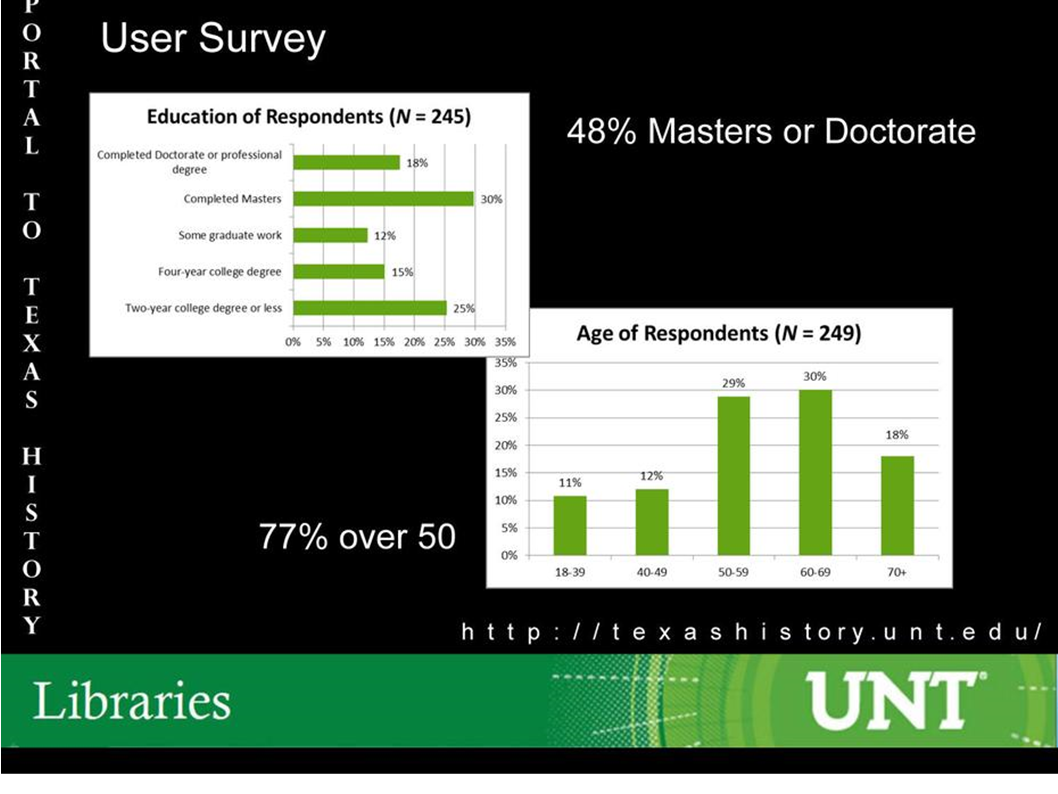
So this is an analysis that was done by the Portal of Texas History that I think is pretty representative. It certainly matches what citizen science projects have found, which is that your median volunteer on any one of these crowdsourcing projects is going to be a 60-year-old woman with a master's degree. This is the core of your volunteers. This can be kind of surprising, but it turns out that these are self-selecting samples. If you're someone who's really worried about the quality of your contributors, this is great news. If you're someone who's worried about serving traditionally underserved populations this is bad news. But this is the kind of people we're talking. There are some variations. Military history tends to draw more men, astronomy tends to draw people who are old and younger. On average, 60-year-old women with master's.
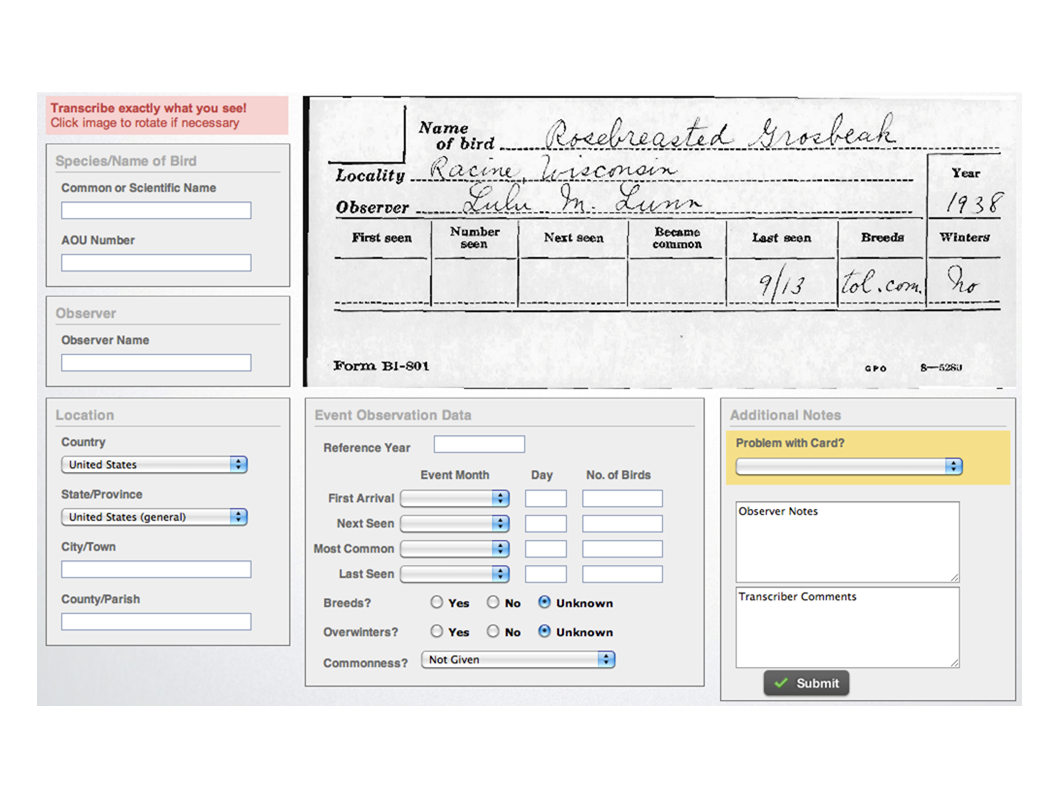
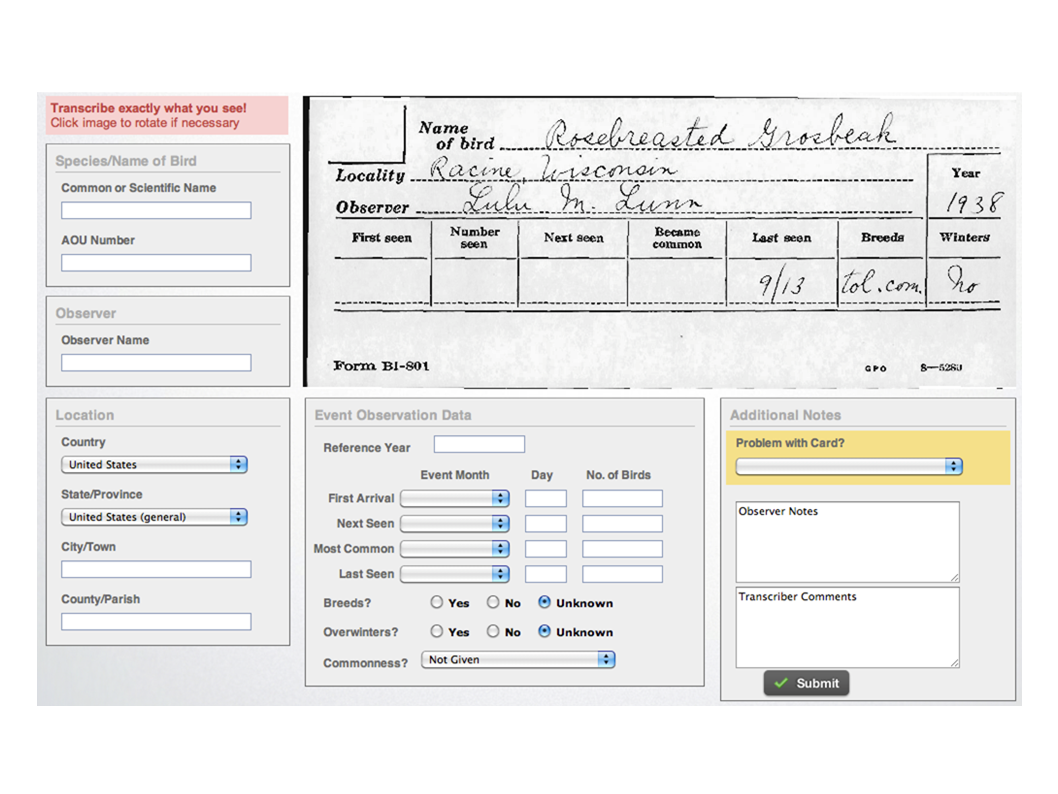
So why do they do it? So this is a project, it's one of my absolute favorite citizen science projects, which si the USGS North American Bird Phenology Program. This is a citizen science project that is digitizing the records of a 19th-century citizen science project. So from the 1870s, up until around, it kind of veers off around the 1930s. The USGS encouraged bird watchers to send their observations about individual species and individual locations to the Patuxent Bay Research Center. So nowadays, we're interested in climate change. We're interested in habitat change. Particularly interested in when do birds start their migrations? How does that compare with when they started their migrations a hundred years ago? All we have to do is transcribe two, I think, and a half million index cards that are in these filing cabinets.
So we have volunteers who are doing this and they're doing it well. Some volunteers actually have transcribed as many as 200,000 index cards on their own. It's really impressive in that they're producing some fantastic stuff.
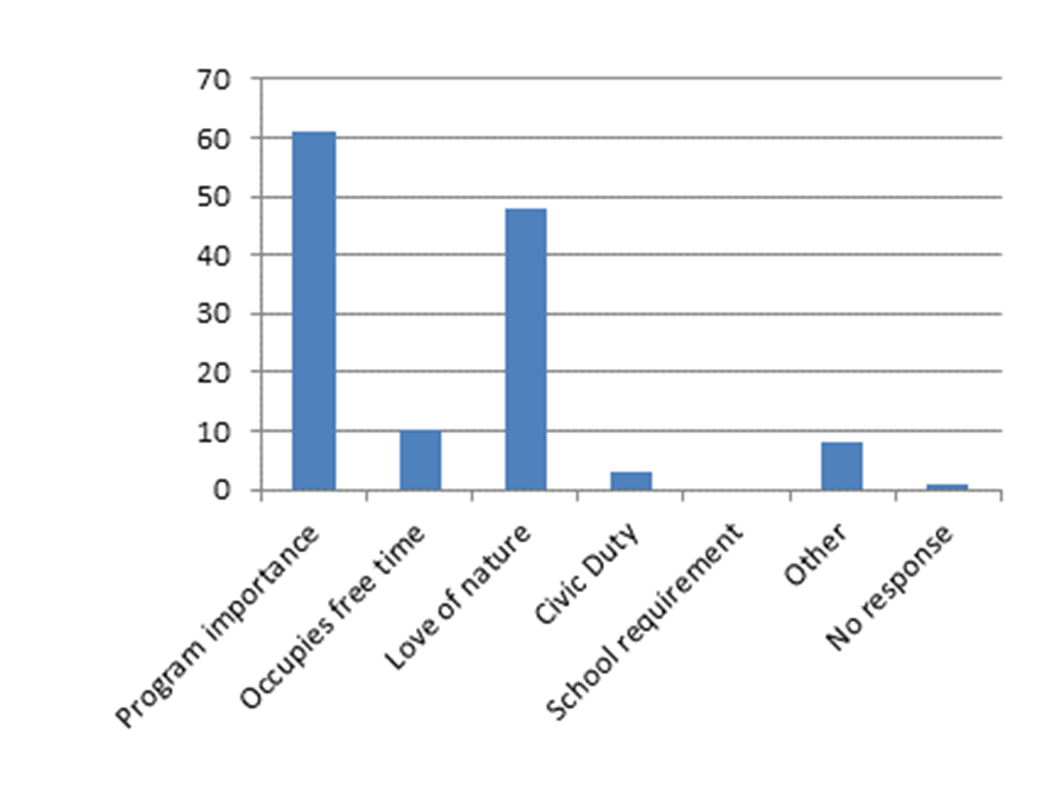
The people running this, Jessica Zelt, at the USGS, ran a survey of their volunteers saying, "Why do you participate? Why do you contribute?" So there's some really interesting things going on here. One of them is people say, "This is important." And it's true. One of the reasons people participate in these projects is because they want to do something meaningful with their lives. Especially if you're a retiree, you don't want to sit around and play games all the time. You want to do something that matters. But the other thing that's going on here is they say, "Love of nature." Why is love of nature one of the things that motivates somebody to sit in front of their computer and type up records here?
Well, this gets to the immersive nature of transcription. If you are transcribing a document, doesn't matter what it is, this is deep reading. You are reading, character by character, line by line. And when I try this, I'm not a birder. I don't know anything. I'm just interested in the tool. In fact, I've started transcribing a few of these book scraps.

I wasn't sitting in front of my computer anymore. I was with these guys. Somewhere in a march in Minnesota, typing up the results of our day's observations. And this is a lot of what's motivating people intrinsically to participate in things.
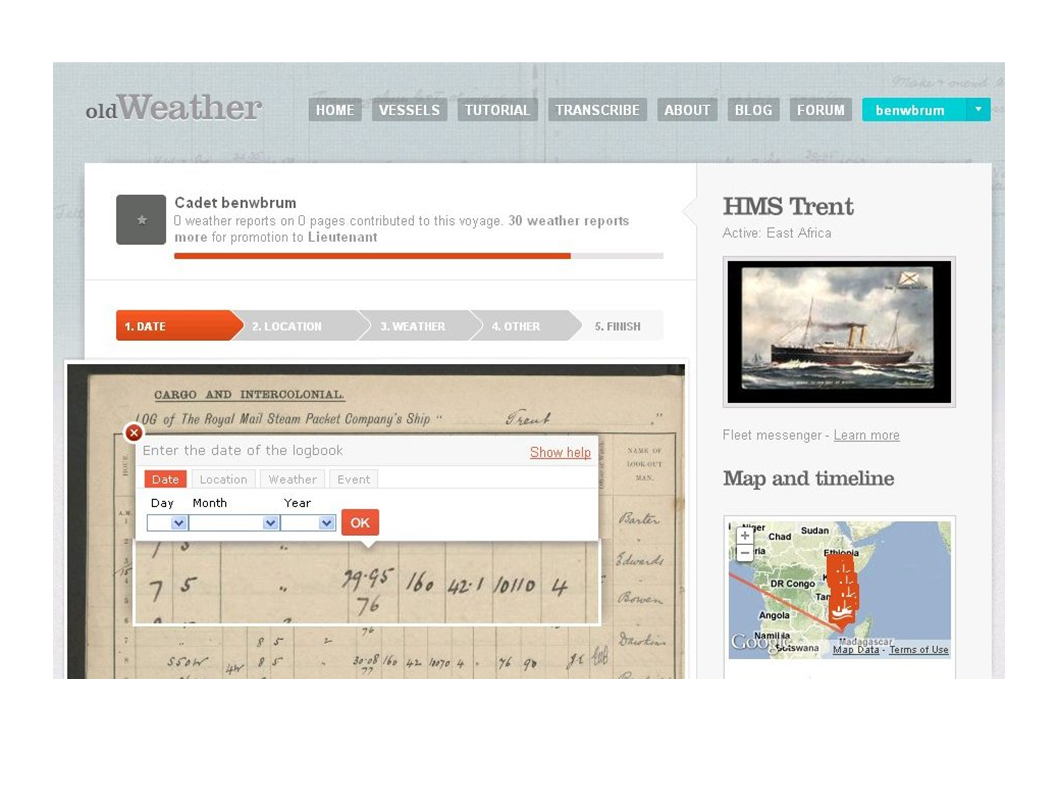
Okay. So what about accuracy? And how is the relationship of who's participating and how they're participating within this? The best studies of this have been done by the Citizen Science Alliance, the Zooniverse project. And my favorite example of their projects is one called Old Weather. Again, for scientists studying climate change, the problem isn't pointing a weather telescope at some point of the Earth's surface to find out how the climate is now. The problem is that you can't point a telescope at the South Pacific and see what the weather was like in 1914. If we want to see how the climate has changed, we have to find out what the climate used to be like. Fortunately, most of the world's Navy's, particularly the Royal Navy, has someone who every four hours, would go and make a weather observation. So the office of their watch would come out and write latitude and longitude and time of day and wind speed, wind direction, water temperature and air temperature. This is great! All we have to do is transcribe all of the weather observations of all the log books of the Royal Navy.

So they have volunteers who did this. And in fact, they've moved on to Noah's ark cruises now, because they're done with all of the Royal Navy for all of World War One. So they got through 1 to 1.6 million weather observations, with 16,000 volunteers who transcribed 400 million log pages. Which means you have a mean contribution of a hundred transcriptions per volunteer.

But that's not what actually happened! This statistic is totally worthless.

If you look at this graph, what we have over here is a plot with one pixel per contribution and one rectangle per volunteer. And if you see, most people have one pixel down here. THere's this enormous group of people who transcribed one thing and then left. But by contrast, over a tenth of the weather observations are made by these eight people alone. So they're going through and doing this, hour after hour, day after day. It's an important part of their lives. So what does that mean? So that's a power-law distribution, in which the contributions, if you graph the contributions by user, you'll see that a tiny minority make most of the contributions and the next bracket down make a fraction of those and odd.

And we have found this true regardless of project size. I have seen this happen with projects that have five volunteers. I have seen this happen with projects that have tens of thousands of volunteers. So what are the implications of this power-law distribution?

One of the things that I feel like this implies or addresses is it addresses a really common objection to crowdsourcing, which is that the crowd is not capable of doing scholarly work, or contributing to scholarly projects. They're not capable, they're not interested. But would you look at the person sitting next to you at a red light and you think, "They can't do this."? But those aren't the people you're asking. So here are some typical objections. One of my favorite examples of this was a scholar who was violently opposed to the idea of allowing volunteers to translate letters of a famous composer from German into English. All right. Well, you know classical music fans, a lot of them have pretty good command of German. That would be my perspective. But he said, "There's no way we can ask the public to to do this!" South Carolina voted for New Cambridge, because they can't do this. Well, this is a total non sequitur. That's not actually what's going on.

So what's actually going on is with these crowdsourcing projects is you're casting this net, a pretty wide net to gather a few really well-informed amateurs. These well-informed enthusiasts who love the material, they know what they're doing and they have no other institutional or organizational connection to it.

And I saw this with one of the first collaborations I did with a library. This is the Zenas Matthews diary, which is the diary of a Texas volunteer in the Mexican-American war. It is held at the special collections of the Smith Library, Southwestern University of Georgia and I was looking for this online on FromThePage. And we get the thing out in New York. And we don't actually announce it yet. So we're going back and forth and we say, "How should we craft the announcement? What should we do about help text?" And meanwhile, someone writes them and says, "Hey I'm really interested in Texas, and I'm looking for this diary from 1836."
And we're all kind of excited, and Catherine reads this and says, "Okay! 1836, right? Here it is." And he responds and says, "No, no, no, no. This is not what I'm looking for, but yeah I'll check this out." So we go back to talking about what should we do about phones and announcements and he goes through and in two weeks, he transcribes the entire 43-page diary. This diary is not in good condition.

And when he finishes transcribing, he starts doing research and adding foot notes. So these are foot notes added by Scotty Patrick, who is a retired oil field worker with a high school education outside of Houston, Texas, who's gone through and looked at the people who are mentioned in this diary and he says, "Here's this person. He goes on to become a governor. By the way, he's my cousin.

He recognizes the phonetic spelling that Zenas Matthews, this Texas volunteer had of elements that he's running into in Mexico. He says, "Oh well, this is actually a refined sugar." But he goes and he finds books that are mentioned very briefly and sends us links to them.

So in fourteen days, he transcribes the entire diary. He goes back and makes 250 revisions to the transcript, because as he becomes comfortable with the hand, he goes back to earlier pages and says, "Oh that was a 'w' angle but that means this isn't just a straight-through thing," and creates two dozen foot notes. So these really are ideal well-informed enthusiasts. It leaves us wondering what we're going to announce publicly now that he's done. But it was really an experience.
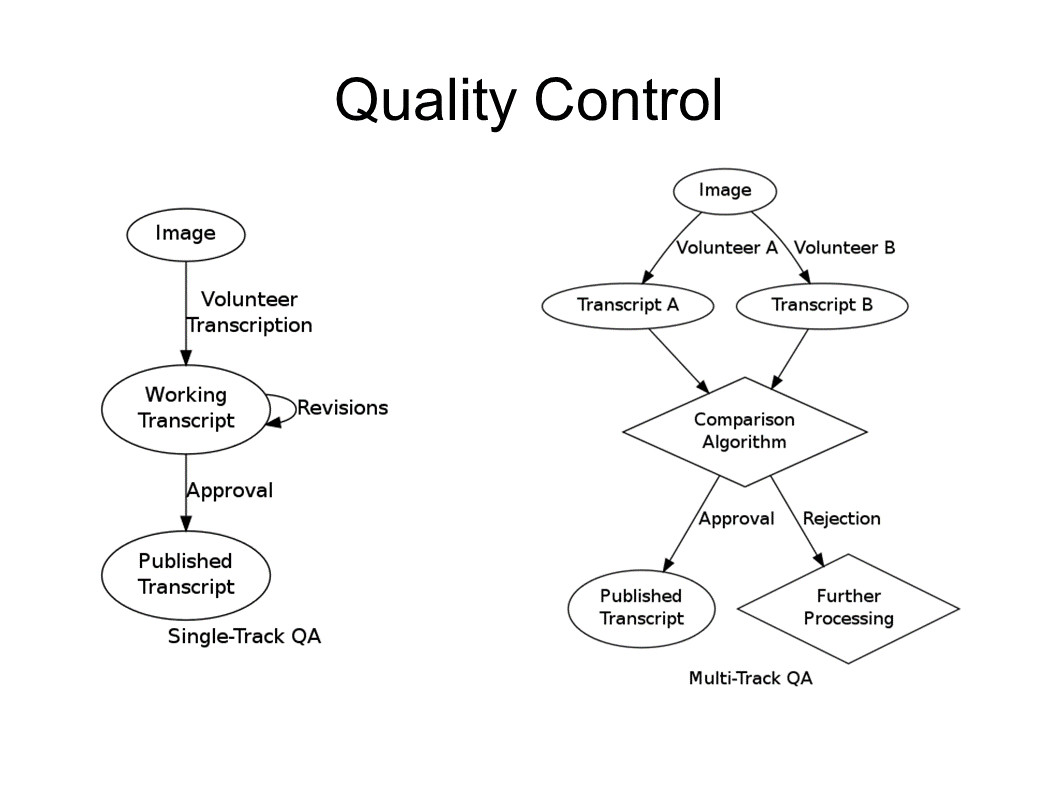
So let's talk about quality. There are really two different ways that these kinds of projects implement quality control over user contributions. And they go back to that distinction I was talking about earlier, between the editing approach and the indexed approach. Between the structured data that's highly granular and the free form data that really requires a more human approach. So I divide these into a three-way process that has a single track which is used for editing purpose. And of which, start with an image, a volunteer or a number of volunteers transcribes, produces a transcript, makes a number of revisions to that transcript and then it's approved and published in some sense.
In contrast, these other smaller projects that are happening in genealogy and citizen science have what I call a multi-track approach in which the multiple volunteers who are keying in the same information independent of each other, unaware that the other is doing this. So you may have heard multiple transcripts that are then compared against each other programmatically and either merged or reconciled or rejected. So in this case, we made two transcripts, checked to see if they're the same, because they are very simple single line elements it's easy for computers to do that without worrying about accidental purposes. And if they are the same, we can approve them. If they're not, we send them on for further processing.
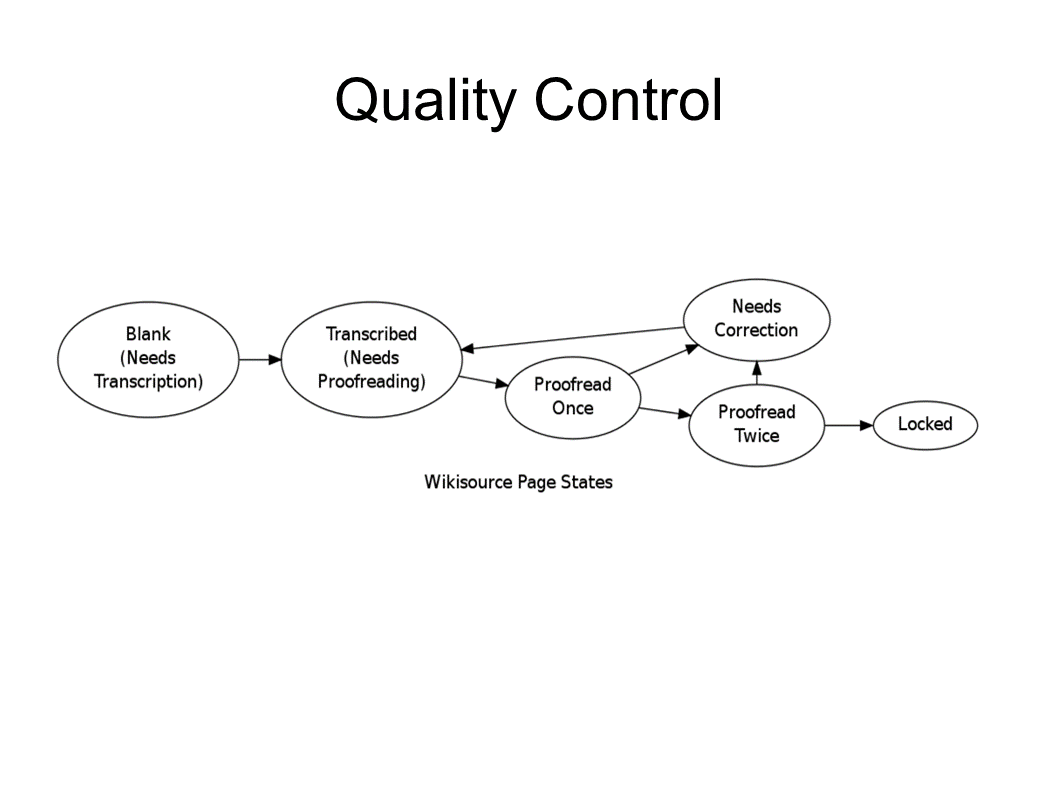
So look at some examples. Wikisource. Every page in Wikisource goes through states. They start off blank. They need a transcript. Then someone transcribes them. They grab multiple revisions. And so this work is ready to be proof read. You have a proof reader who comes in and either accepts or says, "This needs correction." Sends it back to transcribe. It's again proofread once. Second proofreader comes in and checks and either rejects it or accepts it. When every page in Wikisource of a work is locked down and proofread twice, then the whole thing is considered done.
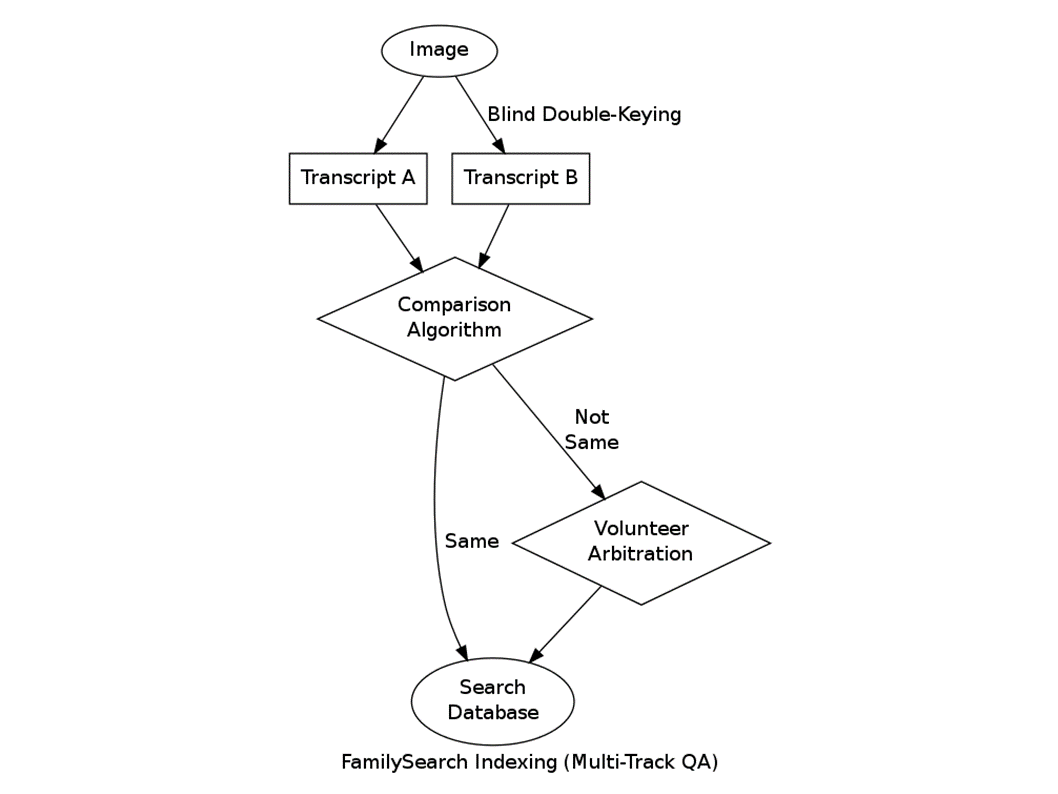
By contrast, Family Search Index, which is a genealogy program which is asking volunteers to transcribe things like census ledgers. This is the tool that was used for the 1940 census in which you had a billion records that were entered by volunteers. What they do is they present the same image to two people. Those two people produce two transcripts of the image, gain with the comparison algorithm. And then the interesting thing about this is that if the comparison algorithm says that these two things are off, meaning they're not the same, there's something funny, they're presented to someone called a reconciler who is, sorry, an arbitrator, who is another volunteer. That volunteer is presented with the original image, presented with both transcripts and then basically it is up to them to select one of them or create their own. So the interesting thing about this is how do you find these volunteer arbitrators? When you've got hundreds of thousands of volunteers, that's a lot of staff work. Well, they do this emergent system, where if you're a volunteer transcriber and you have either always typed the same thing again as another person, or you went to arbitration and won, then they say, "You're pretty good. You've got a score of this much, we're going to invite you in." And they teach classes on this, they actually have full work shop sessions for arbitrators themselves.
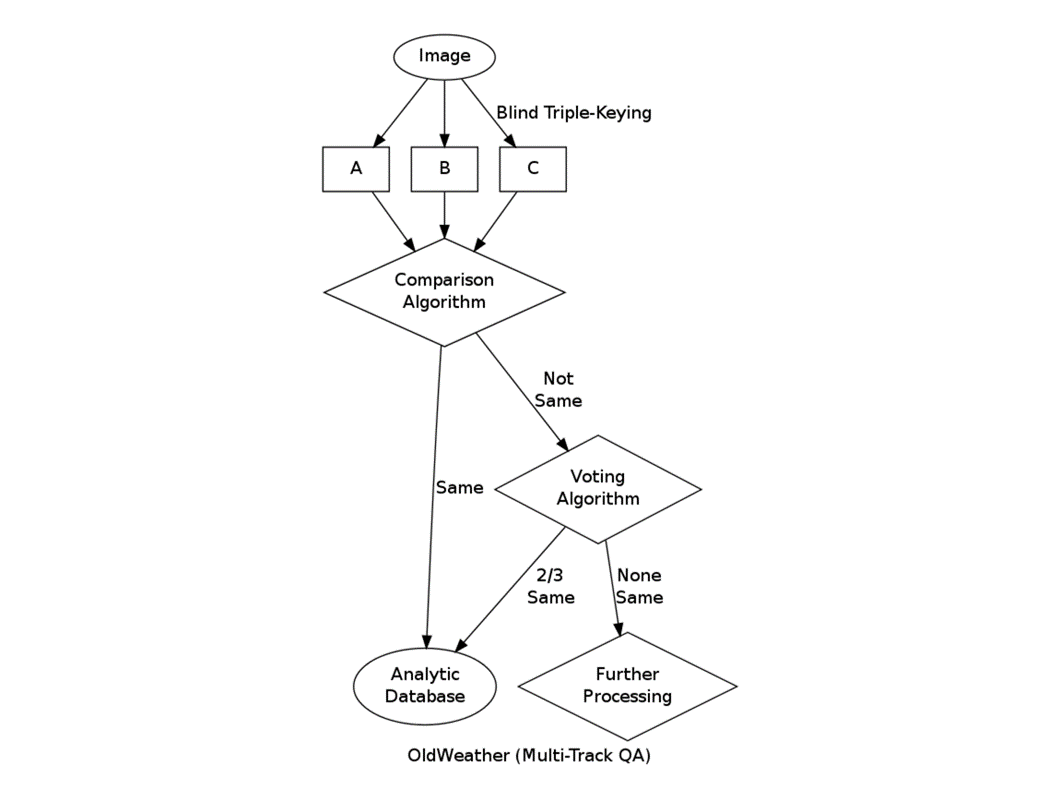
Another approach is the one taken by Old Weather. They start off with the same image and they do blind triple key. Originally, they did blind ten way key. They were getting 10 transcripts of every single weather observation. They did some math and discovered that triple key was actually just as good from a volume perspective and certainly accelerated their process. So there it makes the three copies, they present them to a comparison algorithm and they're the same, it's great. Goes under their analytical database. If they're not the same, they essentially have the three transcripts vote and if two of them match, "Yay, that one works!" If they're not the same, they all get referred to processing.
So they have an interesting side effect of this learning algorithm, which is that if you're outvoted consistently, a secret field on your user record, recording your quality, is updated. So this goes on your transcript, essentially.

So they've also run statistics on their accuracy. And I think that these are really interesting. So if you just look at the individual transcripts that are produced, about 97% of them are accurate.
That doesn't mean that the transcribers are messing up 3% of the time. In fact, the transcribers are messing up 0.3% of the time, in which there's something very clear, they typed the wrong thing. 1% of the time, the actual original observation is completely illegible. There's nothing, there's no information that could be derived from that. And the other interesting thing that I think calls into question this measure of accuracy is that just as many observations that are mistyped by the transcriber and are wrong because of that, that same number are wrong because the officer of the watch confused East and West. So they observed this when they started geo-coding and plotting all these observations of things that had passed all their arbitration and voting. They're plotting these ships and suddenly a ship ends up in the middle of Afghanistan. And all right, okay, North, South, plus, minus. And so the actual errors are the law.

Okay. So I'd like to talk about a couple of specific projects to talk about costs and results and the components of their costs. These were a couple of my favorite projects, and they're very different. One of them is a shoe string operation, the other one is a project that has extensive institutional support and a three-digit, a six-digit budget.
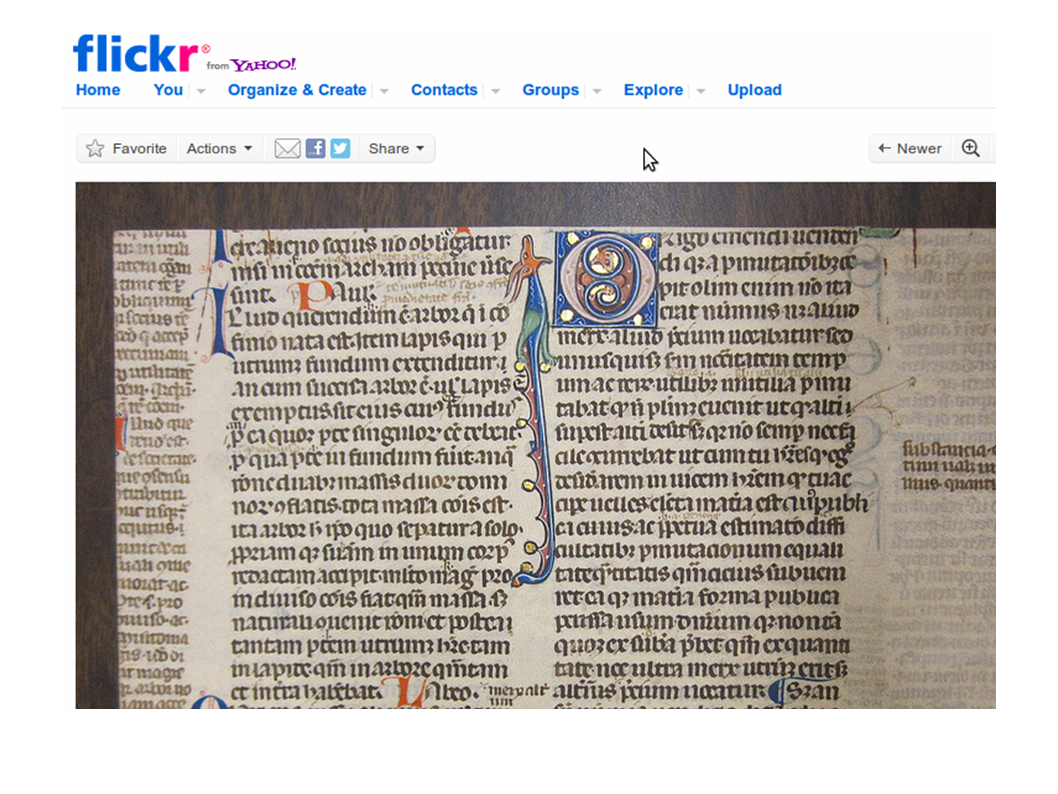
So the first one is the Harry Ransom Center of Manuscript Fragments Project. So the Ransom Center is an institution that's known for its collection of modern literature. They have a whole lot of money to do collections and sometimes they end up with books that are not modernist, old books, including books that are bound with fragments of manuscript, of medieval manuscripts that were used, just a little waste. They were sliced up and used for binding. So what they started doing, and this is specifically Micah Erwin, a junior archivist there, is that he started taking photographs of this manuscript, these manuscript fragments and posting them on Flickr and asking, "Anybody know who this is? Where this came from?"
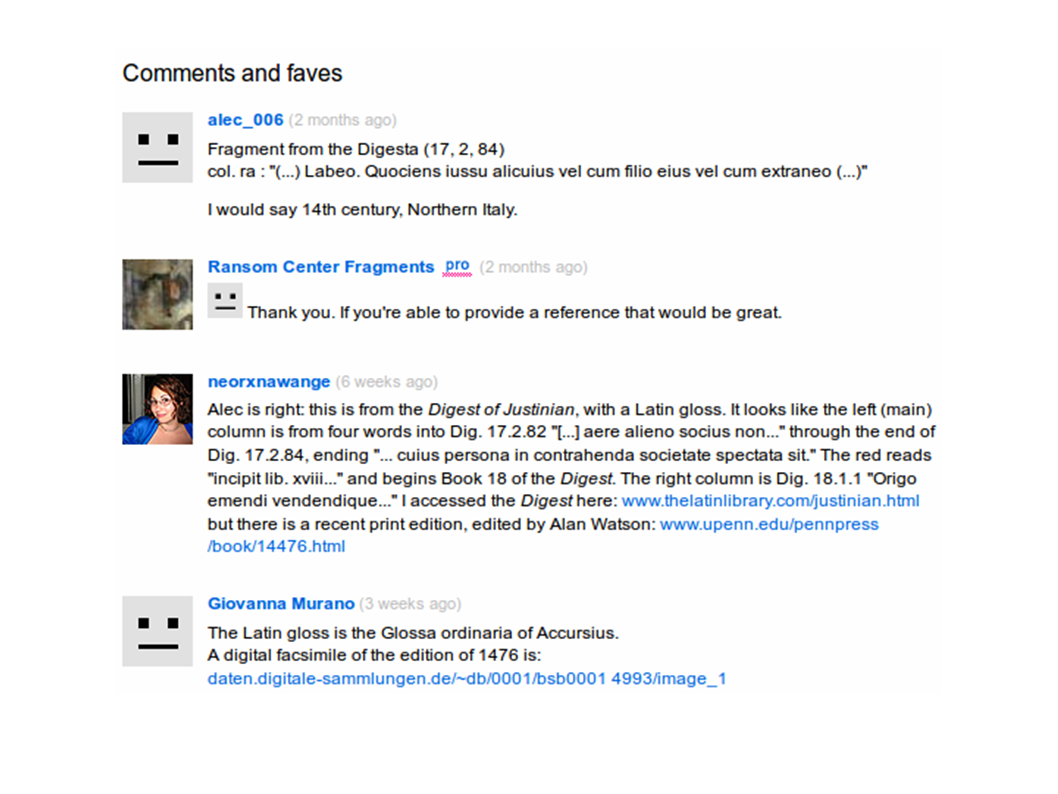
And in the comment threads, you have people who are transcribing and identifying what they are. So here you have Alec_006 who says, "Oh you know what? This is what this is. I transcribed the text, did a search and Google Books and Google Scholar, and found an edition and identified this as the fragments of Podesta." And he also says, "I think the script's probably 14th century from Italy. You have someone else who is a grad student who elaborates even more. This is pretty impressive, for a Flickr comment thread.
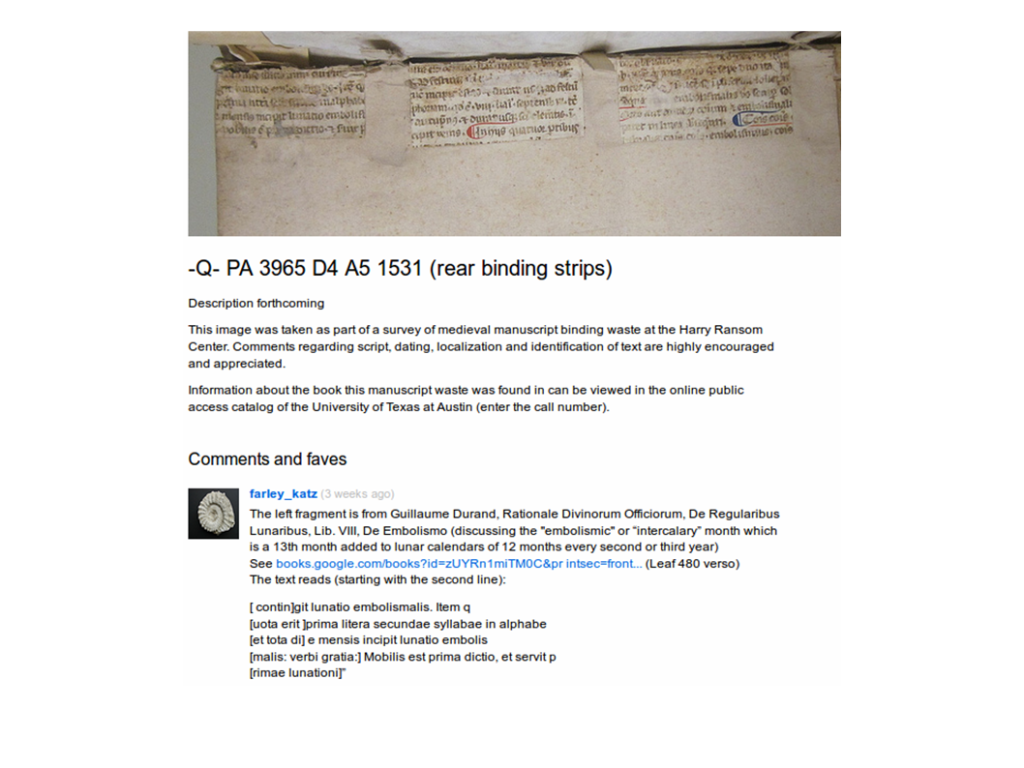
Here's another example, of which we have three fragments that are used to bind a cover onto a book. Then we have a comment by a user, who if I remember correctly is a retired rare book dealer, who describes exactly what each one of these fragments are and transcribes them as well.

So the Manuscript Fragments Project has a capital budget of nothing. All the images were taken with a camera phone, then directly uploaded to Flickr. Their software development budget was also zero. They have a Flickr account. At some point, I understand they paid the 25 bucks to convert it to a pro account, but that's all. In terms of staffing, this is really minimal. Originally, this was entirely done as a volunteer project by the archivist in his spare time. He had no institutional support. After it started getting a little bit of press, the Ransom Center said, "This is kind of cool. You could do this on the clock." But really still pretty minimal.
If you look at their results, roughly a quarter of your fragments are still unidentified, of which probably half are considered certified identifiable. They're just too small, they're too faint, they're too damaged. Volunteers identified of these, more than 50, which is really impressive. They identified them on Flickr. There's something else that's kind of interesting going on, which is that other scholars started calling in. Now they didn't participate on the Flickr message boards. They didn't comment there. But they would make phone calls into the Ransom Center and say, "Hey, I just saw you posted this thing. And in this case, they're using the same platform used for crowdsourcing, not participating in it, but using the same mechanism of distributing the challenge of identifying these things.

As a result, they've got an impressive social media presence as well as going from having no manuscript fragments described and collected in their database to most of them. So this is Micah's comment about the outreach. And I don't know what the answer is. How does outreach matter? I don't know. We don't know again. But previously, medievalists knew nothing of the Ransom Center because there's nothing for medievalists there. Now they're kind of hung up. In retrospect, they asked Micah, "What would you have done differently?" And he said that he really regretted not engaging with the volunteers more. And this gives to something that I always warn people about in crowdsourcing projects, which is that crowdsourcing is not about free labor. It is not about getting volunteers to do your work for you for nothing.

We have this saying in open source software, "Free as in beer, versus free as in speech." Crowdsourcing is really kind of free as in puppy. People will come out and they will participate and they will help you out, but they do it for their own reasons and they require some engagement with you. They don't require being paid! That's not why they're doing it, but you need to acknowledge their contributions and make sure the contributions you give them are important.

The other project I'd like to talk about is Itinera Nova, which is a project by the City Archive of Leuven Belgium that goes back to, they have registers that go back to the 1400s that basically are a record of the city court, the town hall. I saw one that was this woman was accused of selling leather in a market without a guild stamp on it. And she was sentenced to go on pilgrimage to this nearby shrine and was not to be admitted back in the city unless she has the bag, the medallion from that shrine. So that's the kind of material. It's really interesting but it's written in 15th century Dutch. So you've got the linguistic issue of Middle Dutch, you've got the other paleographic issue of this being really hard to read, and you also have some interesting text and coding issues, of editions and the regions that they want to capture.

They started this project three and a half years ago and this differs a lot from the Ransom Center project. In this case, they're doing all of the digitization. They have volunteers involved here every step. The volunteers are going through an evaluating the physical registers for conservation. They're doing some minimal conservation themselves for their past registers for professional conservation.
The volunteers are operating a $40,000 image photography system. They are capturing the images themselves. And this was after some experimentation deemed to be more cost-effective and higher quality than outsourcing the digitization. I can tell you some of the horror stories I've heard about that later. Out of those images, archival copies versus access copies are all created and reviewed by volunteers. Similarly, imaging problems are identified and so some things may need to be re-imaged. And then out of all of these, an act may span multiple pages, or there may be multiple acts of these courts on a page. They've gone through and transcribed about 12,000 of them. This has all been done with between 35 and 40 volunteers, most of whom are local, some of whom work on a web-based tool from elsewhere, but they're mostly there in the town. And they're managed by one full-time staff member and a sliver of the main archivist's time.

So what's their budget like? Their budget is pretty big. They're paying for roughly four person-years of staff time. They're paying for a professional quality bug scanner. They're paying for this transcription software and for developing a tutorial to help people learn 15th-century Dutch paleography.
They have exhibits in the town hall and they've actually sponsored conferences on the subject. But the thing to realize about many of these projects that are these sort of tip-to-tail projects is that to some extent, the money that's being spent on imaging is not necessarily part of the crowdsourcing project. It spent all this money doing work that if they just hired the editors to do it, they would've got more transcripts. Well yes, but two-thirds of the money went to making digital facsimiles. Now should that really count? And that's an interesting question.

So to wrap up, let me point you to other people who know lots about these. Mia Ridge is finishing her PhD at the Open University, and she is studying a crowdsourcing through cultural heritage, not just transcription. She and I are going to be co-teaching a class next summer at University of Maryland, just with their health program. We're working towards that. Chris Lindhoff speaks a lot. Doing web search for any of these people will find videos of which they present the details of their projects: Micah Erwin, running the Manuscript Fragments Project, Melissa Terras of Transcribe Bentham, Dominic McDevitt-Parks of Wikisource, and Paul Flemons at the University of Maitland Australia.